
Flink Table Store 入湖 | 基于 Apache Flink Table Store 的全增量一体实时入湖
摘要:本文简要回顾数据入湖(仓)的发展阶段,针对在数据库数据入湖中面临的问题,提出了使用 Flink Table Store 作为全增量一体入湖的解决方案,并辅以开源 Demo 的测试结果作为展示。文章主要内容包括:
数据库数据集成入湖(仓)的发展阶段及面临痛点
基于 Apache Flink Table Store 解决全增量一体入湖
总结与展望
数据入湖(仓)发展阶段及面临痛点
基于数据库的数据集成过程,简要来说经历了如下几个阶段。
1.1 全量 + 定期增量的数据入仓
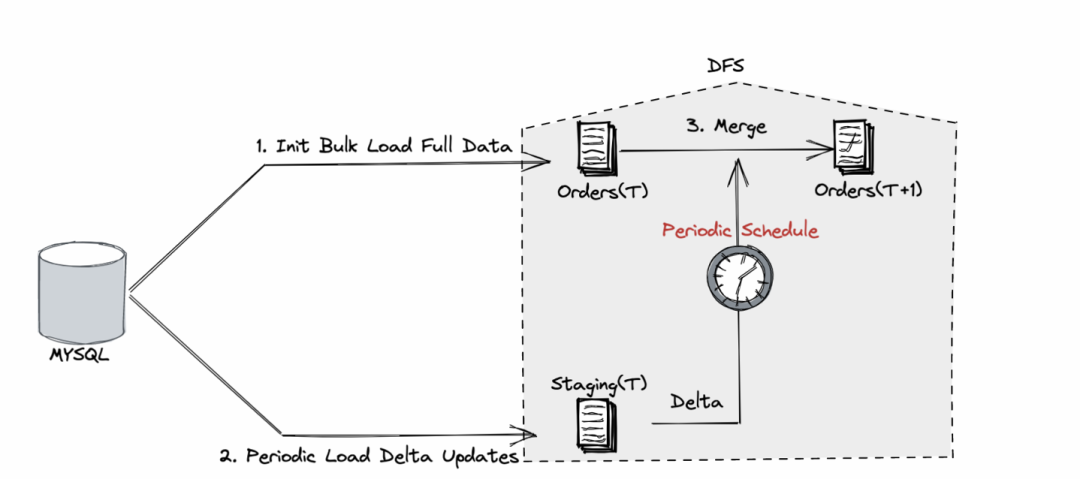
⚠️ 链路复杂,时效性差
⚠️ 明细查询慢,排查问题难
虽然下游会使用各种交互式分析引擎来加速查询,但基于成本考虑,底表明细数据一般没有这种待遇,这就导致在数据正确性排查时需要直接查询明细,特别是需要查询合并前后全量和增量的明细变化来定位问题。如果业务变更,导致一批订单数据需要订正并要求生成订正之后的各类指标,则需要手工对原始表及其下游依赖表进行级联订正。
1.2 全量 + 实时增量的数据入湖
相对于传统数据仓库,数据湖的出现使得数据在以低成本存储的同时,数据新鲜度有了极大的提升。以 Apache Hudi 为例,它支持先做一次全量 bootstrap 构建基础表,然后基于新接入的 CDC 数据进行实时构建 [1],如 Fig.2 所示。
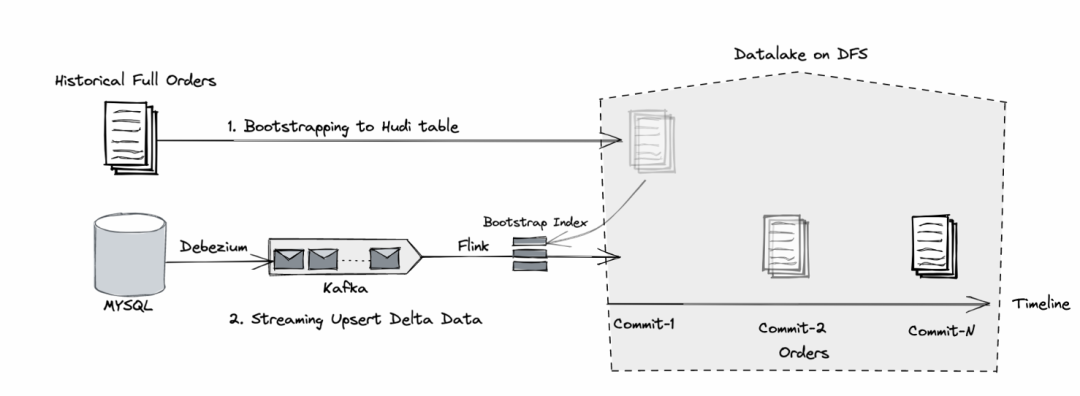
Fig.2 数据入湖: 一次全量+实时增量
由于支持记录级别的更新及删除,在存储侧就可以完成主键的去重,不再需要额外的合并任务。在数据新鲜度方面,由于流式作业会定期的触发 checkpoint 来产生全量与增量合并后的快照,故而数据新鲜度对比第一种方式(以天或小时调度产生合并快照)有了很大提升。
但从另外一方面,我们也发现这种方式有以下这些问题。
🤔 Bootstrap Index 超时及 state 膨胀
以流模式启动 Flink 增量同步作业后,系统会先将全量表导入到 Flink state 来构建 Hoodie key(即主键 + 分区路径)到写入文件的 file group 的索引,此过程会阻塞 checkpoint 完成。而只有在 checkpoint 成功后,写入的数据才可以变为可读状态,故而当全量数据很大时,有可能会出现 checkpoint 一直超时的情况,导致下游读不到数据。另外,由于索引一直保存在 state 内,在增量同步阶段遇到了 insert 类型的记录也会更新索引,需要合理评估 state TTL,配置太小可能会丢失数据,配置过大可能导致 state 膨胀。
