
爬取B站20万+条弹幕,我学会了如何成为B站老司机
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
前言
B站(哔哩哔哩)是国内知名的视频弹幕网站,也是中国最大的年轻人聚集地之一,想要知道B站弹幕爱刷什么梗?不同分区UP主弹幕各有什么特点?如何快速成为B站弹幕老司机?本文就通过Python爬取B站不同UP主近20万+弹幕数据进行分析,全文共分为两个部分,第一部分为不同分区up主的弹幕分析,第二部分为Python爬取B站弹幕技术分析。
弹幕分析
户外区-华农兄弟
首先是户外区up主,我们选择了华农兄弟,虽然往期类似竹鼠中暑、母鸡发烧、打架内伤等视频弹幕很多,但最近的弹幕大多为考古等重复数据,因此为了追踪近期弹幕热点,我们选择近期播放量较高的视频来进行分析(2020-07-07)
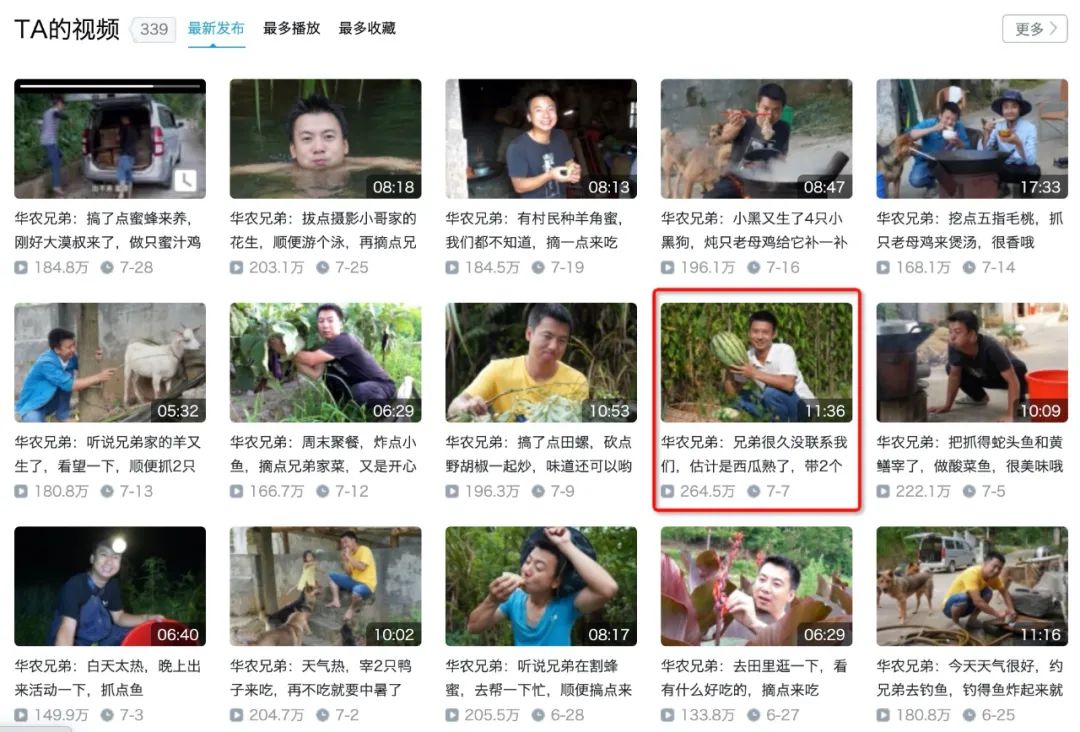
因b站限制每天只能获取1500条,因此本文一共爬取了自7.7日发布以来共24天36000条弹幕,并制作成词云图如下(点击图片可以直达该视频播放)
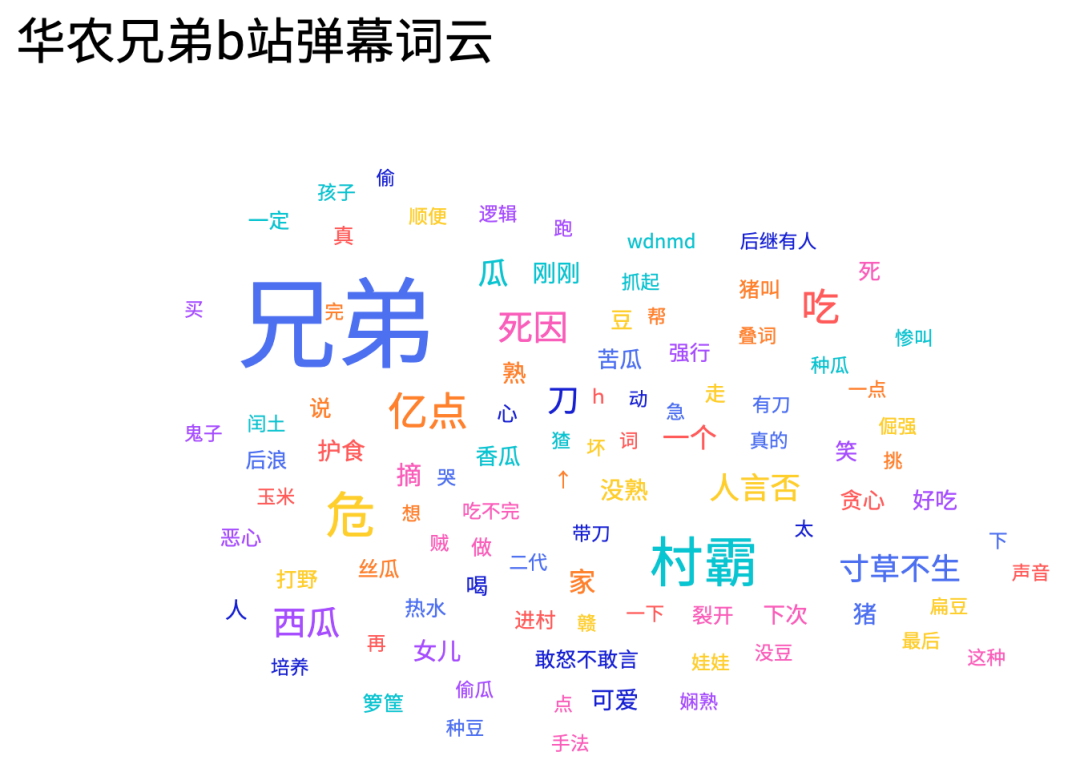
可以看到,弹幕刷的最多的就是 兄弟 ,毕竟兄弟家的就是我家的 ,其次就是村霸、危、亿点点、死因 等专属与华农兄弟的梗,还有类似于人言否、寸草不生、兄弟敢怒不敢言 等关键词也是弹幕爱刷的,学会了吗
,其次就是村霸、危、亿点点、死因 等专属与华农兄弟的梗,还有类似于人言否、寸草不生、兄弟敢怒不敢言 等关键词也是弹幕爱刷的,学会了吗
知识区-罗翔
