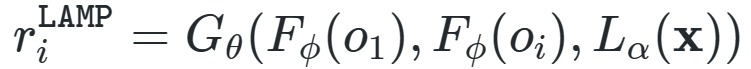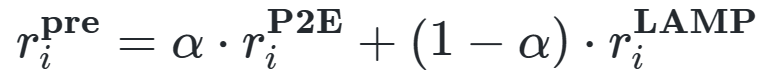在强化学习(RL)领域,一个重要的研究方向是如何巧妙的设计模型的奖励机制,传统的方式是设计手工奖励函数,并根据模型执行任务的结果来反馈给模型。后来出现了以学习奖励函数(learned reward functions,LRF)为代表的稀疏奖励机制,这种方式通过数据驱动学习的方式来确定具体的奖励函数,这种方法在很多复杂的现实任务中展现出了良好的性能。 本文介绍一篇来自UC伯克利研究团队的最新论文,本文作者质疑,使用LRF来代替任务奖励的方式是否合理。因此本文以当下火热的视觉语言模型(Vision-Language Models,VLMs)的zero-shot能力为研究对象,作者认为这种zero-shot能力可以作为RL模型的预训练监督信号,而不是将其单纯作为下游任务中的奖励,并提出了一种称为语言奖励调节预训练模型LAMP,LAMP首先使用参数冻结的预训练VLMs,并且通过在内容丰富的语言指令集上与代理捕获的视觉信息进行对比查询,来生成多样化的预训练奖励,随后通过强化学习算法来优化这些奖励。作者通过广泛的实验表明,LAMP不同于以往的VLMs预训练方式,可以在机器人操纵任务领域实现非常惊人的样本高效学习。
https://arxiv.org/abs/2308.12270 https://github.com/ademiadeniji/lamp
回过头看,强化学习领域也经历了从手工设计奖励函数到网络自主学习的发展历程。手工设计的奖励函数往往会过度工程化,这使得其无法适用于新的代理程序和新的环境,因此发展出来通过从大量演示数据中学习所需的最优奖励函数,但是这种方式也会带来大量的噪声和错误的奖励,这在高精密机器人操纵等复杂的任务领域是不可靠的。本文作者受现有大型预训练VLMs的启发,VLM可以在多种任务上展现出高效的zero-shot性能,且拥有快速适应新任务的能力。同时VLMs的训练过程是通过计算代理模型对图像的特征表示与任务特定文本语言之间的对齐分数来实现,这种方式具有一种隐含的多任务适应能力,即其只需要使用不同的语言指令进行提示,就可以生成多种不同奖励的可扩展方法。这一特性尤其符合RL预训练的假设,即将这种跨任务的奖励作为RL通用代理的预训练工具,而不再依靠之前的含噪LRF来训练只能在单一任务上运行的专家RL模型。
