
深入聊聊Linux 五种IO模型


一、相关概念讲解
1、同步与异步
2、堵塞与非堵塞
3、用户空间与内核空间
4、进程切换
5、进程的堵塞
6、文件描述符
7、缓存
二、IO模型
1、堵塞IO模型
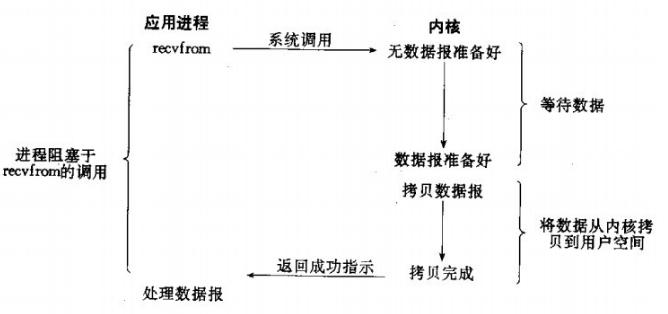
2、非堵塞IO模型
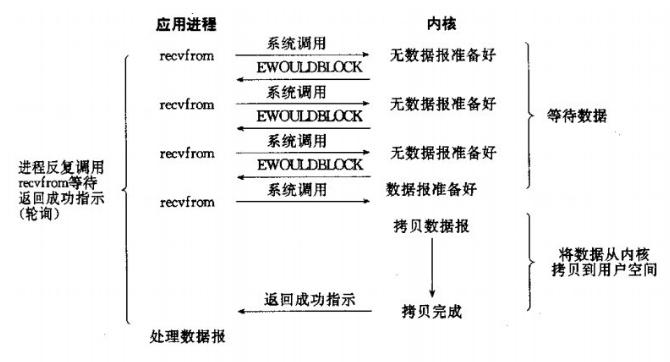
3、IO 复用模型
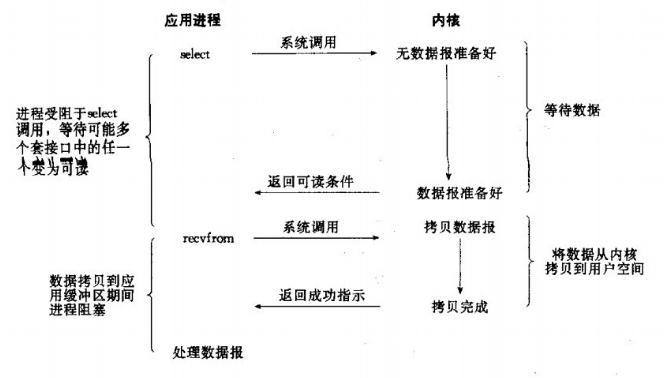
3、信号驱动IO
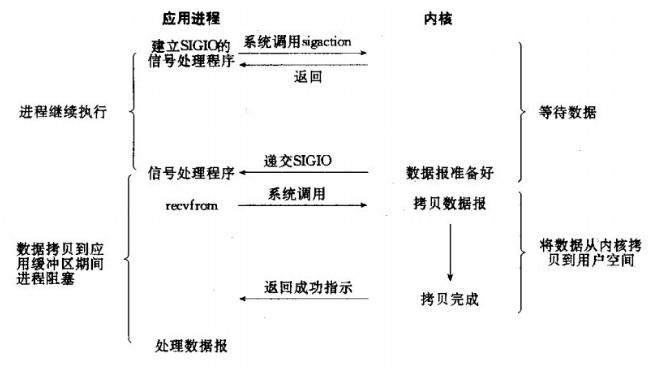
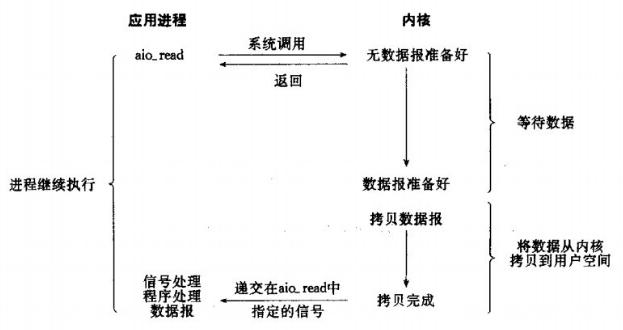
4、异步IO模型
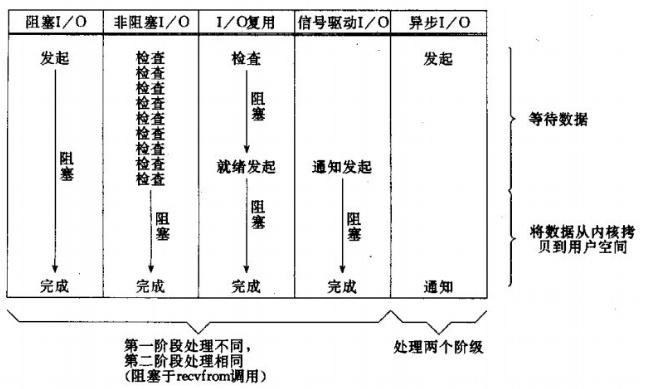
5、5种I/O模型的比较
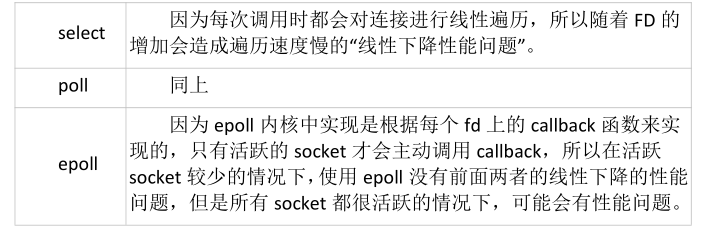
三、select 、poll 、epoll的区别?


相关阅读:
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。

评论