
国外大神超详细解读:苹果M1为什么比英特尔x86快了那么多?

新智元报道
新智元报道
来源:EETOP
编辑:SF
【新智元导读】开发者Erik Engheim 近日分享了对 M1 芯片的深入研究,探讨了苹果新处理器为何比它所取代的英特尔芯片快了那么多。
M1 不是 CPU
首先,M1 并不是一个简单的 CPU。正如苹果所解释的那样,它是一个系统级芯片,即一系列芯片都被安置在一个硅片封装中。
M1 容纳了 8 核 CPU、8 核 GPU(部分 MacBook Air 机型为 7 核)、统一内存、SSD 控制器、图像信号处理器、Secure Enclave 等大量模块。这就是我们所说的片上系统 (SoC)。

M1 是芯片上的系统,这意味着组成计算机的所有部件都放在一个硅芯片上。
英特尔和 AMD 也在单一封装中内置多个微处理器,但正如 Engheim 所描述的那样,苹果之所以有优势,是因为苹果没有像竞争对手那样专注于通用 CPU 核心,而是专注于处理专门任务的专用芯片。

计算机主板的示例。内存、CPU、显卡、IO控制器、网卡等许多组件可以连接到主板进行相互通信。
我们今天能够在一个硅芯片上放置如此多的晶体管,像英特尔和AMD这样的公司开始在一个芯片上放置多个微处理器。我们将这些芯片称为CPU核心。一个核心基本上是一个完全独立的芯片,它可以从内存中读取指令并执行计算。
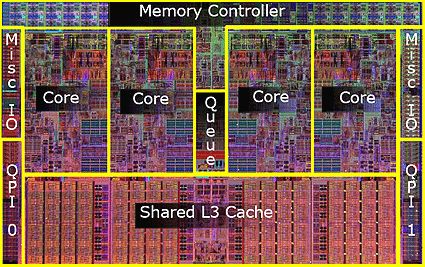
具有多个 CPU 内核的微芯片
苹果的异构计算策略并不神秘
苹果并没有增加更多的通用CPU核心,而是采取了另一种策略:他们开始增加更多的专用芯片来完成一些专门的任务。这样做的好处是,专用芯片往往能够在解决特定任务时比通用CPU核心耗电少的多,并且速度更快。
这并不是全新的知识。多年来已经有图形处理单元(GPU)等专用芯片坐在Nvidia和AMD显卡中执行与图形相关的操作,速度比通用CPU快得多。
苹果所做的只是朝着这个方向进行更彻底的转变。

M1并不只是拥有通用的核心和内存,而是包含了各种各样的专用芯片:
中央处理器 (CPU) - SoC 的 "大脑"。运行操作系统和应用程序的大部分代码。 图形处理单元 (GPU) - 处理与图形相关的任务,如可视化应用程序的用户界面和 2D/3D 游戏。 图像处理单元(ISP)--可用于加快图像处理应用所完成的普通任务。 数字信号处理器(DSP)--处理比CPU更多的数学密集型功能。包括解压音乐文件。 神经处理单元(NPU)--用于高端智能手机,以加速机器学习(AI)任务。这些任务包括语音识别和摄像头处理。 视频编码器/解码器 - 处理视频文件和格式的高能效转换。 Secure Enclave - 加密、认证和安全。 统一内存--允许CPU、GPU和其他核心快速交换信息。
这就是为什么很多人在M1 mac上进行图像和视频编辑时都看到了速度提升的部分原因。它们执行的许多任务都可以直接在特定的硬件上运行。
这就是为什么一款便宜的M1 Mac Mini可以毫不费力地为一个大的视频文件编码,而另一款昂贵的iMac虽然所有的风扇都在全速运转,但仍然跟不上。

蓝色的是多个CPU核心访问内存,绿色的是大量的GPU核心访问内存
统一内存可能会让你感到困惑。它和共享内存有什么不同?而且过去视频内存与主内存共享难道不是一个糟糕的想法,性能很差吗?
没错,共享内存确实很糟糕。原因是CPU和GPU必须轮流访问内存。共享就意味着要争夺数据总线的使用权。
基本上,GPU和CPU不得不轮流使用一个狭窄的管道来做数据交换。
但统一内存则并不是这样的。

