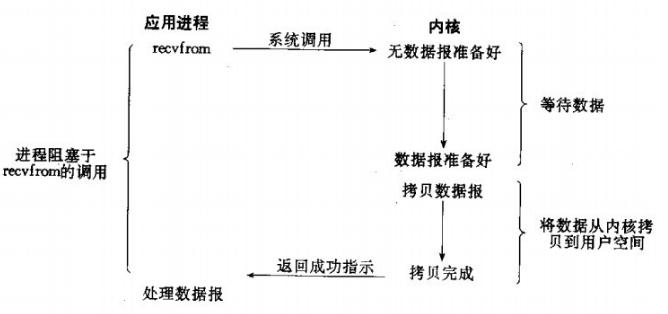
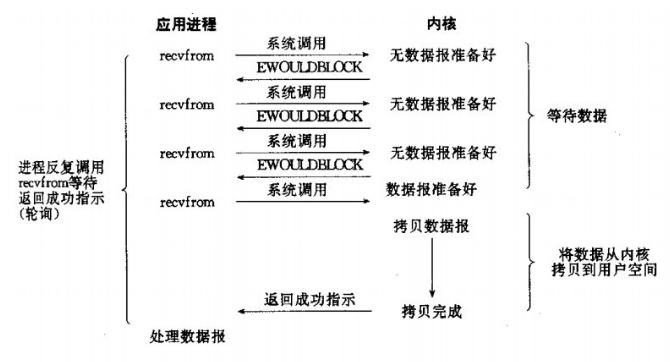
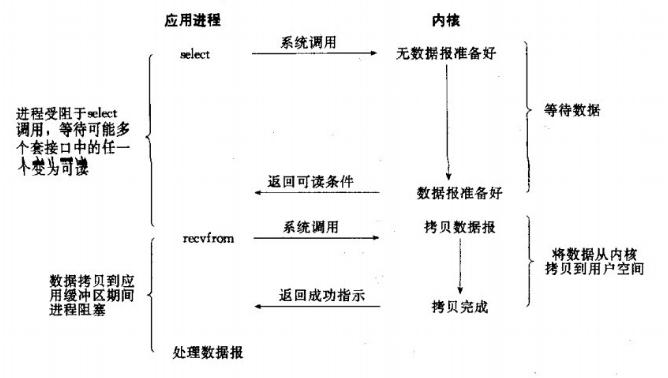
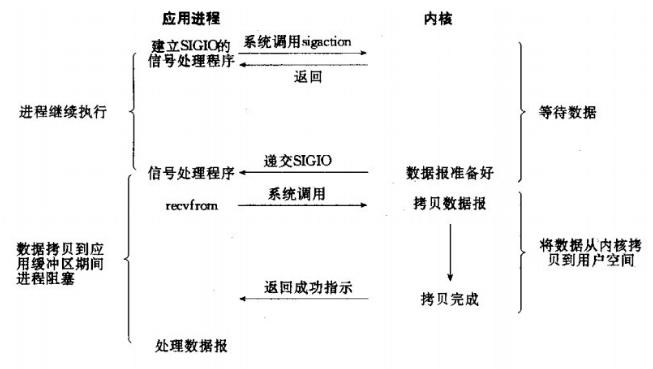
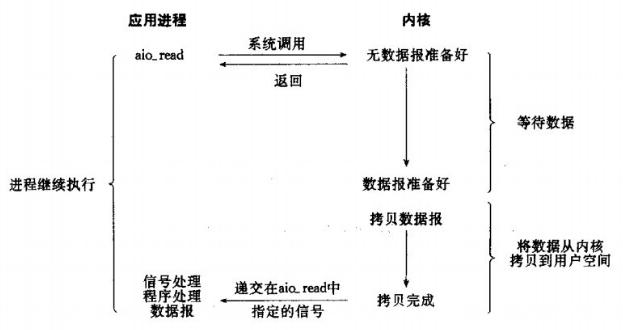
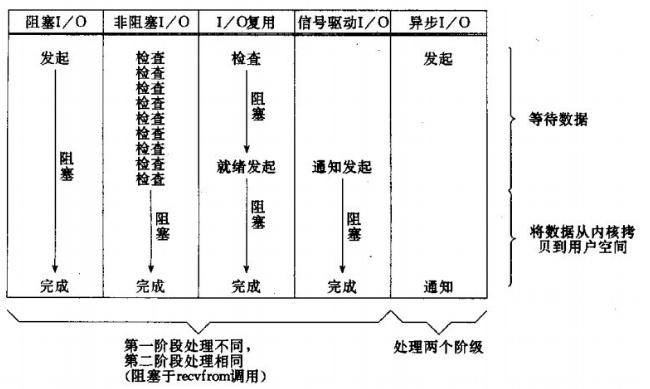
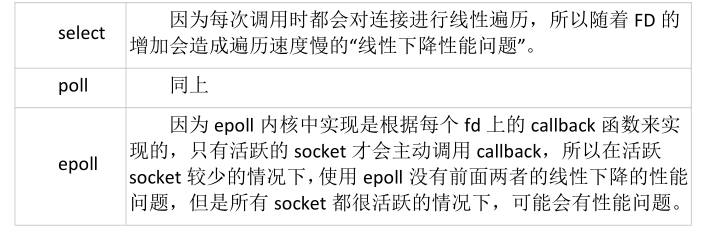
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。 所以说,当一个read操作发生时,它会经历两个阶段: 第一阶段:等待数据准备 (Waiting for the data to be ready)。第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。对于socket流而言, 第一步:通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。第二步:把数据从内核缓冲区复制到应用进程缓冲区。网络应用需要处理的无非就是两大类问题,网络IO,数据计算。相对于后者,网络IO的延迟,给应用带来的性能瓶颈大于后者。 网络IO的模型大致有如下几种:· 同步模型(synchronous IO)· 阻塞IO(bloking IO)· 非阻塞IO(non-blocking IO)· 多路复用IO(multiplexing IO)· 信号驱动式IO(signal-driven IO)· 异步IO(asynchronous IO)注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。


 下载APP
下载APP