接下来是最近在b站知识区很火的罗翔老师,直接搜索罗翔出来的大多是正儿八经刑法课,要想正确混入弹幕区还需搜索张三
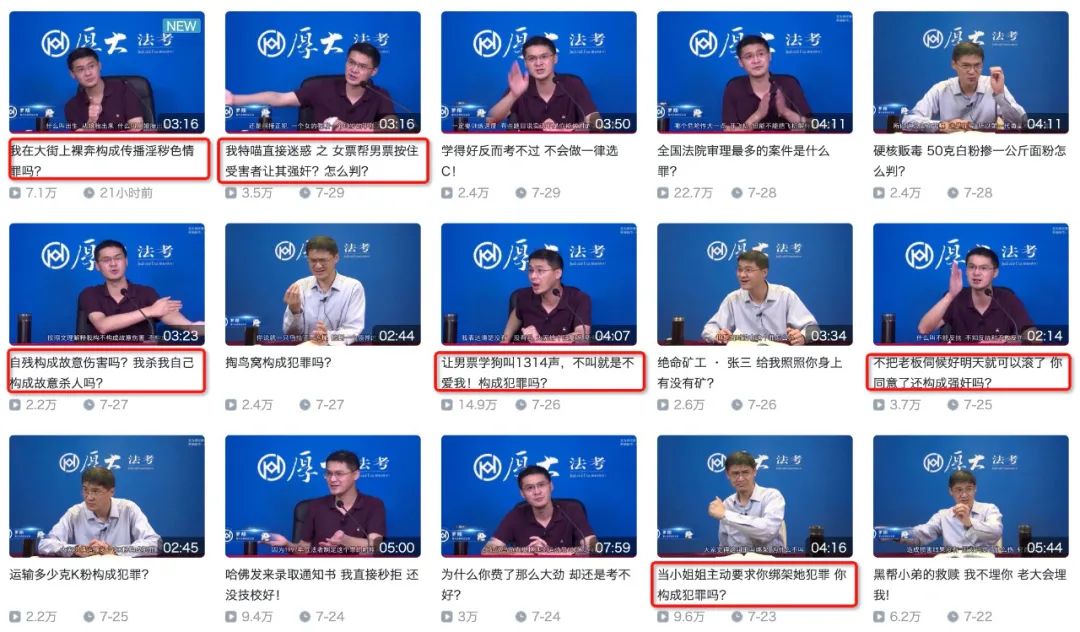
从标题就能看到每一个视频都不简单,我们找到播放量较高的一个视频?
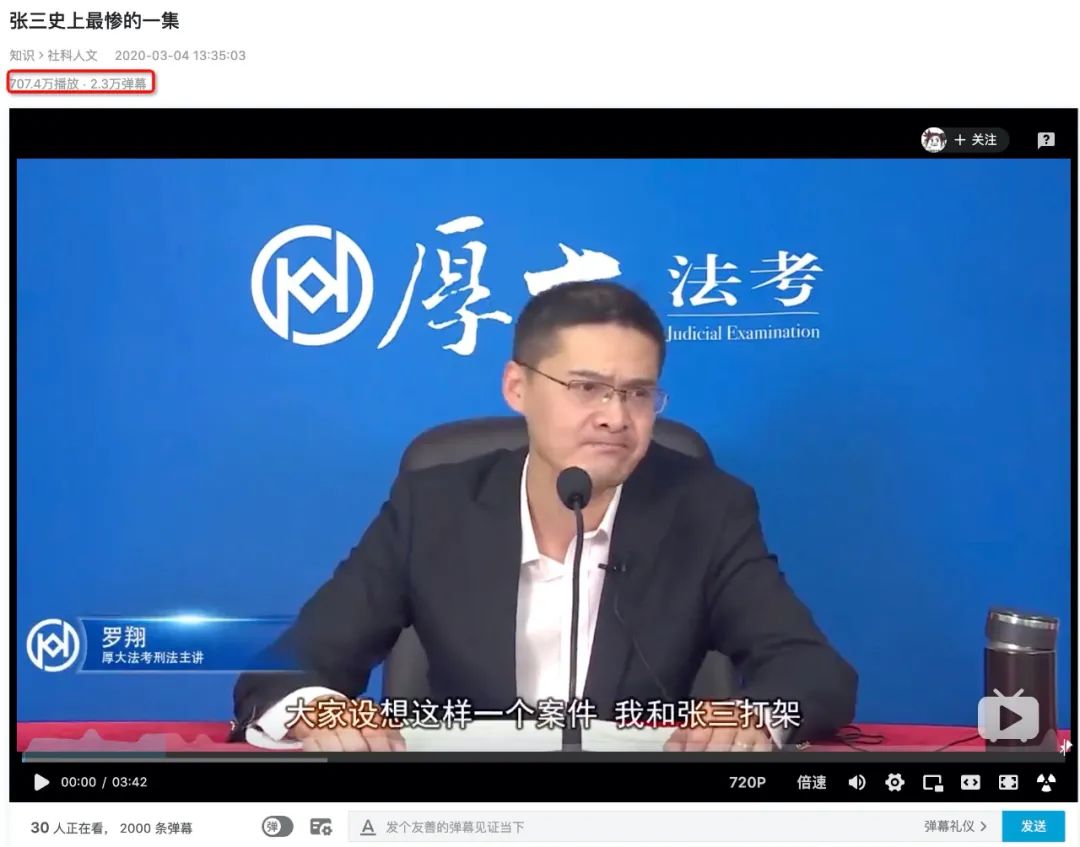
该视频讲述了张三的多种死法,截止7.30日共获得700万+播放,实时2万+弹幕,我们爬取近两个月每天1500条共60000条弹幕并制作成词云图如下(点击图片可以直达该视频播放)

可以看到,除了满屏的哈哈哈,哈哈哈哈之外,开门见三、法外狂徒张三也是弹幕爱发的,其次还有类似于好惨啊、张三太惨、泪目等看上去心疼张三的弹幕。当然众所周知十个泪目九个笑,还有一个在狂笑。同时我们可以发现在华农兄弟弹幕区爱刷的死因来到罗老师这里成了死法,只不过一个是竹鼠的一百种死因一个是张三的一千种死法