在统一内存中,GPU核心和CPU核心可以同时访问内存。因此在这种情况下,共享内存没有开销。
另外CPU和GPU可以互相告知一些内存的位置。以前CPU必须将数据从其主内存的区域复制到GPU使用的区域。
有了统一内存,更像是在说 :"嘿,GPU先生,我有30MB的多边形数据,从内存位置2430开始"。GPU就可以开始使用该内存,而不需要做任何复制。
这意味着,通过使用相同的内存池,M1上的所有特殊的协同处理器都可以彼此快速交换信息,从而可以显著提高性能。
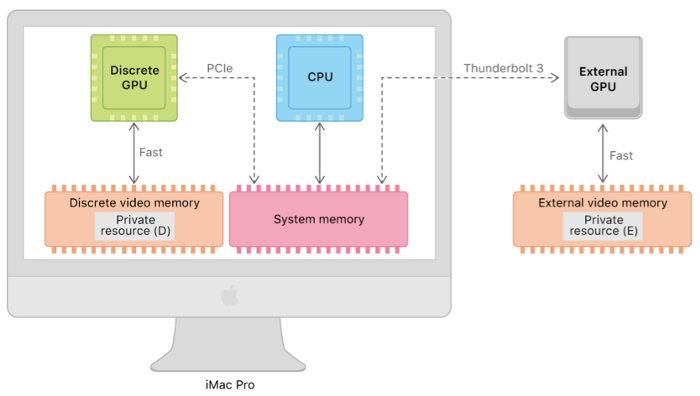
在统一内存之前,Mac是如何使用GPU的?甚至还可以选择使用Thunderbolt 3线缆将显卡安装在电脑之外。
英特尔和AMD为什么不这样做?
如果苹果所做的事情如此聪明,为什么不是每个人都这么做呢?
在某种程度上,确实如此。其他ARM芯片制造商也在越来越多地投入专用硬件。
AMD也开始在他们的一些芯片上安装更强大的GPU,并逐渐向SoC的某种形式发展,加速处理器(APU)基本上是CPU核心和GPU核心放在同一个芯片上。

AMD Ryzen加速处理单元(APU)将CPU和GPU(Radeon Vega)结合在一个硅片上。但不包含其他协处理器、IO控制器或统一内存。
然而,他们之所以不能做到这一点,有着重要的原因。
SoC本质上是一个芯片上的整机系统。这使得它更自然地适合于真正的计算机制造商,比如惠普和戴尔。
让我用一个汽车类的比喻来说明,如果你的商业模式是制造和销售汽车发动机,那么开始制造和销售整车将是一个不寻常的飞跃。
相比之下,对于ARM公司来说,这并不是一个问题。计算机制造商(如戴尔或惠普)可以简单地授权ARM IP,并购买其他芯片的IP,以增加他们认为其SoC应该具有的任何专用硬件。

接下来,他们将设计完成后的产品送到GlobalFoundries或台积电(TSMC)等半导体代工企业代工生产。
这里我们就会发现英特尔和AMD的商业模式存在很大的问题。他们的商业模式是建立在销售通用CPU的基础上的,人们只需将这些CPU插槽安装到PC主板上即可。
因此,计算机制造商可以简单地从不同的供应商那里购买主板、内存、CPU和显卡,并将它们整合成一个解决方案。
但在新的SoC世界里,你不会从不同的供应商那里组装物理元件。相反,你从不同的供应商那里组装IP。

你从不同的供应商那里购买显卡、CPU、调制解调器、IO控制器和其他东西的IP,并利用这些IP在内部设计一个SoC。然后找一个代工厂来制造这个东西。
现在你有一个很大的问题,因为无论是英特尔、AMD还是Nvidia都不会将他们的IP授权给戴尔或惠普,让他们为自己的机器制造SoC。
当然,英特尔和AMD可能会简单地开始销售整个成品SoC。但这些要包含什么呢?PC制造商可能对它们应该包含什么有不同的想法。

