
使用 Langchain-Chatchat 搭建本地知识库问答系统
共 2539字,需浏览 6分钟
· 2024-04-10


一、LangChain-Chatchat
基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
因为咱们经年累月积累的文献阅读笔记,本地知识库特别适合咱们科研群体。不过目前本地部署受限于电脑性能, 使用受限, 但不远的未来应该会有一些收费的在线知识库应用。
✅ 依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
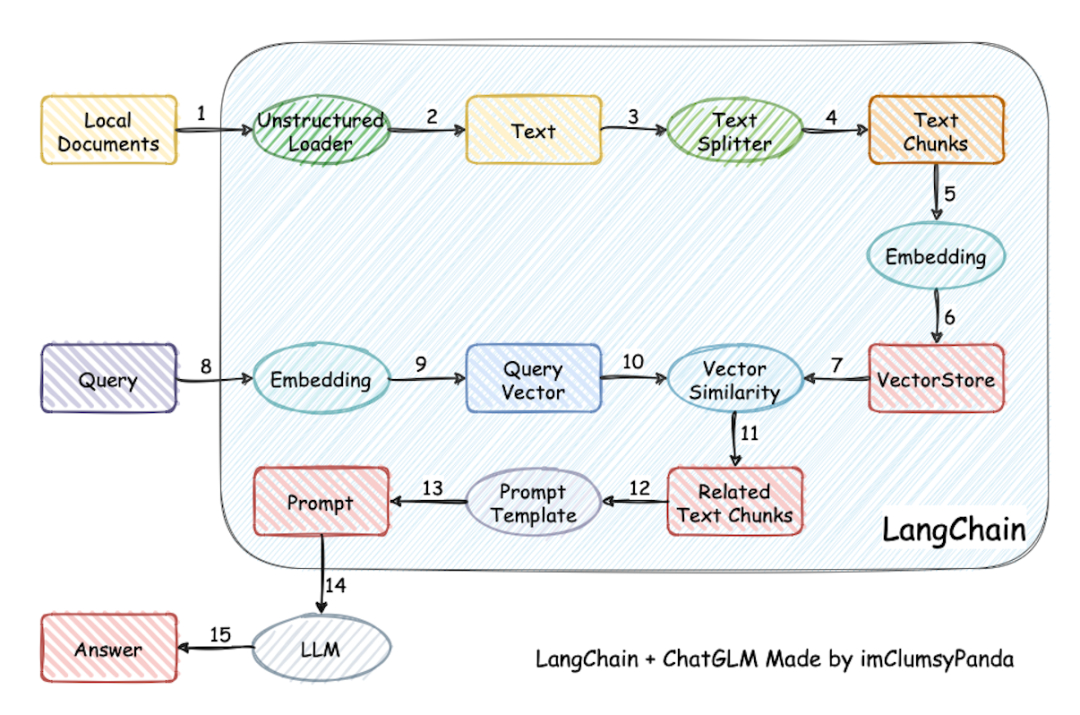
本项目实现原理如下图所示,过程包括 加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
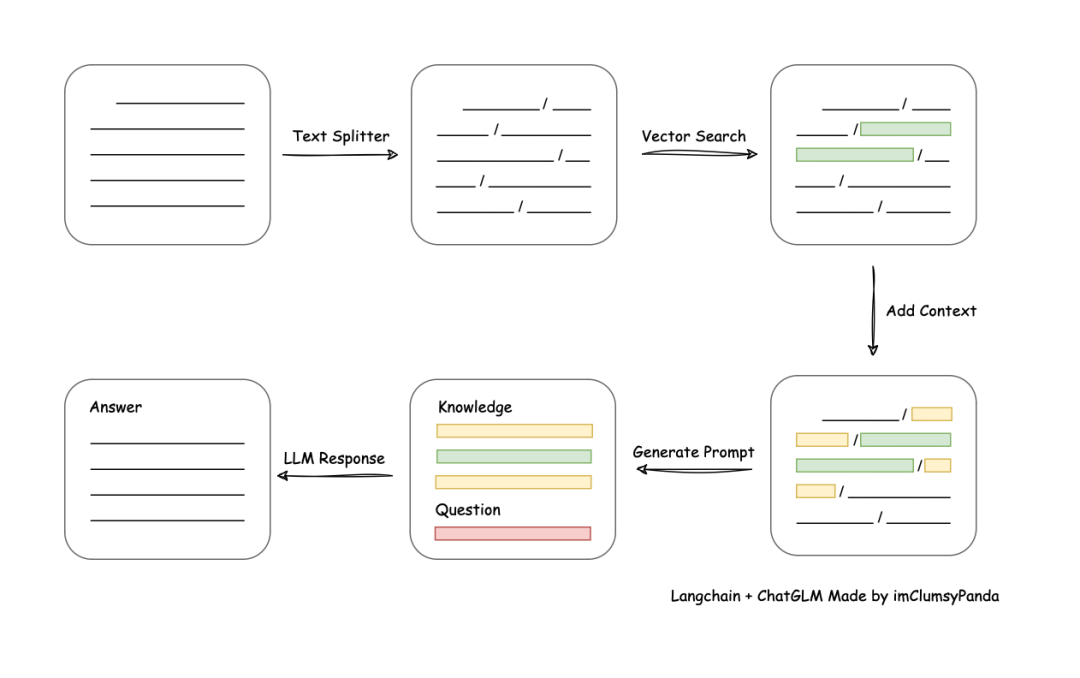
从文档处理角度来看,实现流程如下:
二、搭建步骤
2.1 环境配置
强烈推荐使用 Python3.11, 创建一个虚拟环境,并在虚拟环境内安装项目的依赖。需要注意电脑显存要大于12G, 不然该项目跑不动。
# 拉取仓库
$ git clone https://github.com/chatchat-space/Langchain-Chatchat.git
# 进入目录
$ cd Langchain-Chatchat
# 安装全部依赖
$ pip install -r requirements.txt