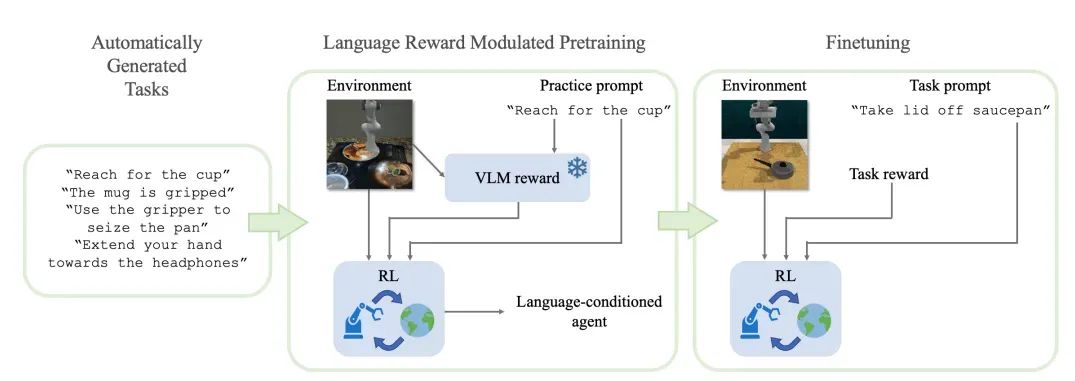
上图展示了本文所提LAMP模型的整体框架,在预训练阶段,LAMP可以利用高度多样化的语言提示和从代理模型中提取到的视觉特征来构成文本视觉对,并将这些数据对输入到VLMs中进行查询,从而生成多样化的、形状各异的预训练奖励。而在下游任务微调阶段,可以使用一种简单的以语言为条件的多任务强化学习算法来优化这些奖励,通过实验证明,LAMP在真实的机器人环境中可以有效的降低下游任务微调的样本数量,但同时保持较好的操纵性能。
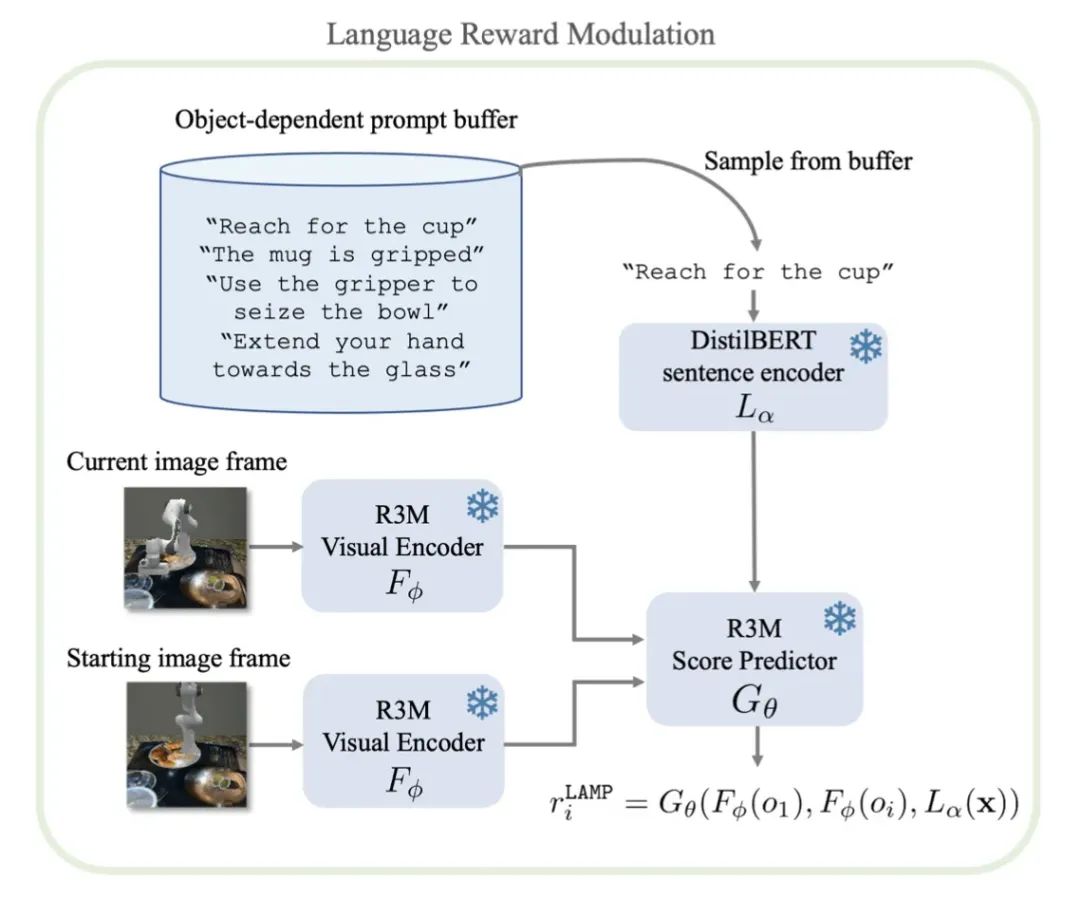
下图展示了LAMP的具体实现过程,LAMP主要包含两个训练阶段:
(1)与任务无关的RL预训练阶段,使用一系列语言指令来从VLMs模型中查询奖励,来对RL代理模型进行预训练。
(2)下游任务的微调阶段,使用新任务的指令,并以这些语言指令为条件调整预训练学习到的策略,通过最大化新任务奖励来解决目标任务。
2.1 语言奖励调节 为了从VLMs中提取RL的预训练奖励信号,作者选取了R3M[1]作为视觉语言特征提取器,R3M从大规模第一人称视角的人类视频数据集Ego4D中提取特征语义表示,有效提升了现实世界机器人领域中模仿学习的数据效率。语言输入使用 来处理, 是一种预训练的DistilBERT transformer模型,可以高效的聚合文本指令中每个单词的嵌入编码。作者使用R3M作为文本指令与视觉观察特征之间的奖励分数生成器,作者认为R3M分数更适合于提供视觉层面上的动作奖励,因为它的表征经过了明确的训练,可以理解视频中的时序信息。具体来说,使用R3M分数定义的奖励如下: 其中 表示R3M中的分数预测器, 分别表示图像 到 之间的视觉特征,作者发现,与其他的VLMs相比,使用R3M分数得到的奖励与专家演示中的奖励非常接近,下图展示了R3M与其他两种模型InternVideo[2]和ZeST[3]在RLBench下游任务上的视觉语言对齐效果,但是从奖励曲线来看,三种方法的奖励走向并不稳定,这表明我们很难直接使用这些奖励来优化最终模型,因此作者仅在预训练阶段将这些奖励作为一种探索信号。 