
天池项目总结,特征工程了解一下!
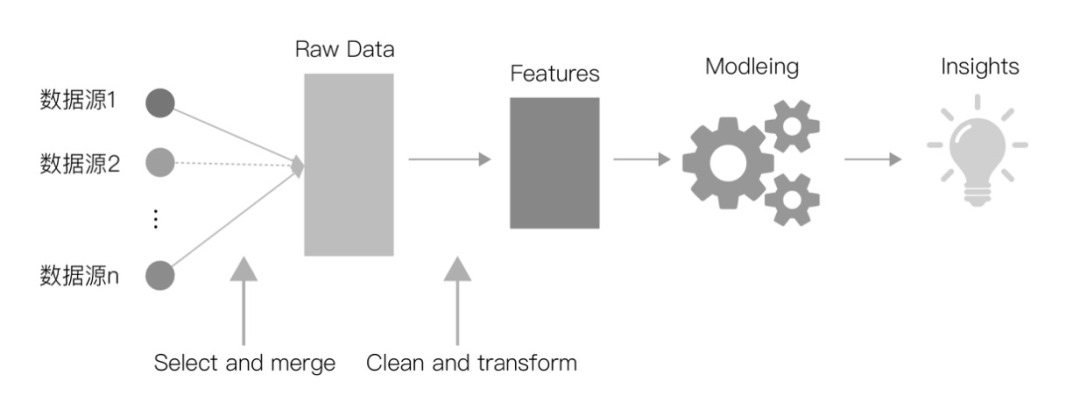
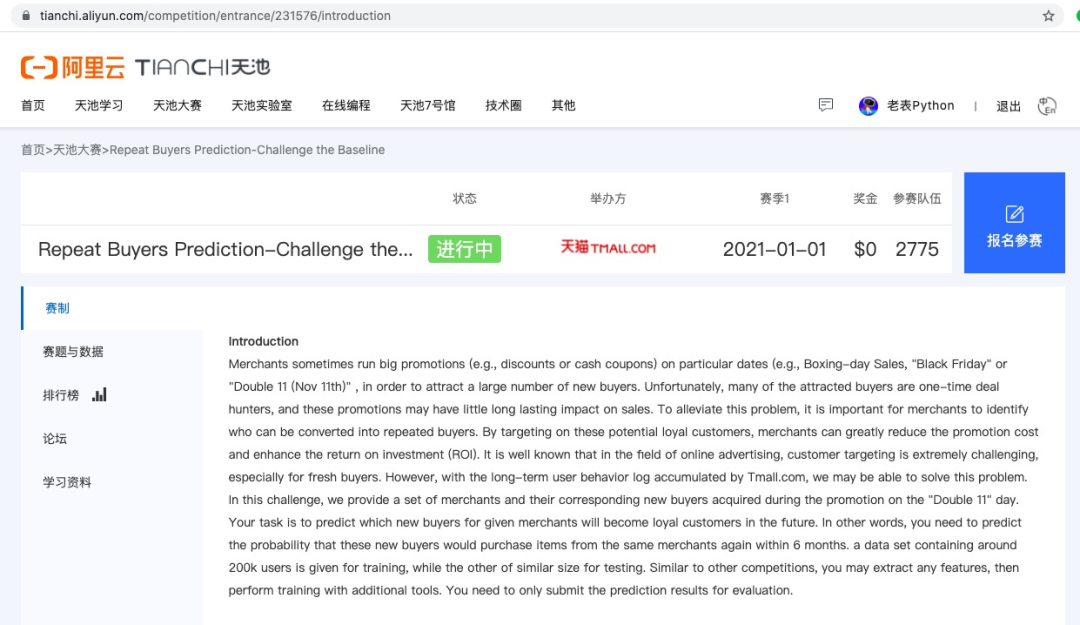
业界广泛流传着这样一句话:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,由此可见特征工程在机器学习中的重要性,今天我们将通过《阿里云天池大赛赛题解析——机器学习篇》中的【天猫用户重复购买预测】案例来深入解析特征工程在实际商业场景中的应用。
今日福利:评论区留言送书
学习前须知
(1)本文特征工程讲解部分参考自图书《阿里云天池大赛赛题解析——机器学习篇》中的第二个赛题:天猫用户重复购买预测。
(2)本文相关数据可以在阿里云天池竞赛平台下载,数据地址:
https://tianchi.aliyun.com/competition/entrance/231576/information
一 数据集介绍
按照上面方法下载好数据集后,我们来看看具体数据含义。
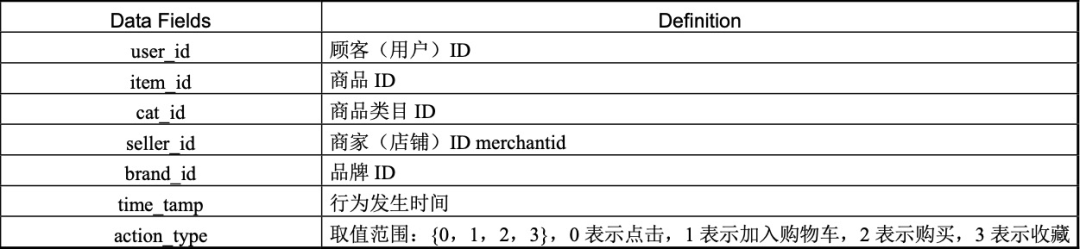
test_format1.csv和train_format1.csv里分别存放着测试数据和训练数据,测试数据集最后一个字段为prob,表示测试结果,训练数据集最后一个字段为label,训练数据各字段信息如下图所示:

训练数据集
user_log_format1.csv里存放着用户行为日志,字段信息如下图所示:
用户行为日志数据
user_info_format1.csv里存放着用户行基本信息,字段信息如下图所示:

用户基本信息数据
二 特征构造
本赛题基于天猫电商数据,主要关心用户、店铺和商家这三个实体,所以特征构造上也以用户、店铺和商家为核心,可以分为以下几部分:
 用户-店铺特征构造
用户-店铺特征构造
 店铺特征构造
店铺特征构造
对店铺特征选取可以使用,如 Numpy 的 corrcoef(x,y)函数计算相关系数,保留相关系数小于0.9 的特征组合,具体内容如图 2-3。

商家特征选取

用户特征构造
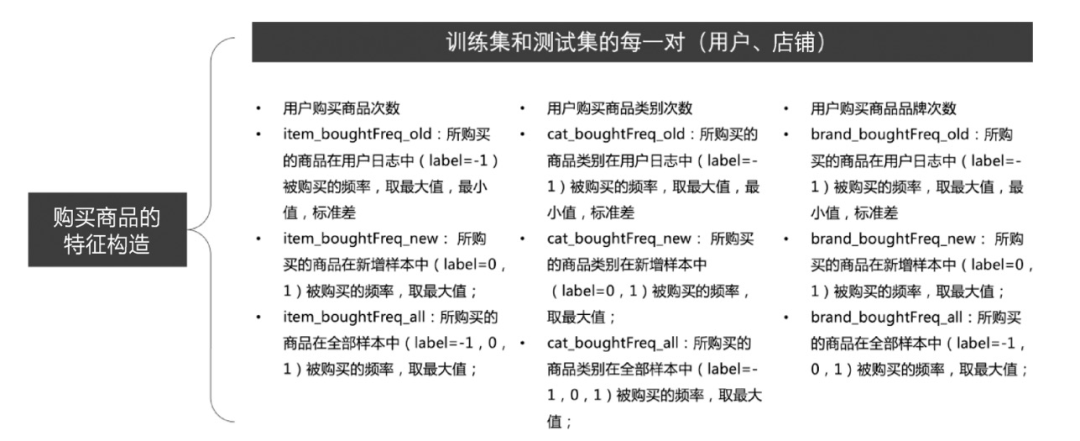
用户购买商品特征构造

利用时间提取特征
总结以上内容,特征主要基于基础特征、用户特征、店铺特征、用户+店铺四个方面,如下图所示:
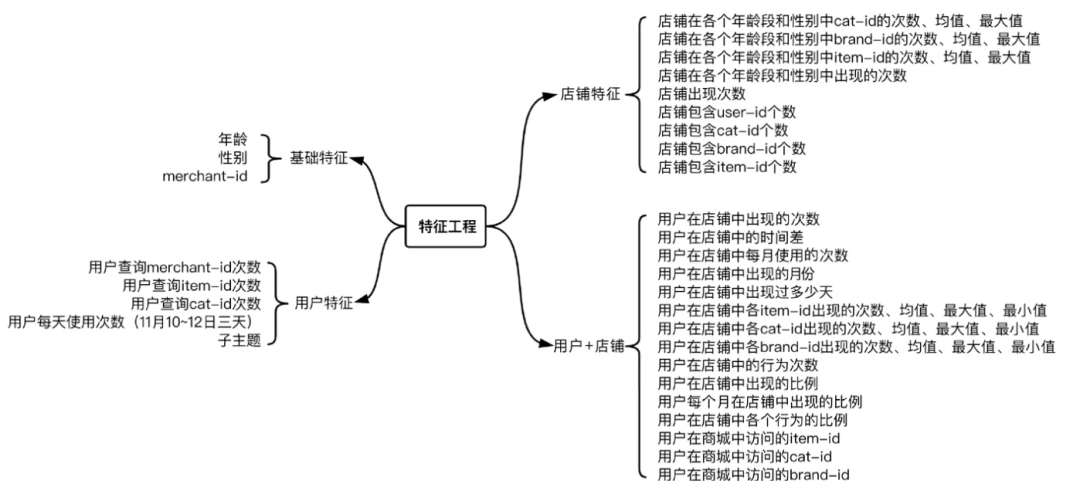
特征总结
三 特征提取
首先我们导入需要的工具包,进行数据分析和特征提取。
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt import seaborn as snsfrom scipy import statsimport gcfrom collections import Counter import copyimport warnings warnings.filterwarnings("ignore")%matplotlib inline
接下来我们将按以下步骤进行特征提取。
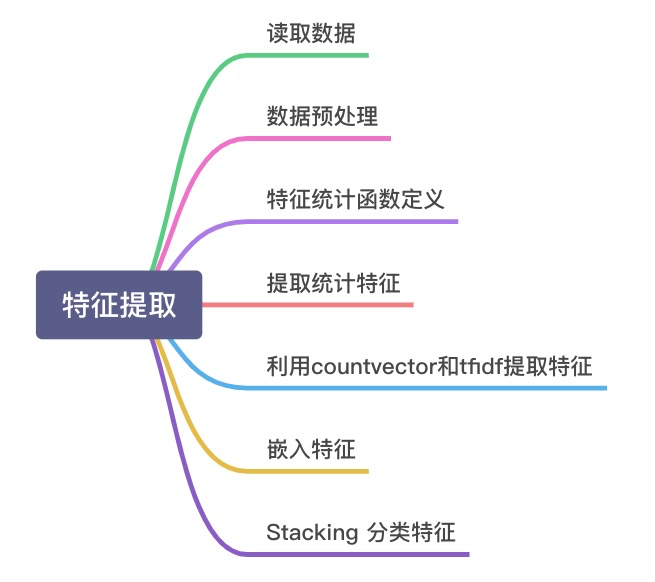
特征提取步骤
1 读取数据
直接调用Pandas的read_csv函数读取训练集和测试集及用户信息、用户日志数据。
test_data = pd.read_csv('./data_format1/test_format1.csv') train_data = pd.read_csv('./data_format1/train_format1.csv')user_info = pd.read_csv('./data_format1/user_info_format1.csv')user_log = pd.read_csv('./data_format1/user_log_format1.csv')
