
CVPR'22 Oral|目标检测的新工作开源!AdaMixer:基于快速收敛查询的目标检测器

极市导读
本文介绍了南京大学等提出的在目标检测的新工作AdaMixer:通过增强检测器的自适应建模能力来加速query-based检测器(类DETR检测器和Sparse RCNN)的收敛和最终的表现效果,并且使模型架构维持在一个相对简单的结构上。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/pdf/2203.16507.pdf
代码链接(已开源):https://github.com/MCG-NJU/AdaMixer
本文介绍一下我们在目标检测的新工作AdaMixer,通过增强检测器的自适应建模能力来加速query-based检测器(类DETR检测器和Sparse RCNN)的收敛和最终的表现效果,并且使模型架构维持在一个相对简单的结构上。我们提出了一系列技术来增强query-based检测器的decoder解码部分,包括3D特征空间采样和动态MLP-Mixer检测头,这使得我们免于引入设计繁重、计算量大的各种注意力编码器(attentional encoder),或者特征金字塔式的多尺度交互网络,在保持效果的同时(其实我们超越了很多之前的模型),进一步简化了基于query的检测器的结构。
研究动机
首先,我们简单介绍一下我们的研究动机。现在基于query的检测器成为学术研究的热点,其通过query集合(有的文章也称proposal集合)和图像特征图的迭代交互抽取特征,不断完善query本身的语义,使其能够在matching loss下完成query对object的一对一cls和bbox预测。基于query的检测器不需要后续的NMS操作,使得整个检测流程更为简单和优雅。但是我们发现,基于query的检测器,尤其是类DETR检测器,其通常引入了多层的注意力编码器(attentional encoder),这些注意力编码器对每个像素密集地进行全局或者局部的注意力计算,引入了较大的运算量,且不易于拓展到高分辨率的特征图上,由此带来了小物体检测困难的问题,而且可能会带来训练时长的困扰。Sparse R-CNN流派引入了显式的特征金字塔网络FPN来增强对小物体的建模,但同样的,特征金字塔网络会引入额外的计算量。我们觉得在backbone和decoder之间加入额外的网络其实有些不优雅,而且这和用query做检测的目标有点相违背了。如果检测器需要厚重的密集编码器的话,那用数量少的query通过decoder可以检测物体作为模型的亮点就有点南辕北辙了。出现这些问题的根本原因还是decoder不够强势,需要encoder的建模能力来弥补,所以我们的方法的根本动机就是增强decoder的能力,使检测器尽量避免引入各种encoder。
