
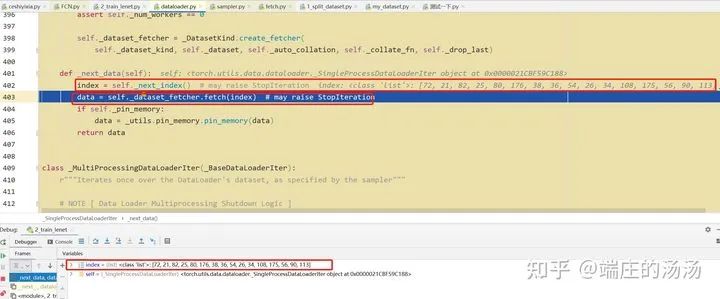
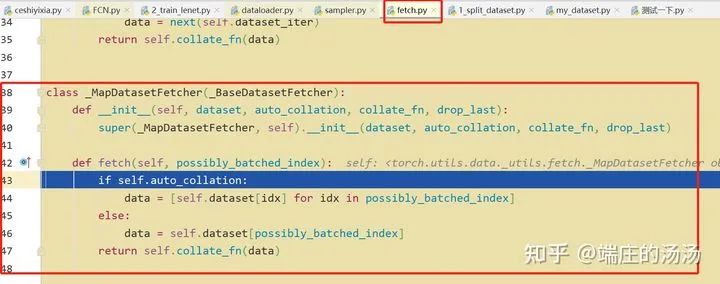
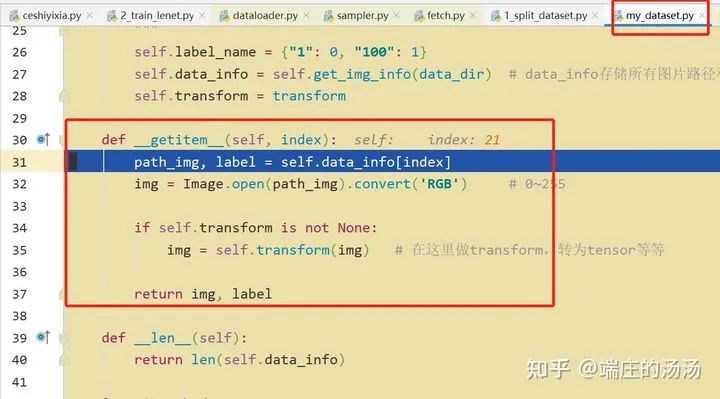
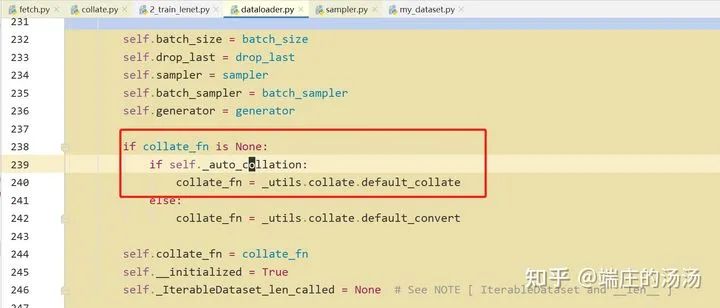
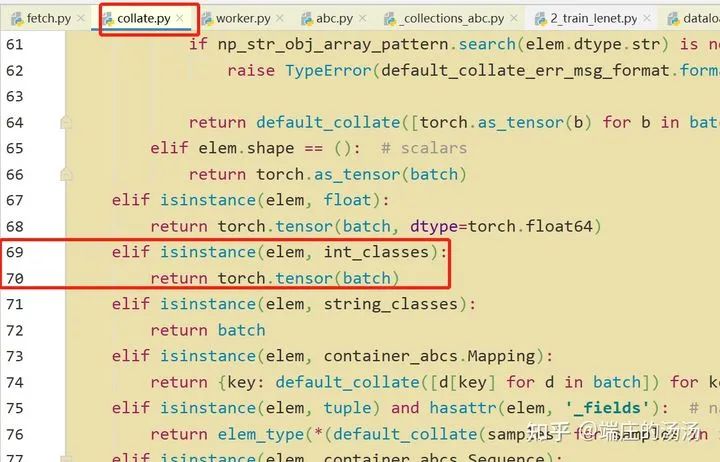
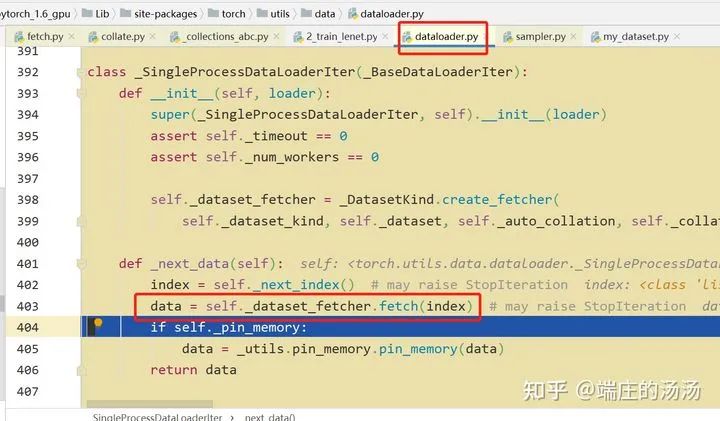