2.2 以语言为条件进行行为学习 为了使训练得到的RL模型可以用于多种不同的下游任务,作者为LAMP设计了一组具有视觉效果和各种对象的任务,首先基于RLBench仿真工具包构建了一个自定义环境,为了模拟逼真的视觉场景,作者从Ego4D数据集中下载了大量的真实场景图像,并将其作为纹理叠加在环境的桌面和背景上。为了制作多样化的物体和功能,作者将大量的ShapeNet 3D物体网格导入到环境中,这样可以使得训练过程中出现的视觉纹理和物体在每次迭代时都是随机的。 由于LAMP得到的奖励分数可以被用来衡量代理模型解决任务与实际任务要求之间的距离,因此它可以很容易地与一些无监督的RL方法相结合。因此,为了激发LAMP对新任务的探索能力,作者将LAMP奖励与Plan2Explore算法[4]的内在奖励结合起来,Plan2Explore是一种倾向于探索任务新颖性的无监督强化学习算法,其利用与未来时刻的隐藏状态预测之间的差异作为新颖性得分,这个新颖性分数可以表示为 ,因而可以得到预训练阶段的代理目标函数,表示为如下的加权奖励总和: 作者使用ChatGPT来生成一系列的机器人操纵任务,例如“按下按钮(Push Button)”、“拿起水杯(Pick up Cup)”等,LAMP每次会从这些任务中随机抽取一些语言提示 ,然后得到其对应的视觉嵌入 ,之后根据上一节中描述的方法计算得到最终的奖励。在预训练结束后,LAMP就得到了一种较为通用的语言条件策略,它能够引导机器人完成语言 指定的各种行为。具体如下图所示,预训练过程主要基于Ego4D纹理的随机环境上进行。 由于LAMP已经学习到了一定的语言条件策略,因此只需要选择与下游任务语义大致对应的语言指令 ,即可对预训练代理进行下游任务的条件化,作者强调这是LAMP的一个显著的优势,它使用语言作为任务说明符,这使得我们可以以极低成本的方式对模型进行下游任务的微调。
本文的实验在96个随机域环境上进行,这些环境是通过随机采样不同的Ego4D纹理得到的,同时作者还以0.2的概率对RLBench默认环境纹理的环境进行采样,对于机器人的操作空间,作者设置了4维的连续动作空间,其中前三个维度表示机器人末端执行器的位置信息,最后一个维度用来控制机械臂的夹具动作。作者选取了一个从头训练的代理模型以及Plan2Explore(P2E)方法作为对比baseline进行实验
