
这样讲解Linux的五种io模型,应该通俗易懂


今天分享Linux系统的io模型。Linux总共有5种io模型,分别是:
blocking IO 阻塞IO模型 On Blocking IO 非阻塞IO模型 IO multiplexing 多路复用IO模型 singnal dirven 信号驱动IO模型 asyn 异步IO模型
我们首先来了解一下几个基本的概念:
阻塞:阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。换成一句白话,可以这样说:调用我(函数),我(函数)没有接收完数据或者没有得到结果之前,我不会返回。 非阻塞:非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。换成一句白话,可以这样说:调用我(函数),我(函数)立即返回,通过select通知调用者 同步:所谓同步,就是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做,等前一件做完了才能做下一件事。换成一句白话,可以这样说:我调用一个功能,该功能没有结束前,我死等结果。 异步:异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。换成一句白话,可以这样说:我调用一个功能,不需要知道该功能结果,该功能有结果后通知我(回调通知)
阻塞IO
简单看下执行流程:
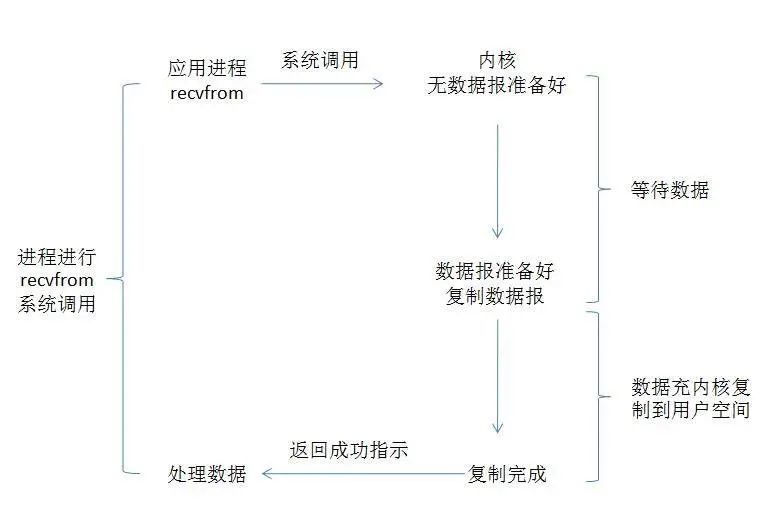
流程:在整个过程中,当用户进程进行系统调用时,内核就开始了I/O的第一个阶段,准备数据到缓冲区中,当数据都准备完成后,则将数据从内核缓冲区中拷贝到用户进程的内存中,这时用户进程才解除block的状态重新运行。
非阻塞IO模型

通过上图流程图,大致经历两个阶段:
等待数据阶段:未阻塞, 用户进程需要盲等,不停的去轮询内核。 数据复制阶段:阻塞,此时进行数据复制。在这两个阶段中,用户进程只有在数据复制阶段被阻塞了,而等待数据阶段没有阻塞,但是用户进程需要盲等,不停地轮询内核,看数据是否准备好。
IO多路复用
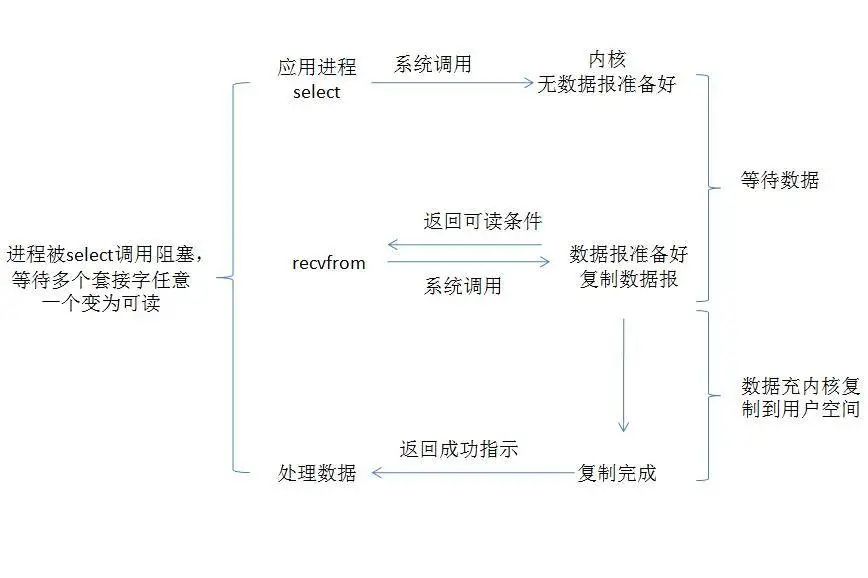
从上图可以看到在I/O复用模型中,由于同步非阻塞方式需要不断主动轮询,轮询占据了很大一部分过程,轮询会消耗大量的CPU时间,而 “后台” 可能有多个任务在同时进行,