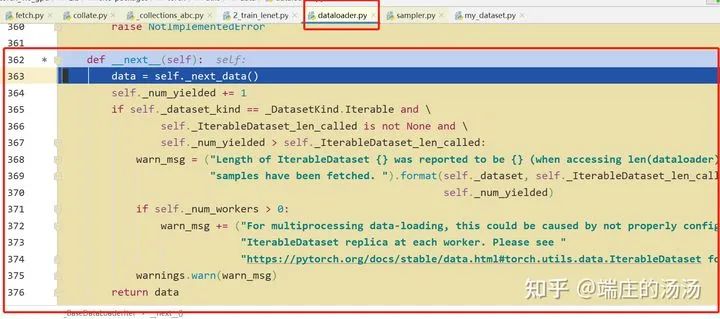
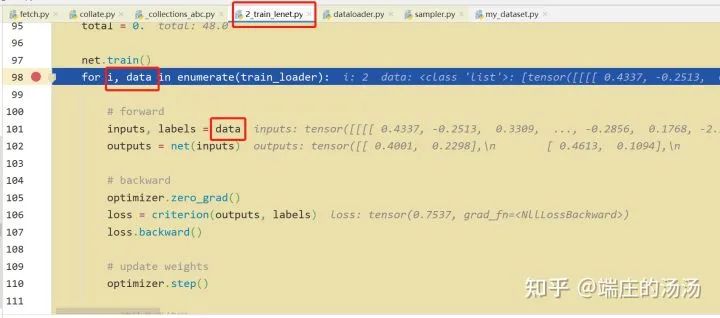
PyTorch DataSet 和 Dataloader 加载步骤
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!来源:知乎—端庄的汤汤 侵删

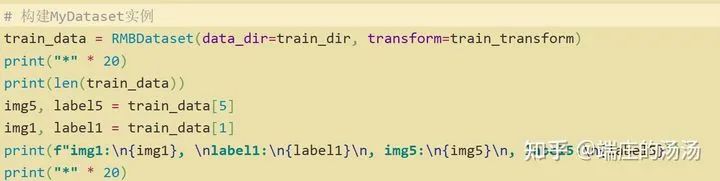