$ pip install -r requirements_api.txt
$ pip install -r requirements_webui.txt
# 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
2.2 模型下载
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding 模型 BAAI/bge-large-zh 为例:
下载模型需要先安装 Git LFS ,然后运行
$ git lfs install
$ git clone https://huggingface.co/THUDM/chatglm3-6b
$ git clone https://huggingface.co/BAAI/bge-large-zh
2.3 初始化知识库和配置文件
按照下列方式初始化自己的知识库和简单的复制配置文件
$ python copy_config_example.py
$ python init_database.py --recreate-vs
2.4 一键启动
按照以下命令启动项目
$ python startup.py -a
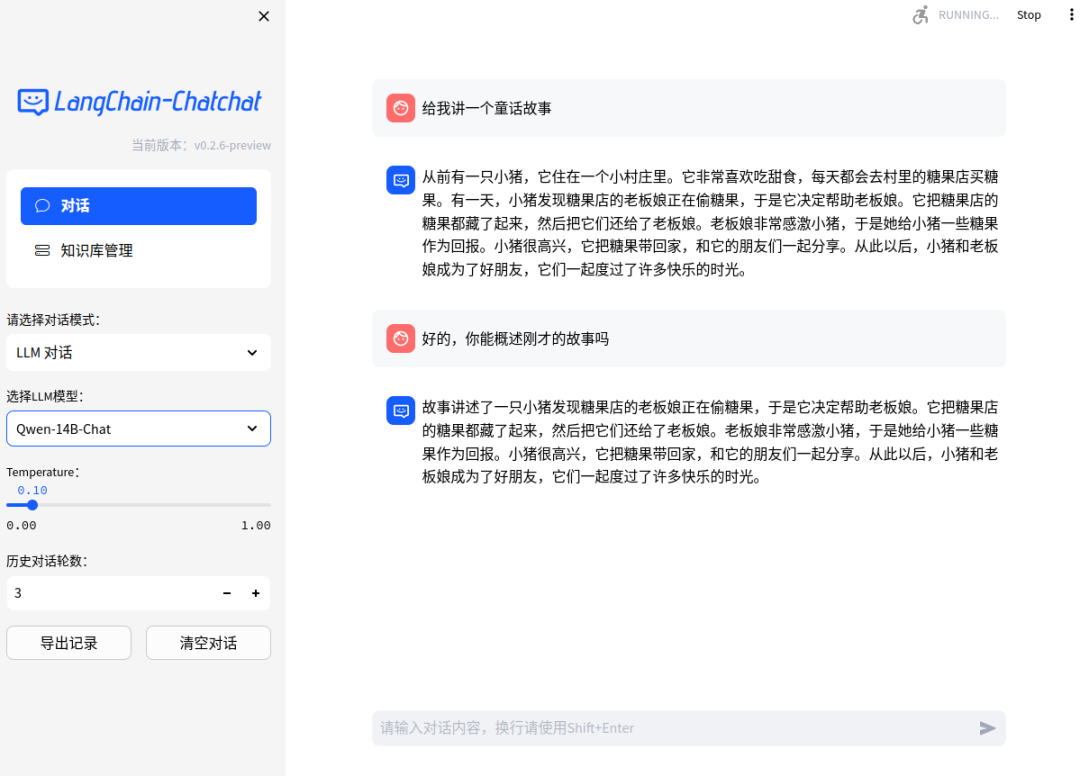
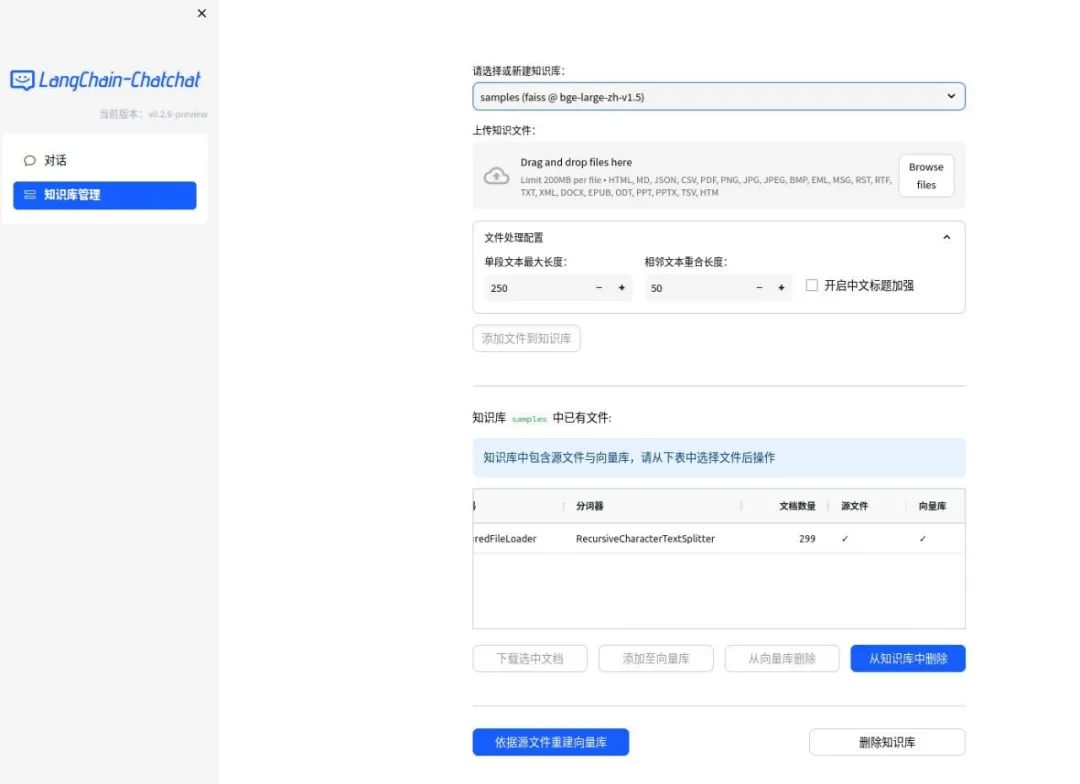
2.5 启动界面示例
如果正常启动,你将能看到以下界面
三、外包