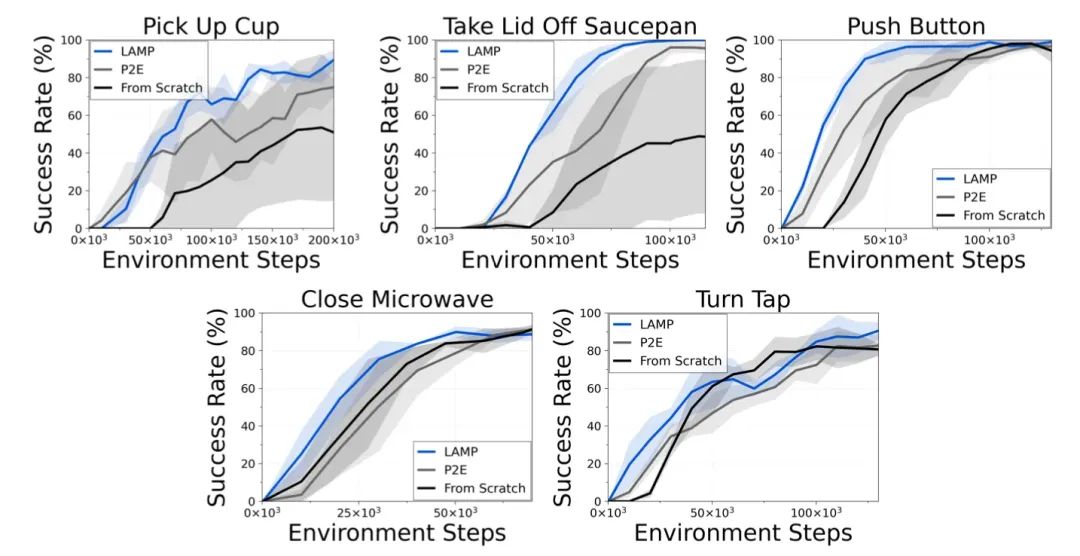
3.1 模型微调效果 作者选取了Pick Up Cup(拿起杯子)、Take Lid Off Saucepan(打开锅盖)、Push Button(按下按钮)、Close Microwave(关闭微波炉)和Turn Tap(打开水龙头)五个常见的操作任务进行实验,下图展示了实验结果对比。
可以看出,从头开始对随机初始化的代理进行新任务训练会表现出较高的样本复杂度,在大多数的RLBench任务中,采用无监督探索的Plan2Explore方法明显超过了从头开始训练的性能,进而可以观察到,本文提出的LAMP方法的性能更好,作者分析认为,LAMP使用VLMs奖励进行预训练,可以使代理模型得到更加多样化的奖励,这样学习到的表征使其能够在微调期间快速适应到全新的任务上。
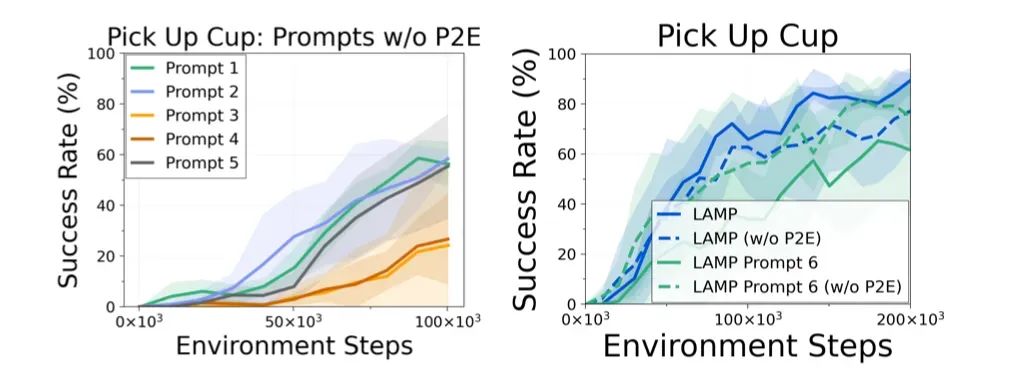
3.2 对语言提示进行消融实验 使用预训练VLMs的一个优势是可以通过输入多样性的查询文本来获得近乎无限的奖励,作者对预训练阶段使用的不同提示样式进行了消融研究,使用的6种语言提示风格如下:
其中提示样式1-5主要对比了动词和名词相关和多种不相关情况的对比,而提示样式 6,作者直接选择了较高难度的莎士比亚的文本片段,以观察完全在预训练分布之外的样本适应情况,下图中展示了使用不同提示样式预训练之后的模型微调效果对比。
其中提示1-5都是基于任务动作的提示,这里选择了任务“拿起杯子”,因为该任务名称简单,而且与预训练中的提示非常相似,可以看到,在这项任务中,语义相似但提示语呈现多样化的提示样式2达到了最佳性能。而在上图右侧作者重点分析了莎士比亚文本对模型微调的影响,其中作为对比的是使用最佳提示样式2的模型,可以看到,在去除掉P2E模型后,LAMP Prompt 6和LAMP Prompt 2的性能表现基本上持平,但是当加入P2E模型后,使用这些分布外的语言提示,会严重影响LAMP的性能。
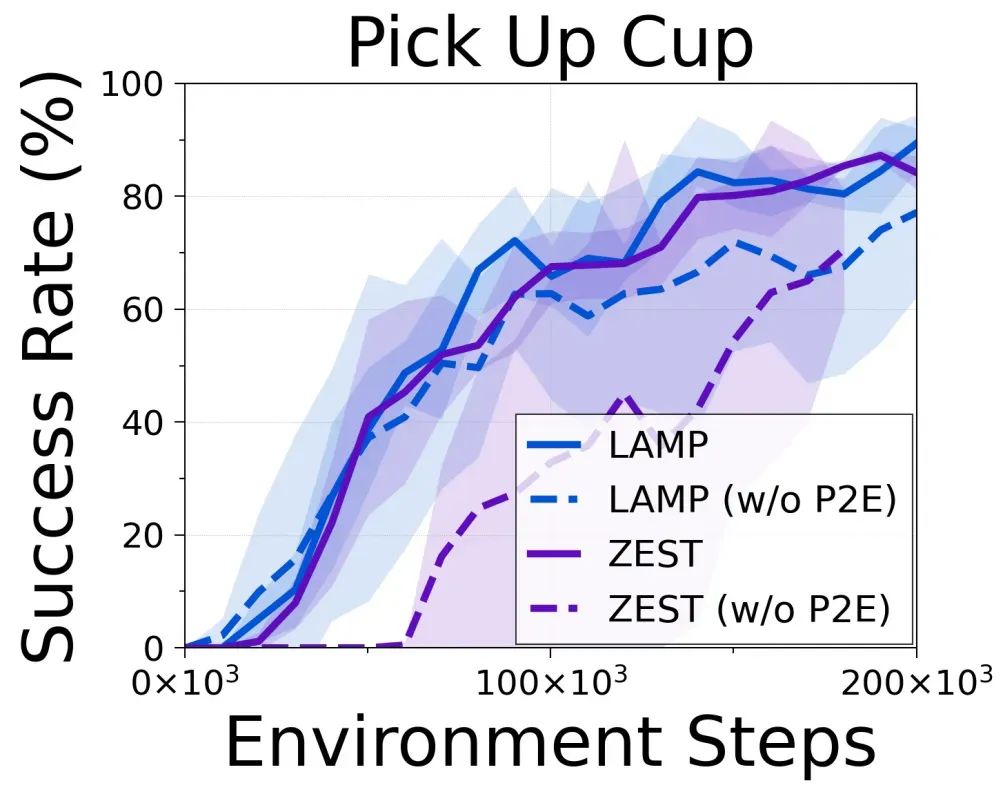
3.3 与其他视觉语言奖励模型进行比较 除了对语言提示进行研究之外,作者还对预训练阶段使用不同VLMs的效果进行了对比,这里作者选择了ZeST模型,ZeST大体上与CLIP模型的训练方式相同,也是通过提取文本特征与图像特征之间的相似度来作为奖励模型。