但如何增强decoder的能力呢,尤其是对不同图像不同目标的多样化建模能力?这个问题对只使用稀疏且数量限制的query的解码器至关重要。回顾典型的query decoder本身,是一个基于transformer decoder的结构,首先将query和query之间做self attention,而后query和图像特征feat做交互,然后每个query再过FFN。而这些初始的query虽然一般都是可学习的向量,但在inference时就固定下来,无法对不同的输入而变化(虽然现在有潮流把初始的query由类RPN产生),所以如何保证query decoder本身的解码机制对不同图片输入不同物体的自适应能力就成了一个问题。为此,我们提出从两个方面来改进这种基于query的目标检测器:采样位置的自适应能力和解码特征的自适应能力,对应着就是我们提出的3D特征空间采样和动态MLP-Mixer检测头。
方法
我们简单介绍一下我们的AdaMixer检测器两个代表性的创新点,以利于读者迅速抓取到我们方法的脉络。有些细节在此忽略了,具体可以查看原文。
自适应的特征采样位置
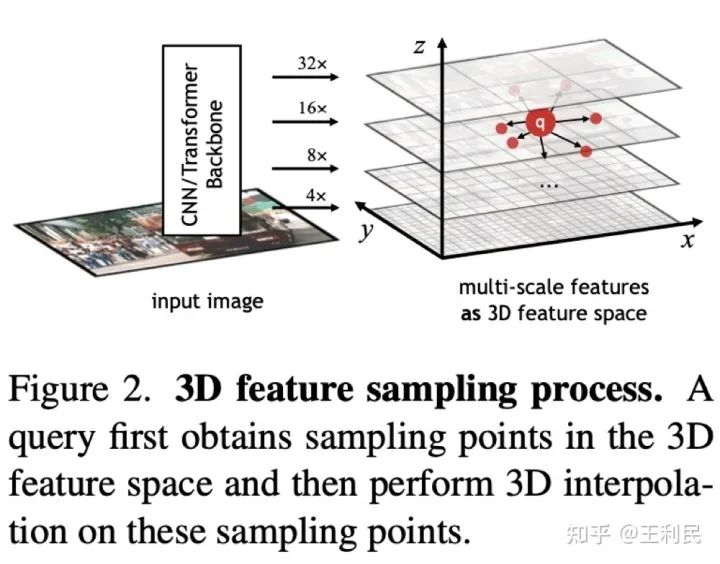
与现在其他方法一样,我们把query解耦成两个向量,分别是内容向量(content vector)和位置向量(positional vector),其中query代表着的框可以由位置向量解码而来。在每一个stage,query decoder都会更新refine这两个向量。值得注意的是,我们对位置向量采用的参数化并不是常用框的lrtb坐标或是ccwh坐标,而是xyzr形式,其中z代表着框大小的对数,r代表着框长宽比的对数,这种参数化形式的xyz可以直接让我们的query可以与多层级特征所形成的3D特征空间进行联系。如上图所示,3D特征空间中的query坐标自然由xyz决定,自适应3D特征采样首先由query根据自己的内容向量生成多组offset,再在3D特征空间上进行对应点的插值采样得到对应的特征,3D特征空间有益于我们的方法统一自适应地学习目标物体的位置和尺度的变化。注意这一步是不需要任何多尺度交互网络的。
自适应的采样内容解码
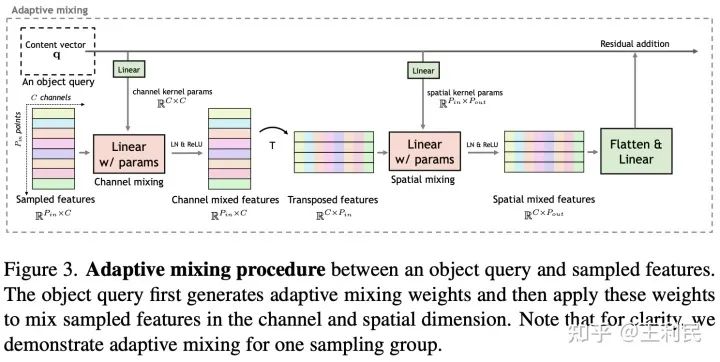
对于一个query而言上述步骤采集到的特征形状为 ,其中 为采样点的个数, 是通道数量,我们在MLP-Mixer的启发下提出了逐query的自适应通道和空间mixing操作(adaptive channel mixing,ACM和adaptive spatial mixing,ASM)。具体来说,我们的decoder用动态依赖于query的权重去沿两个维度(通道 和空间 )mixing采集到的特征,由于采集的特征可能来自于不同层级的特征图,这样的mixing操作自然赋予了decoder多尺度交互建模的能力。
总结构
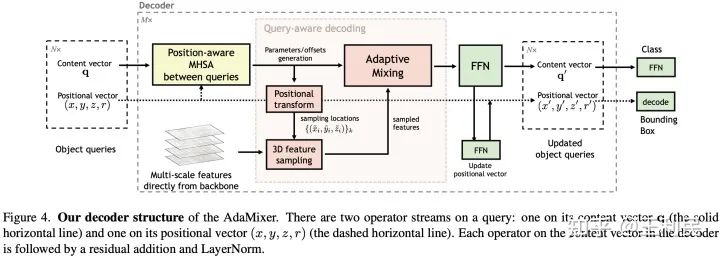
我们的AdaMixer解码器总结构如上图,虽然看起来有一点繁琐,但是在内容向量上的操作基本构造还是和Transformer decoder是一致的,位置向量可以简单地视为在一个stage内参与坐标变换和计算,然后在一个stage的末尾再更新。