你可能会在英特尔、AMD、微软和PC制造商之间就应该包含什么样的专用芯片发生冲突,因为这些芯片需要软件支持。
对于苹果来说,这很简单。他们控制着整个部件。他们可以给你例如Core ML的库,让开发者写机器学习的东西。Core ML是在苹果的CPU上运行还是在神经引擎上运行,这是一个开发者不必关心的实现细节。
让任何CPU快速运行的基本挑战
所以异构计算是一部分原因,但也不是唯一原因。M1上的快速通用CPU核心,叫做Firestorm,它确实非常的的快。
这与过去的ARM CPU核心有很大的不同,过去的ARM CPU核心与AMD和Intel核心相比,往往性能非常弱。
相比之下,Firestorm击败了大多数英特尔核心,几乎击败了最快的AMD Ryzen核心。传统观点认为这是不可能发生的。

在讨论是什么使Firestorm如此快速之前,先了解一下设计更快速的CPU的核心思想到底有些什么?
原则上,你可以通过两种策略的组合来实现:
在一个序列中更快地执行更多的指令
并行执行尽可能多的指令
在80年代,这是很容易实现的。只要提高时钟频率,指令就会更快完成。不过一条指令可能需要多个时钟周期才能完成,因为它是由几个小任务组成的。
然而,今天增加时钟频率几乎是不可能的。这就是人们十多年来一直喋喋不休的“摩尔定律的终结”。
因此,它实际上现在更关心的是关于并行执行尽可能多的指令。
多核处理器还是乱序处理器?
有两种方法可以解决这个问题。一种是增加更多的CPU内核。从软件开发人员的角度来看,这就像添加线程。每个CPU核心就像一个硬件线程。由于有两个核心,CPU可以并发地执行两个独立的任务。
这些任务可以被描述为存储在内存中的两个独立的程序,也可以实际上是执行了两次的同一个程序。每个线程都需要做一些记录,比如线程当前在程序指令序列中的哪个位置。每个线程可以存储临时结果,这些结果应该分开保存。

原则上,一个处理器可以只有一个内核,运行多个线程。在这种情况下,它只需停止一个线程,并在切换到另一个线程之前存储当前的进度。后来它又切换回来。
这并不能带来多大的性能提升,只有当一个线程可能会频繁地停下来等待用户的输入、慢速网络连接的数据等时才会使用。
这些可能被称为软件线程。硬件线程意味着你有实际的额外的物理硬件,比如额外的内核,以提高速度。
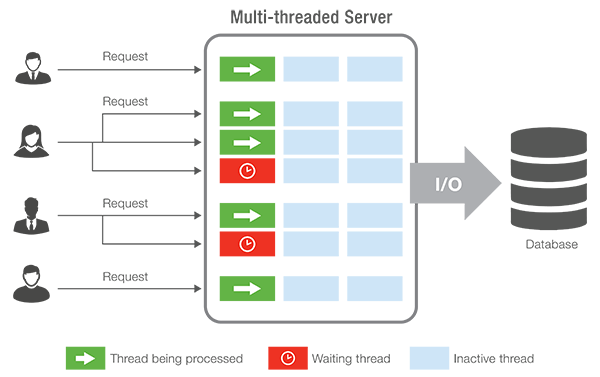
这样做的问题是,开发人员必须编写代码来利用这种优势。有些任务,如服务器软件,很容易这样编写。
你可以想象单独处理每个连接的用户。这些任务彼此独立,因此对于服务器,特别是基于云的服务,拥有大量核心是一个很好的选择。

安培Altra Max ARM CPU 128核,专为云计算设计,有很多硬件线程是一个优势
这就是为什么你会看到安培等ARM CPU厂商生产的CPU,比如Altra Max,它拥有疯狂的128个核心。这种芯片是专门为云计算而生的。
你不需要疯狂的单核性能,因为在云计算中,每瓦都要有尽可能多的线程来处理尽可能多的并发用户。
相比之下,苹果则是完全相反的一端。
苹果制造的是单用户设备。大量的线程并不是一个优势。他们的设备用于游戏、视频编辑、开发等。他们希望台式机具有更快速的响应图形和动画能力。

台式机软件一般不是为了利用大量核心而制造的。例如,电脑游戏可能会从8个核心中受益,但像128个核心这样的东西就完全是一种浪费。
相反,你会想要更少但更强大的核心。
有趣的是,乱序执行是一种并行执行更多指令的方式,但不需要将这种能力暴露为多个线程。
开发者不需要专门编写软件代码来利用它。从开发者的角度来看,它只是看起来每个核心运行得更快。