🤔 链路依然复杂,难以对齐增量点位,自动化运维成本高
此外,我们回顾了一些使用 Hudi 的行业实践,发现用户需要格外注意各项配置来实现不同需求,这对易用性有一定的伤害。比如 [1] 中提到的需要在平台层面监控用户的建表语句,防止在大规模写入场景配置为 COW(Copy on Write) 模式;全增量切换时用户必须格外注意 Kafka 消费点位来保证数据准确性,参数配置极大影响了作业的数据准确性及性能。
基于 Apache Flink Table Store 的全增量一体入湖
随着基于日志的 CDC 逐步取代基于查询的 CDC,特别是 Flink SQL CDC 在 source 端已支持全增量一体同步后,全增量一体入湖(使用一个流作业完成全量同步、并持续监听增量 changelog)也成为一个新的探索方向。这种方式降低了链路复杂度,同时将全增量切换时需要手工对齐 offset 的繁琐托管给了 Flink CDC 和 checkpoint 机制,让框架层面去保障数据的最终一致性。但经过调研我们发现,在使用 Hudi 做这种尝试时遇到了以下挑战。
🤔 全量同步阶段数据乱序严重,写入性能和稳定性难以保障
在全量同步阶段面临的一个问题是多并发同时读取 chunk 会遇到严重的数据乱序,出现同时写多个分区的情况,大量的随机写入会导致性能回退,出现吞吐毛刺,每个分区对应的 writer 都要维护各自缓存,很容易发生 OOM 导致作业不稳定。虽然 Hudi 支持通过 Rate Limit [3] 限制每分钟的数据写入来起到一定的平滑效果,但在作业稳定性和性能吞吐之间取得平衡的调优过程对于一般用户来说门槛也较高。
2.1 为什么选择 Flink Table Store
Apache Table Store [4] 作为 2022 年初开源的 Apache Flink 子项目,目标是打造一个支持更新的据湖存储,用于实时流式 Changelog 摄取和高性能查询。
🚀 大吞吐量的更新数据摄取,支持全增量一体入湖,一个 Flink 作业搞定所有
-- 创建并使用 table store catalogCREATE CATALOG `table_store` WITH ('type' = 'table-store','warehouse' = 'hdfs://foo/bar');USE CATALOG `table_store`;-- 定义 mysql-cdc source 表CREATE TEMPORARY TABLE `orders_cdc` (order_id BIGINT NOT NULL,gmt_modified TIMESTAMP(3) NOT NULL,...PRIMARY KEY (`order_id`) NOT ENFORCED) WITH ('connector' = 'mysql-cdc',...);-- 定义 table store ods 表,按日期作分区CREATE TABLE IF NOT EXISTS `orders` (...PRIMARY KEY (`dt`, `order_id`) NOT ENFORCED) PARTITIONED BY (`dt`);-- streaming 模式下提交作业SET 'execution.runtime-mode' = 'streaming';-- 设置 1min 的 cp interval,对应 1min 的数据新鲜度SET 'execution.checkpointing.interval' = '1min';-- 一条 SQL 同步全量 + 增量,动态分区写入INSERT INTO `orders`SELECT ..., DATE_FORMAT(gmt_modified, 'yyyy-MM-dd') AS dtFROM `orders_cdc`;
Fig.4 展示了以 dt 作为分区 orders 表的存储结构,在用户指定总 bucket 数 N 后,每个分区下会生成相应的 bucket-${n} 目录,每个目录下以列存格式(orc 或 parquet)存放 hash_func(pk) % N == ${n} 的记录文件。
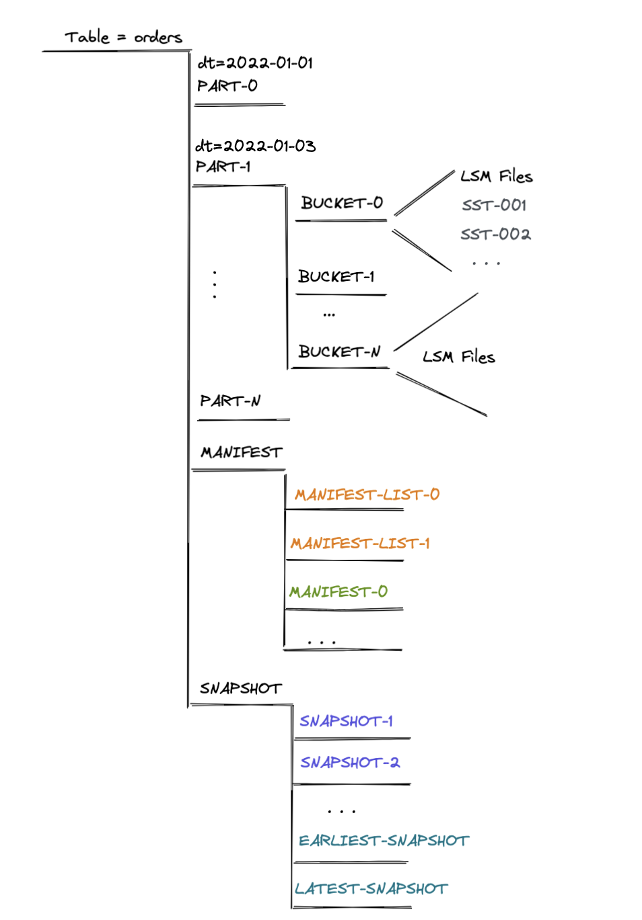
Fig.4 Flink Table Store 表的文件目录
元数据与数据存储在表的同一级目录下,包括 manifest 目录和 snapshot 目录。
manifest 目录下中记录每次经 checkpoint 触发而提交的数据文件变更,包含新增和删除的数据文件 snapshot 目录下记录每次提交产生的 snapshot 文件,内容包括为上一次提交产生的 manifest,加上本次提交产生的 manifest 作为增量
生成当前 table 的一个快照(snapshot)。系统会通过 snapshot pointer file(类似于指针)追踪最早产生和当前最新的 snapshot 文件
snapshot 文件中包含本次 commit 新增哪些 manifest 文件、删除哪些 manifest 文件