总的AdaMixer检测器只由两个主要部分构成:其一是主干网络,其二是我们所提出来的AdaMixer解码器,不需要额外的注意力编码器以及显式的多尺度建模网络。
结果
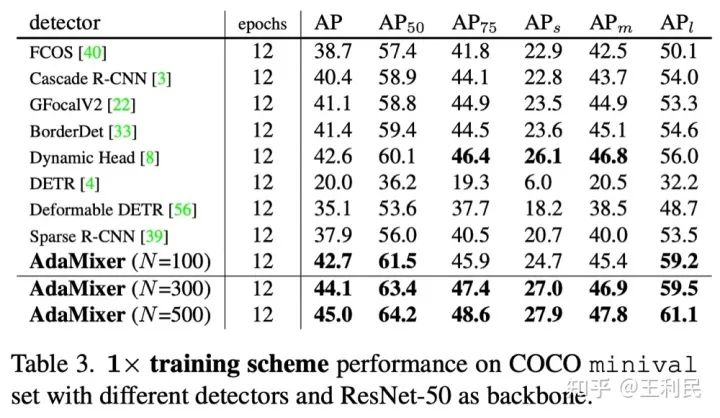
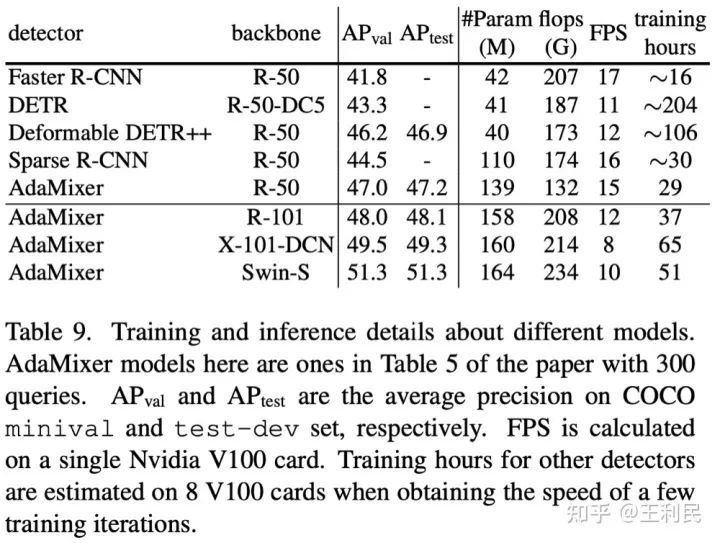
实验结果在当时投稿时还是比较精彩的,在12 epoch的训练条件下,我们的表现超过了其他检测器(包括传统以及基于query的检测器),其中N为query的数量,证明了我们的方法的收敛速度和最终效果。而且我们的12 epoch在8卡V100上实际训练时间还是比较快的,只要9小时。
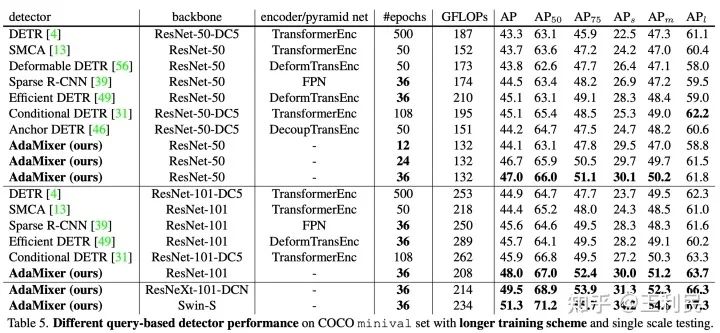
在与跟其他query-based检测器相比下,我们也有更好的表现,而且我们是表中唯一不需要额外的注意力编码器或者金字塔特征网络的模型。
消融实验
我们做了比较丰富的消融实验来验证我们提出的各个模块的有效性。在此,我们选一些有代表性的消融实验来进行讨论。

表(a)是对我们方法核心所需的自适应性的探究,不管是采样位置(loc.)还是解码内容(cont.)的适应性都对我们最终模型的表现有着大幅的影响。
表(b)是对我们提出的adaptive mixing的探究,动态通道混合(ACM)和动态空间混合(ASM)的顺序组合是最佳选择。
表(c)是我们的AdaMixer再加上不同的多尺度交互网络的效果,我们很惊讶地发现不加额外的金字塔网络居然效果还比较好,我们猜测可能是因为我们的AdaMixer解码器自然具有多尺度交互的能力且额外的金字塔网络有着更多的参数需要更多的训练时间来收敛。
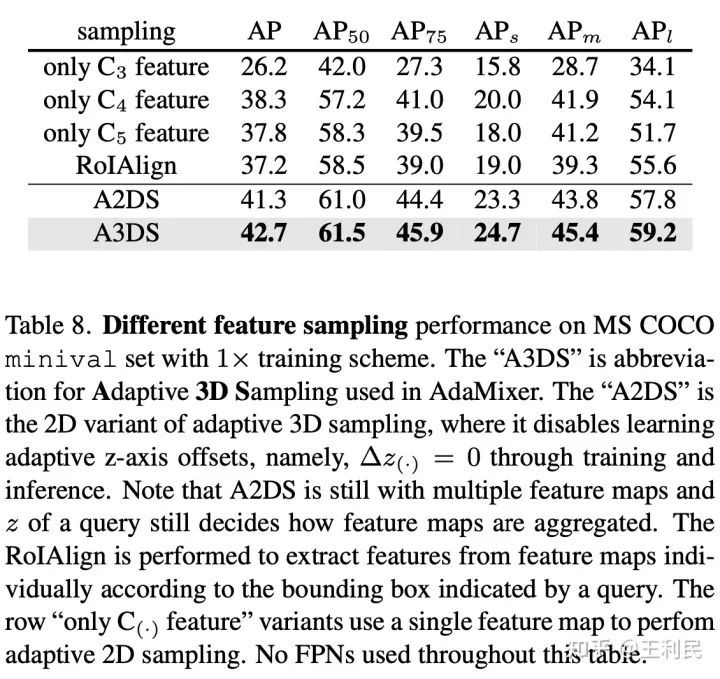
表8进一步探究了3D特征空间采样。注意到表8中实验模型都没有配备FPN网络,在这种情况下RoIAlign的表现效果较差在我们的情理之中。自适应2D采样(不学习z方向上的offset)的模型落后了3D特征空间采样将近1.5个AP,说明了3D采样尤其是z方向上学习offset的必要性。另外,另一个很有意思的结论是只用C4特征要比C5要好,这可能归功于C4特征的分辨率较大。而且只用C4特征时,可以把ResNet的后续特征提取阶段直接砍掉(因为没有FPN,也用不到C5特征图了),这可能代表着此类检测器轻量化可以涉及的方向?我们还未做过多探究。
总结
我们提出了一个具有相对简单结构、快速收敛且表现不俗的检测器AdaMixer,通过改善解码器对目标物体的自适应解码能力,我们的AdaMixer无需引入厚重的注意力编码器以及显式的多尺度交互网络。我们希望AdaMixer可以作为后续基于query的检测器简单有效的基线模型。
公众号后台回复“画图模板”获取90+深度学习画图模板~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