要理解这个工作原理,你需要了解一些关于内存的事情。
在一个特定的内存位置请求数据是很慢的。但是得到1个字节和得到比如说128个字节相比,在延迟上并没有区别。数据是通过我们所说的数据总线发送的。
你可以把它看成是内存和CPU不同部分之间的道路或管道,数据会被推送过去。如果数据总线足够宽,你就可以同时获得多个字节的数据。
这样CPU每次都会得到一整块指令来执行。它们被记录下来,一个接一个地被执行。现代微处理器执行的是我们所说的乱序(OoO)执行。

这意味着它们能够快速分析一个缓冲区的指令,并查看哪些指令依赖于哪些指令。请看下面的简单例子:
03: add r6, r2, 1 // r6 ← r2 + 1
乘法运算往往是一个缓慢的过程。假设它需要多个时钟周期来执行。第二条指令必须等待,因为它的计算依赖于将被放入寄存器.r1的结果。
而第3条指令并不依赖于前面指令的计算。因此,乱序处理器可以开始并行计算这条指令。
然而,更现实的情况是,我们讨论的是数百条指令。CPU能够找出这些指令之间的所有依赖关系。
它通过观察每条指令的输入来分析这些指令。输入是否依赖于一条或多条其他指令的输出?我们所说的输入和输出是指包含以前计算结果的寄存器。

如:指令依赖于输入由.产生的输入。我们可以把这些关系串联起来,形成一个复杂的长图,CPU可以通过这个图来工作。节点是指令,边是连接它们的寄存器。
CPU可以分析这样的节点图,并确定哪些指令可以并行执行,以及在执行之前需要在哪里等待多个依赖计算的结果。
很多指令会提前完成,但我们不能将它们的结果正式生效。并不能立即提交它们,否则会以错误的顺序提供结果。指令的执行顺序必须与指令发布的顺序相同。

就像一个堆栈,CPU会不断地从顶部弹出已完成的指令,直到碰到一条未完成的指令。
我们还没有完全完成这个解释,但这给了你一点线索。
基本上你可以有程序员必须知道的并行性,或那种CPU假装好像一切都是单线程。然而,在幕后它却在“乱施黑魔法”。
正是卓越的乱序执行力,让M1上的Firestorm核心大放异彩,名声大噪。事实上,它比英特尔或AMD的任何产品都要强得多。很可能比主流市场上其他任何处理器都要强。
为什么AMD和Intel的乱序执行不如M1?
在我对乱序执行(OoO)的解释中,我跳过了一些重要的细节,这一点需要说明。否则就无法理解为什么苹果走在前面,而英特尔和AMD未必能赶上。
我说过的那个大的“暂存器”实际上叫做“重新排序缓冲区”(ROB),它不包含正常的机器码指令。不是CPU从内存中取出来执行的那些,而是CPU指令集架构(ISA)中的指令。也就是我们所说的x86、ARM、PowerPC等指令。

然而在CPU内部,它的工作原理是完全不同的指令集,程序员是看不到的,我们称这些指令为微操作(micro-ops或μops)。ROB中充满了这些micro-ops。
对于CPU来说这些微操作更加实用,原因是微操作非常宽(包含很多位),可以包含各种元信息。
你不能将此类信息添加到 ARM 或 x86 指令中,因为它会:
程序二进制文件臃肿化 公开有关CPU 工作方式的详细信息(是否具有 OoO 单元)具有寄存器重命名和许多其他详细信息。 许多元信息仅在当前执行的上下文中才有意义。
你可以把它想象成写程序的时候,有一个公共的API,需要稳定的,大家都在用。也就是ARM,x86,PowerPC,MIPS等指令集。微指令基本上就是用来实现公共API的私有API。

而且微操作对于CPU来说,通常比较容易操作。
为什么这么说呢?因为它们每个都只做一个简单的有限的任务。常规的ISA指令可能会比较复杂,导致一堆东西发生,因此实际上转化为多个微操作。
对于 CISC CPU,通常别无选择,只能使用微操作,否则大型复杂的 CISC 指令将使流水线和乱序几乎不可能实现。
RISC CPU可以选择。所以例如较小的ARM CPU根本就不使用微运算。但这也意味着它们无法做到OoO等。