2 数据预处理
对数据内存进行压缩:
def reduce_mem_usage(df, verbose=True):start_mem = df.memory_usage().sum() / 1024**2numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']for col in df.columns: col_type = df[col].dtypes if col_type in numerics:c_min = df[col].min()c_max = df[col].max()if str(col_type)[:3] == 'int':if c_min > np.iinfo(np.int8).min and c_max < np.iinfo( np.int8).max:df[col] = df[col].astype(np.int8)elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:df[col] = df[col].astype(np.int16)elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo( np.int32).max:df[col] = df[col].astype(np.int32)elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:df[col] = df[col].astype(np.int64)else:if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:df[col] = df[col].astype(np.float16)elif c_min > np.finfo(np.float32).min and c_max < np.finfo( np.float32).max:df[col] = df[col].astype(np.float32)else:df[col] = df[col].astype(np.float64)end_mem = df.memory_usage().sum() / 1024**2print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
all_data = train_data.append(test_data)all_data = all_data.merge(user_info,on=['user_id'],how='left')del train_data, test_data, user_infogc.collect()
# 用户日志数据按时间排序user_log = user_log.sort_values(['user_id', 'time_stamp'])# 合并用户日志数据各字段,新字段名为item_idlist_join_func = lambda x: " ".join([str(i) for i in x])agg_dict = {'item_id': list_join_func,'cat_id': list_join_func,'seller_id': list_join_func,'brand_id': list_join_func,'time_stamp': list_join_func,'action_type': list_join_func}rename_dict = {'item_id': 'item_path','cat_id': 'cat_path','seller_id': 'seller_path','brand_id': 