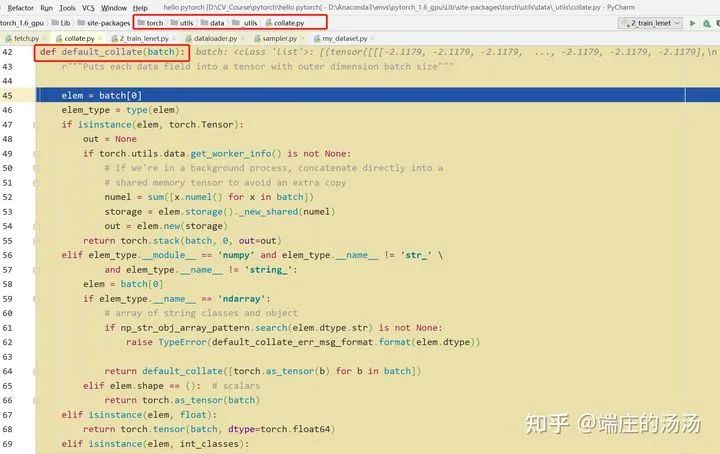
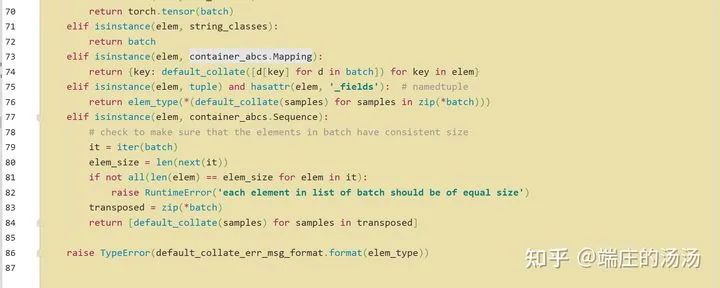
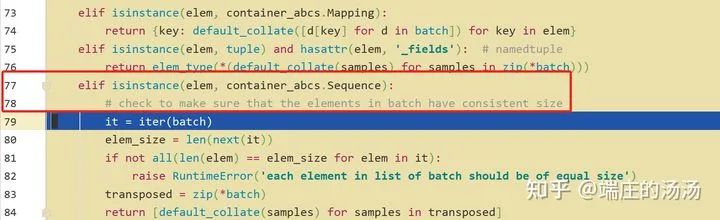
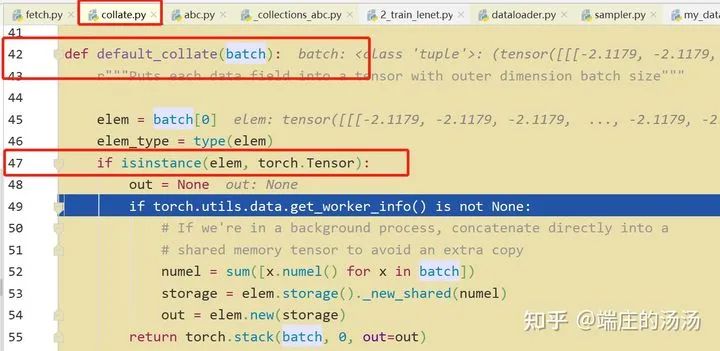
from torch.utils.data import Datasetclass MyDataset__(Dataset):def __init(self, *args, **kargs):passdef __len__(self):passdef __getitem__(self, idx):pass



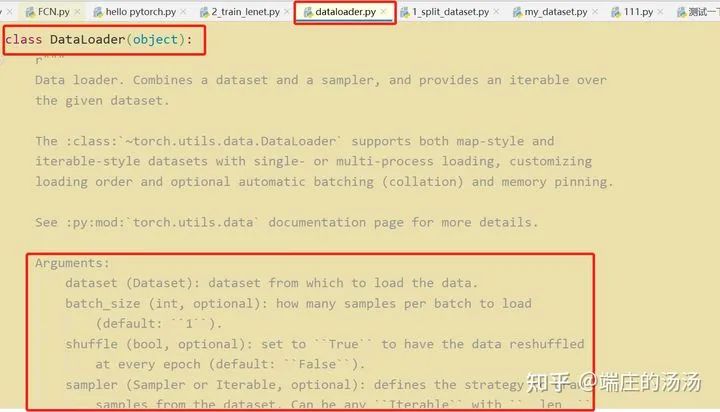

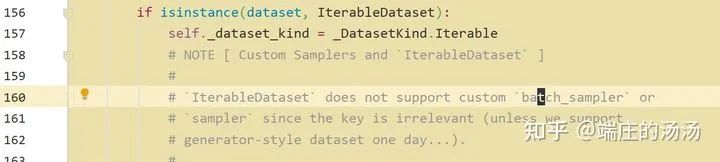
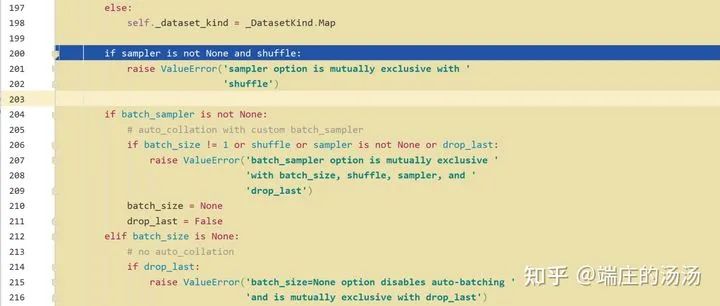

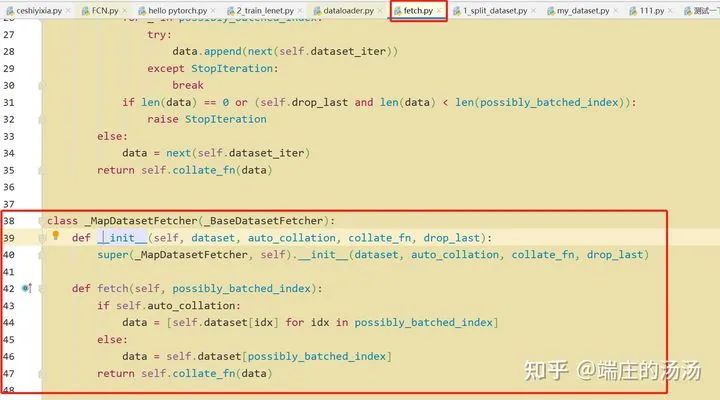
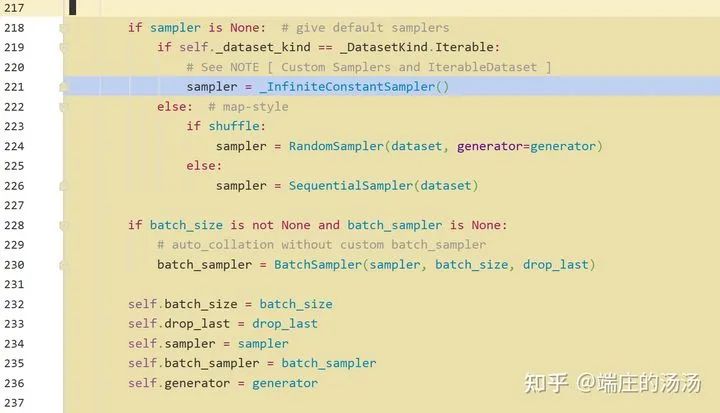