但你想知道这些为什么重要吗?为什么知道这些细节对理解为什么苹果在AMD和Intel上占了上风很重要?
这是因为快速运行的能力取决于于你用微操作填满ROB的速度和数量。你填满的越快,它就越大,你就有更多的机会选择你可以并行执行的指令,从而提高性能。
机器代码指令被我们称之为指令解码器,解码成微操作。如果我们有更多的解码器,我们就可以并行解码更多的指令,从而更快地填满ROB。

这就是我们看到的巨大差异。最厉害的英特尔和AMD微处理器有4个解码器,这意味着他们可以解码4条指令并行输出微操作。
但苹果有一个疯狂的 8 解码器。不仅如此,ROB的体积是它的三倍。基本上可以容纳3倍的指令。没有其他主流芯片厂商的CPU里有那么多解码器。
为什么英特尔和 AMD 无法添加更多指令解码器?
这是我们最终看到 RISC 可以“复仇”的地方,也是M1 Firestorm核心采用ARM RISC架构的事实开始变得重要的地方。
对于x86来说,一条指令可以有1-15个字节的长度。在RISC芯片上,指令的大小是固定的。为什么在这种情况下会有关系呢?
可以看到,对于x86来说,一条指令的长度可以是1-15字节。而在RISC芯片上,指令的大小是固定的。为什么这与本案相关?

因为如果每条指令都有相同的长度,那么将一个字节流分割成指令并行地输入8个不同的解码器就变得简单多了!
但是,在 x86 CPU 上,解码器不知道下一个指令从哪儿开始的。它必须实际分析每个指令,才能看到它有多长。
英特尔和AMD采用“粗暴”的方式来处理这个问题,首先它会简单地尝试在每一个可能的起点对指令进行解码。这意味着我们必须处理大量的错误猜测和错误,而这些猜测和错误必须被丢弃。
这就造成了一个错综复杂的解码器阶段,以至于很难再增加更多的解码器。但对于苹果来说,不断增加更多的解码器是很简单的。

事实上增加更多的数量会导致很多其他问题,按照AMD自己的说法,4个解码器基本上是他们能做到的上限。
这也是M1 Firestorm核心在同样的时钟频率下,处理的指令数量基本上是AMD和Intel CPU两倍的原因。
有人可以反驳说,CISC指令会变成更多的微操作,它们的密度更高,所以例如解码一条x86指令更类似于解码两条ARM指令。
只是现实中并非如此。高度优化的x86代码很少使用复杂的CISC指令。在某些方面它有RISC的味道。
但这对英特尔或AMD没有任何帮助,因为即使那些15字节长的指令很少,也必须让解码器来处理它们。这就产生了复杂性,阻碍了AMD和Intel增加更多的解码器。
但 Amds Zen3 核心仍然更快, 对吗?
据我所知,最新的AMD CPU内核在性能测试中,被称为Zen3的内核比Firestorm内核稍微快一些。但这里的关键是,这只是因为Zen3核心的时钟频率为5GHz,而Firestorm核心的时钟频率为3.2GHz。
尽管Zen3的时钟频率比Firestorm高出近60%,但也只是勉强强过了Firestorm。

那么为什么苹果不增加时钟频率呢?因为更高的时钟频率会使芯片更热。这是苹果的关键卖点之一。与英特尔和AMD的产品不同,他们的电脑几乎不需要风扇。
从本质上说,人们可以说Firestorm内核确实优于Zen3内核。Zen3只是消耗更多功耗,才得以为此更高的性能。
未来
AMD和英特尔似乎在两方面把自己逼到了绝境:
他们没有一个业务模型,使得追求异构计算和SoC设计变得容易。 他们的遗留x86 CISC指令集又回来困扰他们,使其难以提高OoO性能。
这并不意味着游戏结束。它们当然可以简单地增加时钟频率,使用更多的冷却,增加更多的核心,增强CPU缓存等等。但这些都处于劣势。
英特尔处于最糟糕的情况下,因为他们的核心已经被Firestorm彻底打败了,而且他们有GPU也很弱。
添加更多核心的问题是,对于典型的桌面工作负载,过多的核心性能提升并不明显。当然,大量的核心对于服务器来说还是非常有效的。
幸运的是,对于AMD和英特尔来说,苹果并不在市场上销售他们的芯片。所以PC用户将不得不忍受他们提供的任何东西。
原文:
https://erik-engheim.medium.com/why-is-apples-m1-chip-so-fast-3262b158cba2