'brand_path','time_stamp': 'time_stamp_path','action_type': 'action_type_path'}def merge_list(df_ID, join_columns, df_data, agg_dict, rename_dict):df_data = df_data.groupby(join_columns).agg(agg_dict).reset_index().rename(columns=rename_dict)df_ID = df_ID.merge(df_data, on=join_columns, how="left")return df_IDall_data = merge_list(all_data, 'user_id', user_log, agg_dict, rename_dict)del user_loggc.collect()
def cnt_(x):try:return len(x.split(' '))except:return -1def nunique_(x):try:return len(set(x.split(' ')))except:return -1def max_(x):try:return np.max([float(i) for i in x.split(' ')])except:return -1def min_(x):try:return np.min([float(i) for i in x.split(' ')])except:return -1def std_(x):try:return np.std([float(i) for i in x.split(' ')])except:return -1def most_n(x, n):try:return Counter(x.split(' ')).most_common(n)[n-1][0]except:return -1def most_n_cnt(x, n):try:return Counter(x.split(' ')).most_common(n)[n-1][1]except:return -1
def user_cnt(df_data, single_col, name):df_data[name] = df_data[single_col].apply(cnt_)return df_datadef user_nunique(df_data, single_col, name):df_data[name] = df_data[single_col].apply(nunique_)return df_datadef user_max(df_data, single_col, name):df_data[name] = df_data[single_col].apply(max_)return df_datadef user_min(df_data, single_col, name):df_data[name] = df_data[single_col].apply(min_)return df_datadef user_std(df_data, single_col, name):df_data[name] = df_data[single_col].apply(std_)return df_datadef user_most_n(df_data, single_col, name, n=1):func = lambda x: most_n(x, n)df_data[name] = df_data[single_col].apply(func)return df_datadef user_most_n_cnt(df_data, single_col, name, n=1):func = lambda x: most_n_cnt(x, n)df_data[name] = df_data[single_col].apply(func)return df_data