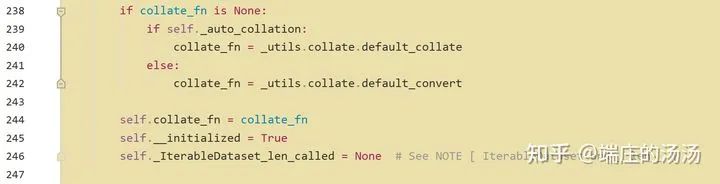
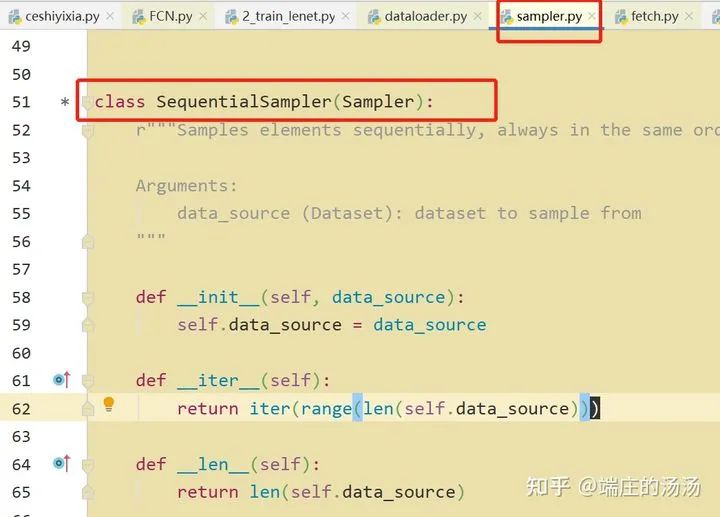
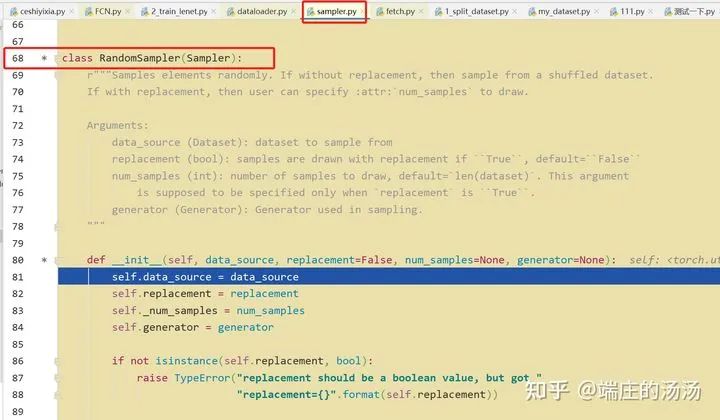
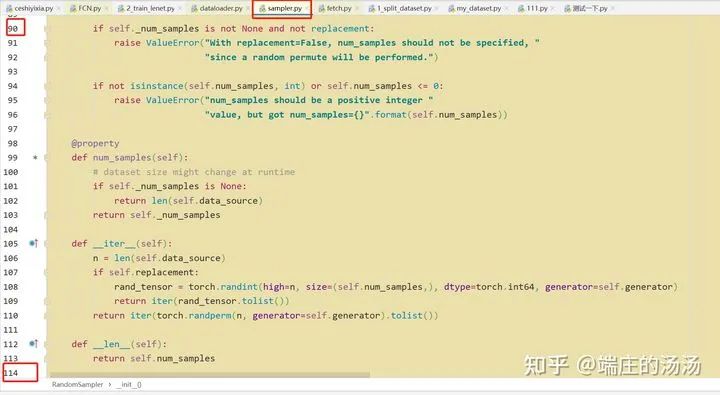
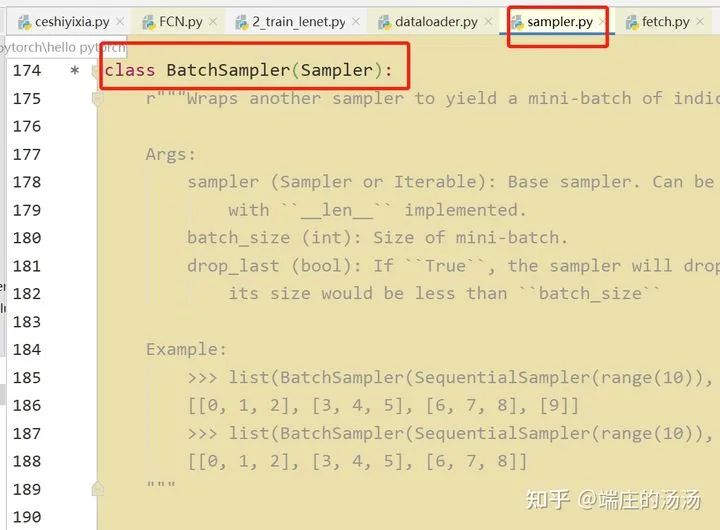
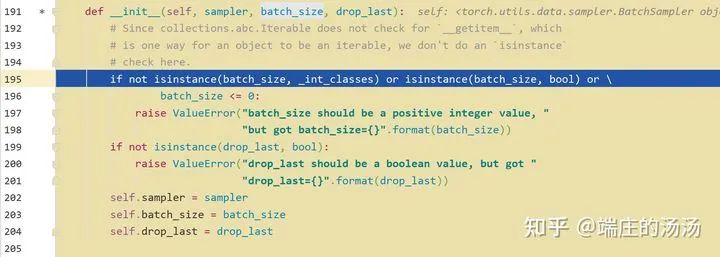
