
收藏 | 推荐系统面试题(6-10)

文 | 七月在线
编 | 小七
Q1
如何理解图卷积算法?
解析:
1)发射(send)每一个节点将自身的特征信息经过变换后发送给邻居节点。这一步是在对节点的特征信息进行抽取变换
2)接收(receive)每个节点将邻居节点的特征信息聚集起来。这一步是在对节点的局部结构信息进行融合
3)变换(transform)把前面的信息聚集之后做非线性变换,增加模型的表达能力
Q2
GCN有哪些特征?
解析:
1.GCN 是对卷积神经网络在 graph domain 上的自然推广
2.它能同时对节点特征信息与结构信息进行端对端学习,是目前对图数据学习任务的最佳选择
3.图卷积适用性极广,适用于任意拓扑结构的节点与图
4.在节点分类与边预测等任务上,在公开数据集上效果要远远优于其他方法Q3
已知基于数据驱动的机器学习和优化技术在单场景内的A/B测试上,点击率、转化率、成交额、单价都取得了不错的效果。 但是,目前各个场景之间是完全独立优化的,这样会带来哪些比较严重的问题 ?
解析:
1.不同场景的商品排序仅考虑自身,会导致 用户的购物体验是不连贯或者雷同的 。例如:从冰箱的详情页进入店铺,却展示手机;各个场景都展现趋同,都包含太多的U2I(点击或成交过的商品);
2.多场景之间是博弈(竞争)关系, 期望每个场景的提升带来整体提升这一点是无法保证的 。很有可能一个场景的提升会导致其他场景的下降,更可怕的是某个场景带来的提升甚至小于其他场景更大的下降。这并非是不可能的,这种情况下,单场景的A/B测试就显得没那么有意义,单场景的优化也会存在明显的问题。Q4
什么是多场景联合排序算法 ?
解析:
多场景联合排序算法,旨在提升整体指标。我们将多场景的排序问题看成一个完全合作的、部分可观测的多智能体序列决策问题,利用Multi-Agent Reinforcement Learning的方法来尝试着对问题进行建模。该模型以各个场景为Agent,让各个场景不同的排序策略共享同一个目标,同时在一个场景的排序结果会考虑该用户在其他场景的行为和反馈。这样使得各个场景的排序策略由独立转变为合作与共赢。由于我们想要使用用户在所有场景的行为,而DRQN中的RNN网络可以记住历史信息,同时利用DPG对连续状态与连续动作空间进行探索,因此我们算法取名MA-RDPGQ5
IRGAN框架具体是什么?
解析:
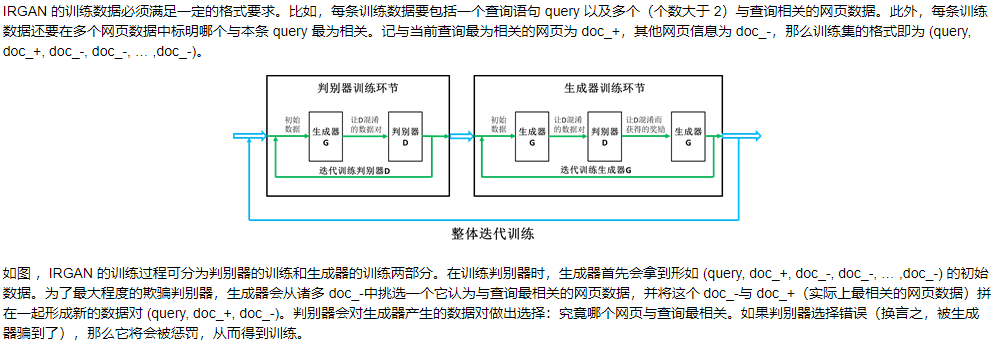

评论