
下载kaggle数据集的小妙招
这个平台上有很多接近现实业务场景的数据集,非常适合练手。
今天向大家推荐一个下载kaggle数据集的小工具——kaggleAPI
配置好之后,可以写个脚本,以后下载数据就方便多了。
安装
pip install kaggle
安装完毕之后执行
kaggle compeitions list
然后就会报错,提示没有kaggle.json文件,不用理他。
这一步主要是让其运行后生成配置文件夹,一般在C盘-用户-用户名下的.kaggle
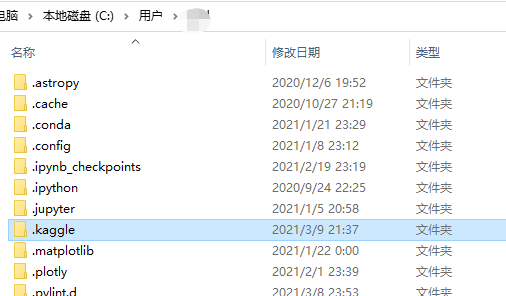
配置
登录kaggle官网 右上角头像处点击,选择Account
右上角头像处点击,选择Account 进去之后滚动到最下面API处,选择Create New API Token
进去之后滚动到最下面API处,选择Create New API Token

然后就会自动下载一个kaggle.json文件,另存到第一步那个.kaggle文件夹
下载数据集
再执行以下
kaggle compeitions list
可以看到近期的一些竞赛,重点关注以下奖金😃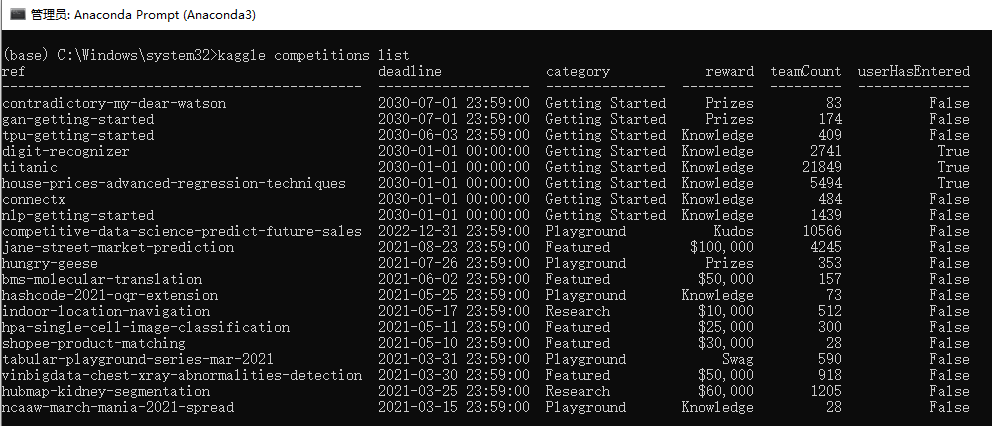
除了list,kaggle competitions 还有一些其他用法,不展开讲了。
kaggle competitions {list, files, download, submit, submissions, leaderboard}
大家最关心的数据集下载
kaggle datasets{list,files,download,create,version,init,metadata,status}
比较常用的是:list(可用数据集列表)、files(数据文件)、download(下载)
kaggle datasets list
用法
usage: kaggle datasets list [-h] [--sort-by SORT_BY]
[--size SIZE] [--file-type FILE_TYPE] [--license LICENSE_NAME]
[--tags TaG_IDS] [-s SEARCH] [-m] [--user USER] [-p PAGE] [-v]
这个里面还有2个常用的参数:-s 搜索,后面可以加关键词;-p 展示多少行,默认是20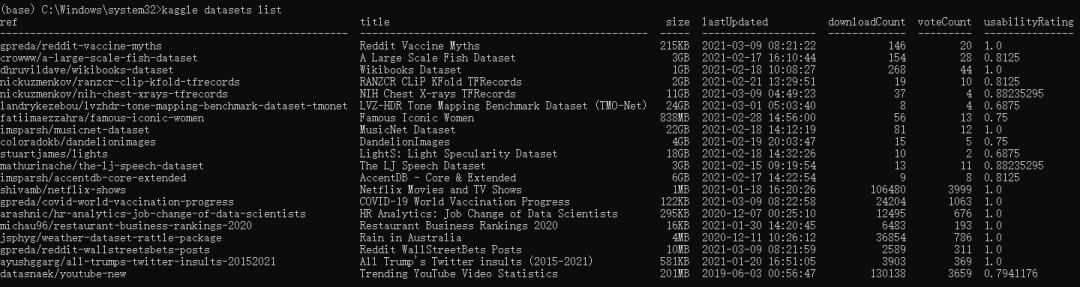
kaggle datasets download
用法
usage: kaggle datasets download
[-h] [-f FILE_NAME] [-p PATH] [-w] [--unzip]
[-o] [-q][dataset]
更真实的用法
如果单纯在cmd执行个下载指令就大材小用了,我们还可以用kaggleAPI写shell脚本完成更复杂的用法,比如:
#!/bin/sh
DATASET="noxmoon/chinese-official-daily-news-since-2016"
ARCHIVE_FILE="chinese-official-daily-news-since-2016.zip"
DATA_FILE="chinese_news.csv"
DATA_DIR="data"
COL_NAME="headline"
LINES=3000
OUTPUT_FILE="headlines.txt"
if [ -d ${DATA_DIR} ]; then
echo ${DATA_DIR}' exists, please remove it before running the script'
exit 1
fi
echo "Creating dir"
mkdir -p ${DATA_DIR}
cd ${DATA_DIR}
kaggle datasets download -d ${DATASET}
unzip ${ARCHIVE_FILE}
echo "Deleting original dataset archive"
rm -f ${ARCHIVE_FILE}
echo "Extracting, cutting, shuffling data"
awk -v col=$COL_NAME -F "\"*,\"*" '{print $COL_NAME}' $DATA_FILE | shuf -n 3000 > ${OUTPUT_FILE}
下载-解压一气呵成!
如有收获,欢迎给个在看!转发!
推荐阅读 误执行了rm -fr /*之后,除了跑路还能怎么办?! 程序员必备58个网站汇总 大幅提高生产力:你需要了解的十大Jupyter Lab插件
评论