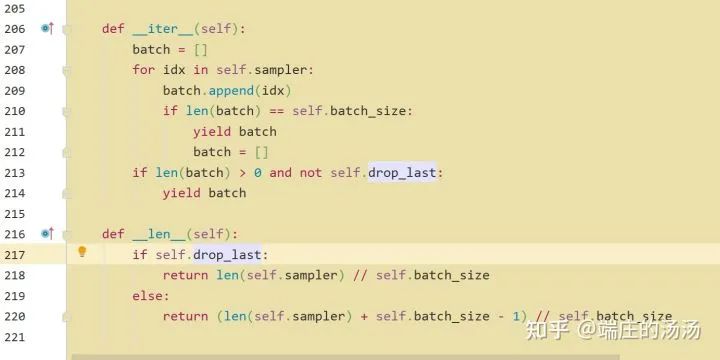
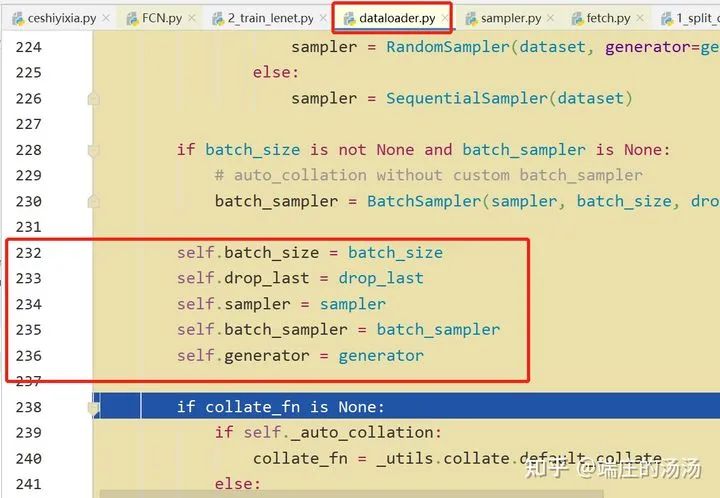

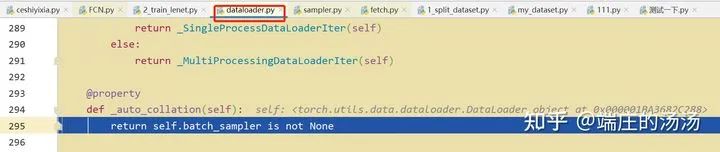
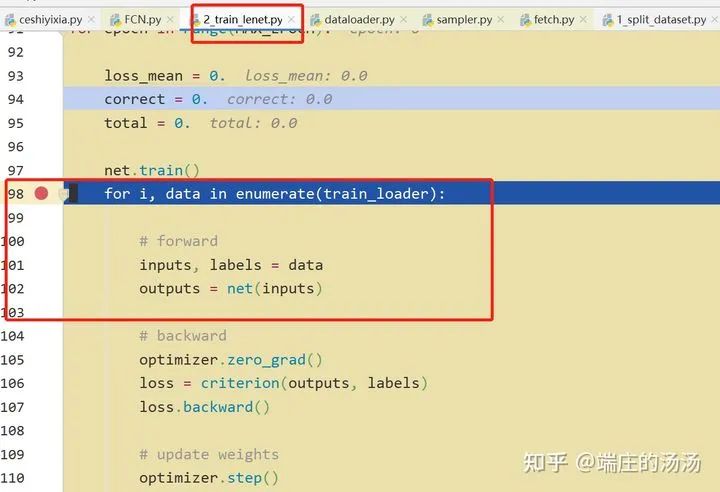
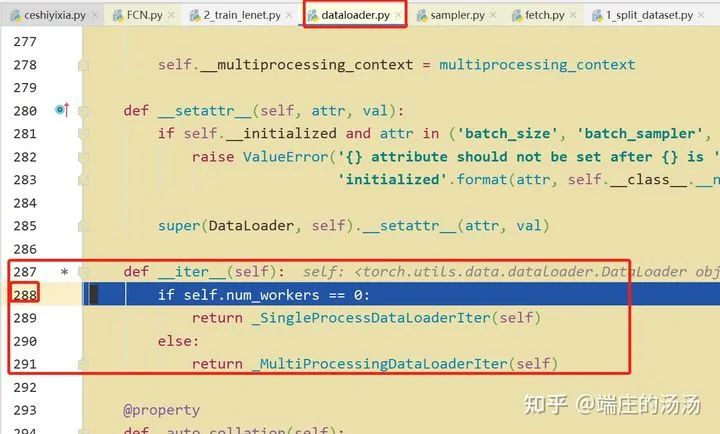
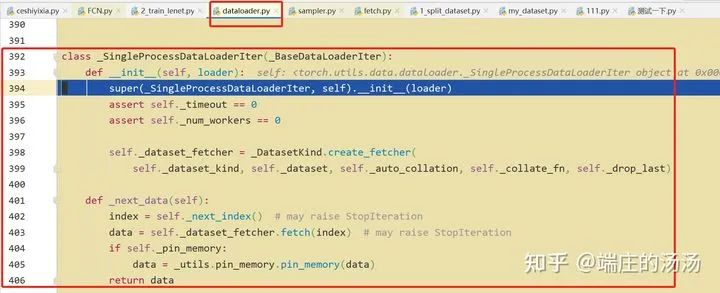