相比于阻塞IO模型,多路复用只是多了一个select/poll/epoll函数。select函数会不断地轮询自己所负责的文件描述符/套接字的到达状态,当某个套接字就绪时,就对这个套接字进行处理。select负责轮询等待,recvfrom负责拷贝。当用户进程调用该select,select会监听所有注册好的IO,如果所有IO都没注册好,调用进程就阻塞。
对于客户端来说,一般感受不到阻塞,因为请求来了,可以用放到线程池里执行;但对于执行select的操作系统而言,是阻塞的,需要阻塞地等待某个套接字变为可读。
IO多路复用其实是阻塞在select,poll,epoll这类系统调用上的,复用的是执行select,poll,epoll的线程。
从整个IO过程来看,他们都是顺序执行的,因此可以归为同步模型(synchronous)。都是进程主动等待且向内核检查状态。
信号驱动IO
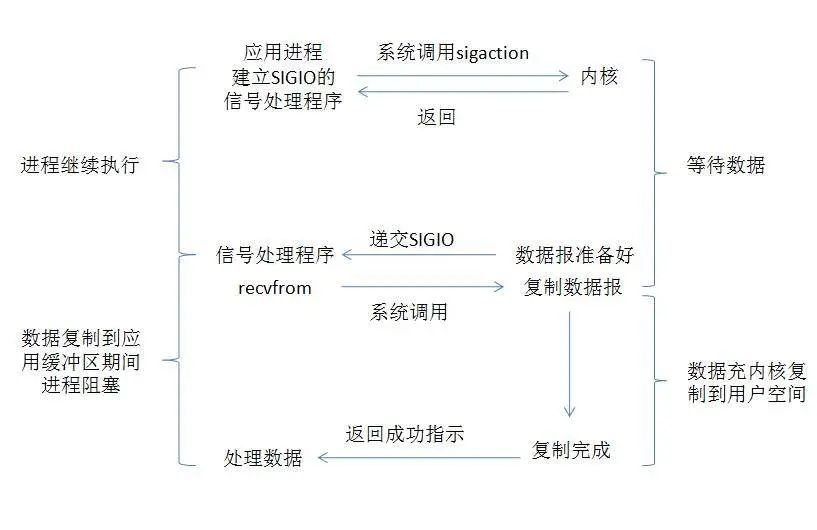
从上图可以看出,只有在I/O执行的第二阶段阻塞了用户进程,而在第一阶段是没有阻塞的。该模型在I/O执行的第一阶段,当数据准备完成之后,会主动的通知用户进程数据已经准备完成,即对用户进程做一个回调。该通知分为两种,一为水平触发,即如果用户进程不响应则会一直发送通知,二为边缘触发,即只通知一次。
该模型也分为两个阶段:
数据准备阶段:未阻塞,当数据准备完成之后,会主动的通知用户进程数据已经准备完成,对用户进程做一个回调。 数据拷贝阶段:阻塞用户进程,等待数据拷贝。
异步IO
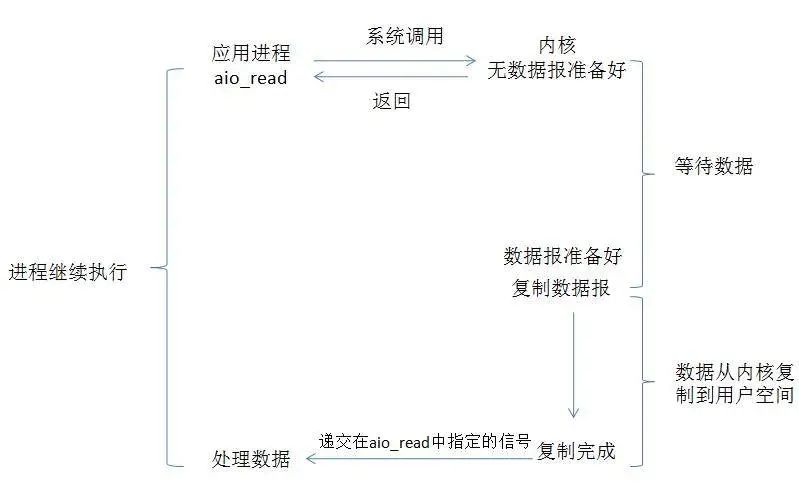
就是用户进程发起系统调用后,立刻就可以开始去做其他的事情,然后直到I/O数据准备好并复制完成后,内核会给用户进程发送通知,告诉用户进程操作已经完成了。
特点:
异步I/O执行的两个阶段都不会阻塞读写操作,由内核完成。 完成后内核将数据放到指定的缓冲区,通知应用程序来取。
总结
阻塞IO和非阻塞IO的区别:数据准备的过程中,进程是否阻塞。
同步IO和异步IO的区别:数据拷贝的过程中,进程是否阻塞。
从效率上来说,可以简单理解为阻塞IO<非阻塞IO<多路复用IO<信号驱动IO<异步IO。从同步和异步来说,只有异步IO模型是异步的,其他均为同步。
推荐阅读:
5T技术资源大放送!包括但不限于:C/C++,Linux,Python,Java,PHP,人工智能,单片机,树莓派,等等。在公众号内回复「1024」,即可免费获取!!