每个 manifest 文件中记录了产生了哪些 sst 文件、删除了哪些 sst 文件,以及每个 sst 文件所包含记录的主键范围、每个字段的 min/max/null count 等统计信息
每个 sst 文件则包含了按主键排好序的、列存格式的记录。对于 Level 0 的文件,Table Store 会异步地触发 compact 合并线程来消除主键范围重叠带来的读端 merge 开销
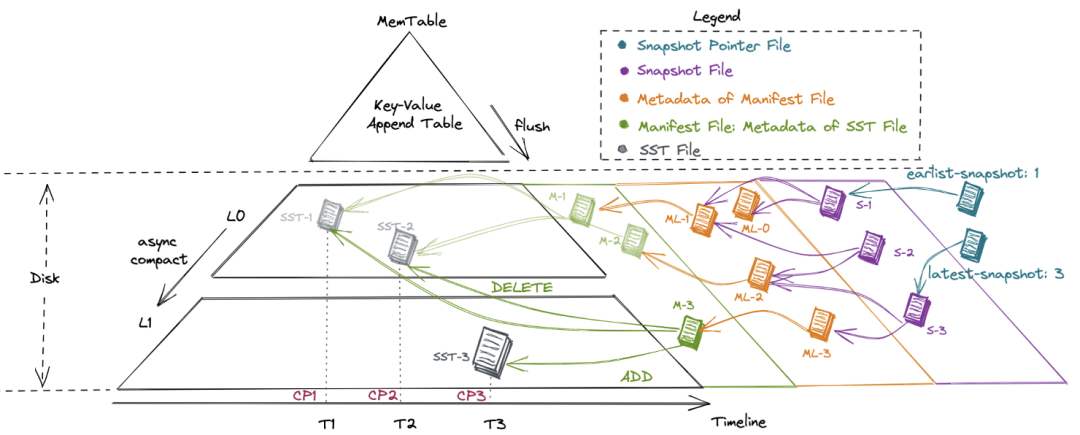
Fig.5 Flink Table Store 表的 LSM 实现
🚀 高效 Data Skipping 支持过滤,提供高性能的点查和范围查询
虽然没有额外的索引,但是得益于 meta 的管理和列存格式,manifest 中保存了
文件的主键的 min/max 及每个字段的统计信息,这可以在不访问文件的情况下,进行一些 predicate 的过滤 orc/parquet 格式中,文件的尾部记录了稀疏索引,每个 chunk 的统计信息和 offset,这可以通过文件的尾部信息,进行一些 predicate 的过滤
读取 manifest:根据文件的 min/max、分区,执行分区和字段的 predicate,淘汰多余的文件 读取文件 footer:根据 chunk 的 min/max,过滤不需要读取的 chunk 读取剩下与文件以及其中的 chunks
SELECT * FROM orders WHERE dt = '2022-01-01' AND order_id >= 100 AND order_id <= 200;我们同样基于上述数据集测试了 Flink Table Store 的查询性能[9],在点查和范围查询的场景下,Flink Table Store 表现出众。从实现原理来说,MOR 的查询性能低于 COW、COW 的写入性能低于 MOR 是难以避免的。而在实践层面,在大规模写入场景下建立的 MOR 表也很难一键转换为 COW 来读取,所以在查询写入较多的表(MOR 表)这个前提下,Flink Table Store 的查询表现还是不俗的。
🚀 文件格式支持流读
-- 进入 SQL CLI,创建 catalog 和 tableCREATE CATALOG table_store WITH ('type' = 'table-store','warehouse' = 'file://foo/bar/' --或 'hdfs://foo/bar');CREATE TABLE IF NOT EXIST my_table (f0 INT,f1 STRING,PRIMARY KEY(f0) NOT ENFORCED);-- 切换到 batch 模式,写入数据SET 