# 取2000条数据举例all_data_test = all_data.head(2000)# 总次数all_data_test = user_cnt(all_data_test, 'seller_path', 'user_cnt')# 不同店铺个数all_data_test = user_nunique(all_data_test, 'seller_path', 'seller_nunique ')# 不同品类个数all_data_test = user_nunique(all_data_test, 'cat_path', 'cat_nunique')# 不同品牌个数all_data_test = user_nunique(all_data_test, 'brand_path','brand_nunique')# 不同商品个数all_data_test = user_nunique(all_data_test, 'item_path', 'item_nunique')# 活跃天数all_data_test = user_nunique(all_data_test, 'time_stamp_path','time_stamp _nunique')# 不同用户行为种数all_data_test = user_nunique(all_data_test, 'action_type_path','action_ty pe_nunique')
# 用户最喜欢的店铺all_data_test = user_most_n(all_data_test, 'seller_path', 'seller_most_1', n=1)# 最喜欢的类目all_data_test = user_most_n(all_data_test, 'cat_path', 'cat_most_1', n=1)# 最喜欢的品牌all_data_test = user_most_n(all_data_test, 'brand_path', 'brand_most_1', n= 1)# 最常见的行为动作all_data_test = user_most_n(all_data_test, 'action_type_path', 'action_type _1', n=1)
from sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.feature_extraction.text import ENGLISH_STOP_WORDSfrom scipy import sparsetfidfVec = TfidfVectorizer(stop_words=ENGLISH_STOP_WORDS,ngram_range=(1, 1),max_features=100)columns_list = ['seller_path']for i, col in enumerate(columns_list):tfidfVec.fit(all_data_test[col])data_ = tfidfVec.transform(all_data_test[col])if i == 0:data_cat = data_else:data_cat = sparse.hstack((data_cat, data_))