上图展示了LAMP使用R3M和ZeST在“Pick Up Cup”下游任务上的微调效果对比,其中R3M似乎能带来更好的持续性能,但ZeST预训练的性能也不差。由此作者得出结论,本文的方法本质上并不依赖于特定的VLM,未来可以更换更加强大的VLMs来进一步提高性能。
在这项工作中,作者研究了如何利用VLMs的灵活性作为多样化强化学习奖励生成的一种手段,并且提出了一种基于语言提示的奖励调节模型LAMP,LAMP突破了传统深度强化学习中学习奖励函数的诸多限制,并且利用VLMs强大的zero-shot泛化能力,可以在模型预训练期间产生很多不同的奖励。此外作者发现,基于VLMs的奖励模型可以与很多新型的RL优化方法相结合,例如其与Plan2Explore结合可以带来强大的性能。本文通过大量的实验表明,LAMP方法在多种具有挑战性的场景中表现出了更加优越的强化学习优化能力。
参考 [1] Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual representation for robot manipulation, 2022.
[2] Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hon jie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning, 2022.
[3] Yuchen Cui, Scott Niekum, Abhinav Gupta, Vikash Kumar, and Aravind Rajeswaran. Can foundation models perform zero-shot task specification for robot manipulation?, 2022.
[4] Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. Planning to explore via self-supervised world models. CoRR, abs/2005.05960, 2020