'execution.runtime-mode' = 'batch';INSERT INTO my_table VALUES(1, 'Hello');-- 新打开一个 SQL CLI 中,切换到 streaming 模式,提交流式查询SET 'execution.runtime-mode' = 'streaming';SET 'sql-client.execution.result-mode' = 'tableau';SELECT * FROM my_table;-- 可以读到结果如下+----+-------------+--------------------------------+| op | f0 | f1 |+----+-------------+--------------------------------+| +I | 1 | Hello |-- 在第一个 SQL CLI 中,继续写入数据INSERT INTO my_table VALUES(1, 'Bye'), (2, '你好');-- 可以在第二个 SQL CLI 中,观察到新增输出 (-U, 1, Hello),(+U, 1, Bye) 和 (+I, 2, 你好)+----+-------------+--------------------------------+| op | f0 | f1 |+----+-------------+--------------------------------+| +I | 1 | Hello || -U | 1 | Hello || +U | 1 | Bye || +I | 2 | 你好 |
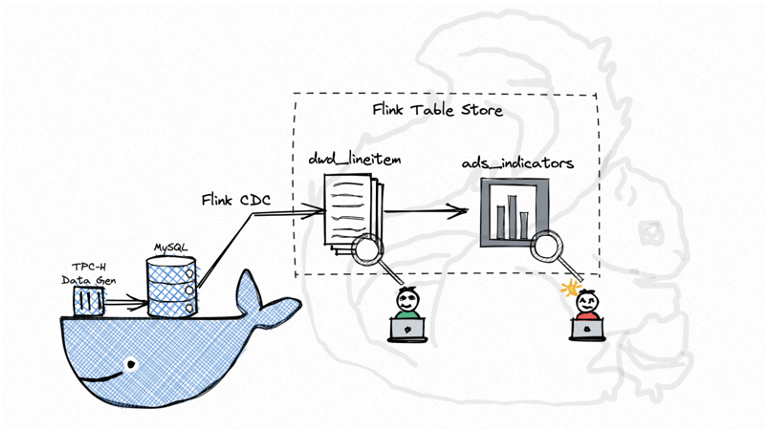
2.2 基于 TPC-H 数据集的全增量一体入湖 Demo
前文对 Flink Table Store 解决全增量一体入湖进行了简要分析,下面一个实例演示了如何在本地单机环境下,将近六千万条订单记录作为全量数据从 MySQL 同步到 Flink Table Store,并持续消费增量更新(由 TPC-H RF1 和 RF2 产生),下游接实时聚合及查询的过程。
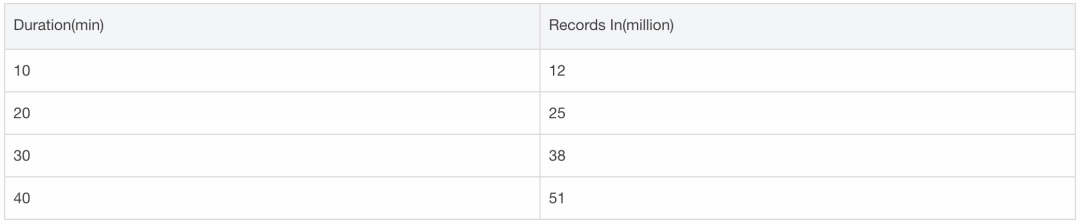
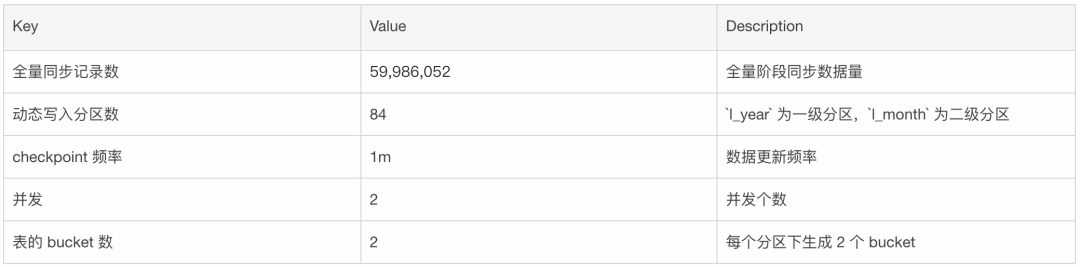
总结与展望
[1] 基于 Hudi 的湖仓一体技术在 Shopee 的实践
https://mp.weixin.qq.com/s/3nsYTVu9nZCIFaaXP09hiQ
▼ 关注「Apache Flink」,获取更多技术干货 ▼