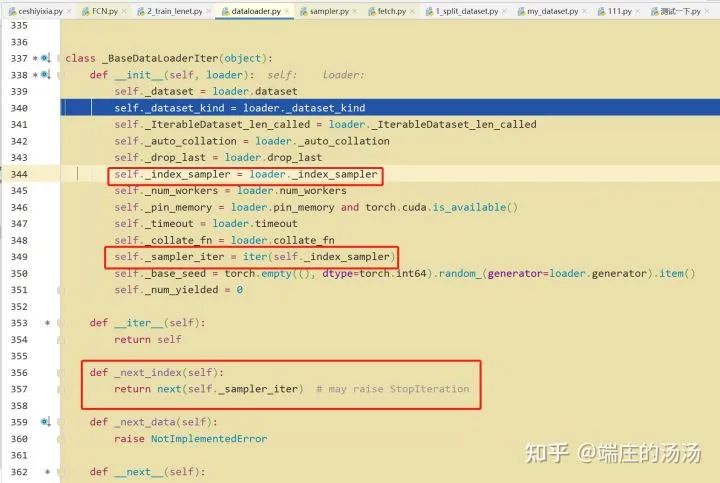
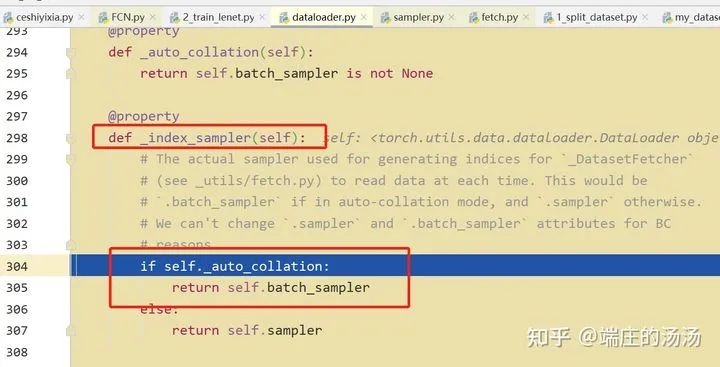
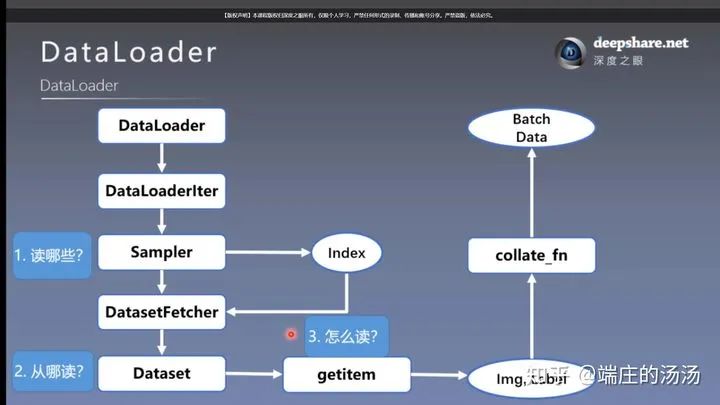
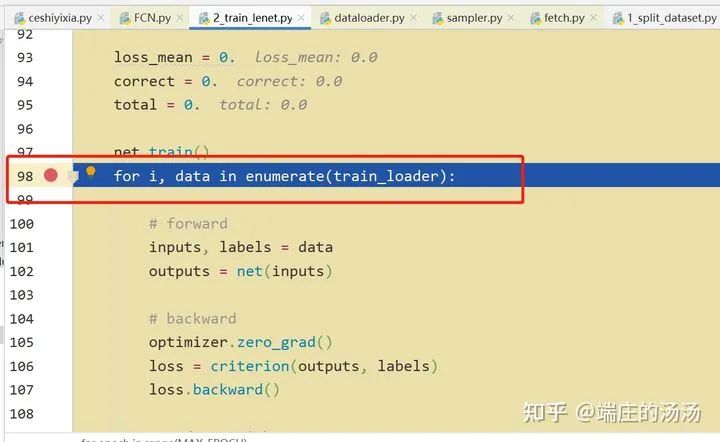
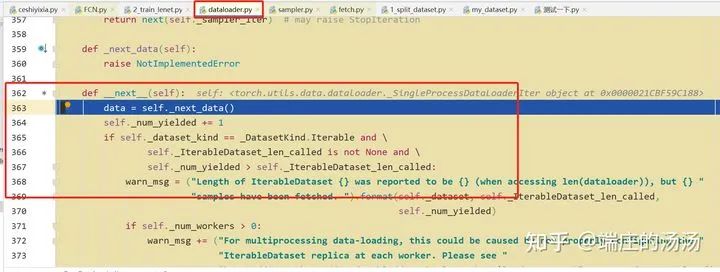
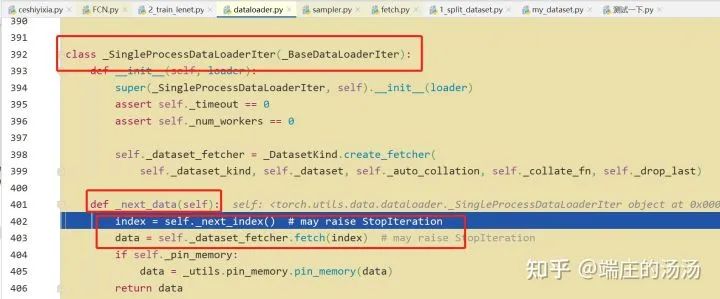
Iter()迭代器工厂函数,凡是有定义有__iter__()函数,或者支持序列访问协议,也就是定义有__getitem__()函数的对象 皆可以通过 iter()工厂函数 产生迭代器(iterable)对象。
原文链接:https://blog.csdn.net/weixin_36670529/article/details/106641754


猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
评论