import gensimmodel = gensim.models.Word2Vec(all_data_test['seller_path'].apply(lambda x: x.split(' ')),size=100,window=5,min_count=5,workers=4)def mean_w2v_(x, model, size=100):try:i = 0for word in x.split(' '):if word in model.wv.vocab:i += 1if i == 1:vec = np.zeros(size)vec += model.wv[word]return vec / iexcept:return np.zeros(size)def get_mean_w2v(df_data, columns, model, size):data_array = []for index, row in df_data.iterrows():w2v = mean_w2v_(row[columns], model, size)data_array.append(w2v)return pd.DataFrame(data_array)df_embeeding = get_mean_w2v(all_data_test, 'seller_path', model, 100)df_embeeding.columns = ['embeeding_' + str(i) for i in df_embeeding.columns]
# 1、使用 5 折交叉验证from sklearn.model_selection import StratifiedKFold, KFoldfolds = 5seed = 1kf = KFold(n_splits=5, shuffle=True, random_state=0)# 2、选择 lgb 和 xgb 分类模型作为基模型clf_list = [lgb_clf, xgb_clf]clf_list_col = ['lgb_clf', 'xgb_clf']# 3、获取 Stacking 特征clf_list = clf_listcolumn_list = []train_data_list=[]test_data_list=[]for clf in clf_list:train_data,test_data,clf_name=clf(x_train, y_train, x_valid, kf, label_ split=None)train_data_list.append(train_data)test_data_list.append(test_data)train_stacking = np.concatenate(train_data_list, axis=1)test_stacking = np.concatenate(test_data_list, axis=1)
valid_0's multi_logloss: 0.240875Training until validation scores don't improve for 100 rounds.valid_0's multi_logloss: 0.240675train-mlogloss:0.123211 eval-mlogloss:0.226966Best iteration:train-mlogloss:0.172219 eval-mlogloss:0.218029xgb now score is: [2.4208301225770263, 2.2433633135072886, 2.51909203146584 34, 2.4902898448798805, 2.5797977298125625]xgb_score_list: [2.4208301225770263, 2.2433633135072886, 2.5190920314658434, 2.4902898448798805, 2.5797977298125625]xgb_score_mean: 2.4506746084485203

 福利来了
福利来了