如果电脑显存大于12G,不差钱但缺时间,可以在某鱼搜「langchain-chatchat」,配置费用大概100-200元。
精选内容
LIST | 社科(经管)可用数据集列表 LIST | 文本分析代码列表 LIST | 社科(经管)文本挖掘文献列表 管理科学学报 | 使用「软余弦相似度」测量业绩说明会「答非所问程度」 数据集 | 人民网政府留言板原始文本(2011-2023.12) 数据集 | 人民日报/经济日报/光明日报 等 7 家新闻数据集 可视化 | 人民日报语料反映七十年文化演变 数据集 | 2024年中国全国5级行政区划(省、市、县、镇、村) 数据集 | 三板上市公司年报2002-2023.12 数据集 | 人民网地方领导留言板原始文本(2011-2023.12) 数据集 | 3571万条专利申请数据集(1985-2022年) 数据集 | 专利转让数据集(1985-2021) 数据集 | 288w政府采购合同公告明细数据(2023.09) 数据集 | 用来练习pandas的招聘数据代码 | 使用 3571w 专利申请数据集构造面板数据 代码 | 使用「新闻数据集」计算 「经济政策不确定性」指数 数据集 | 国省市三级gov工作报告文本 代码 | 使用「新闻数据」生成概念词频「面板数据」 代码 | 使用 3571w 专利申请数据集构造面板数据 代码 | 使用gov工作报告生成数字化词频「面板数据」 Polars库 | 最强 Pandas 平替来了 cpca库 | 中国省、市区划匹配库 opencc | 中文简体、繁体转换库 可视化 | 使用 DataMapPlot 绘制数据地图