另外和华农兄弟的全程村霸不同,由于罗老师的相关视频都是有具体的故事情节,所以视频不同时间段的弹幕热词并不一样,我们来看一下?
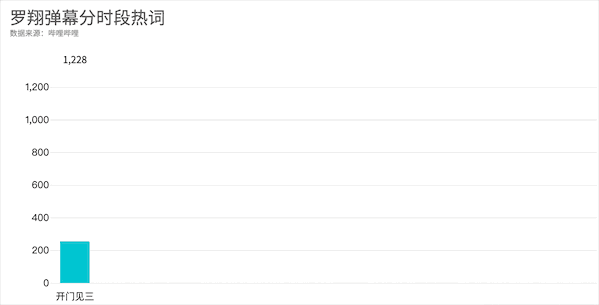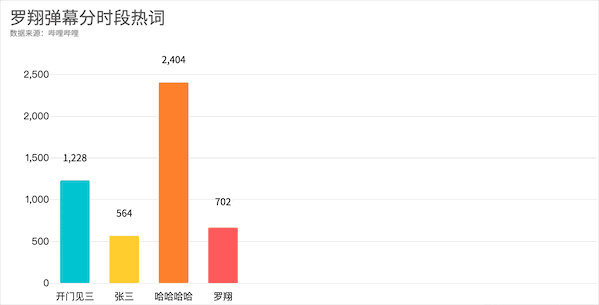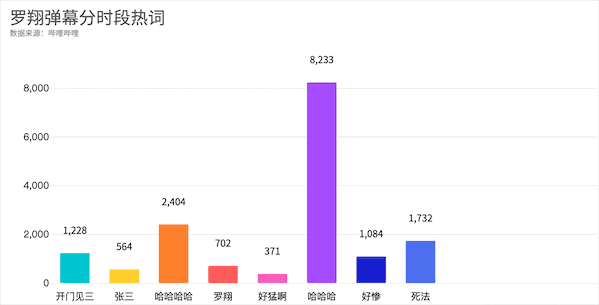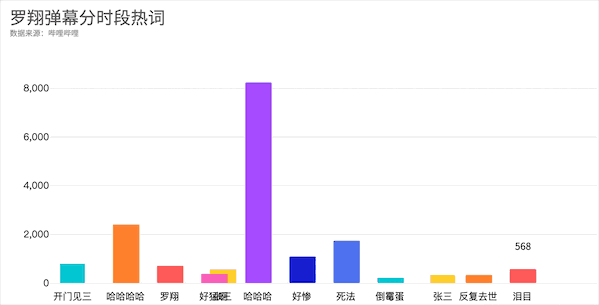
从视频开始的开门见三,到随着案件发展张三的惨死与哈哈哈,最后是满屏的泪目,你get到了吗
生活区-手工耿
接下来是生活区,我们选择手工达人手工耿近期的热门视频
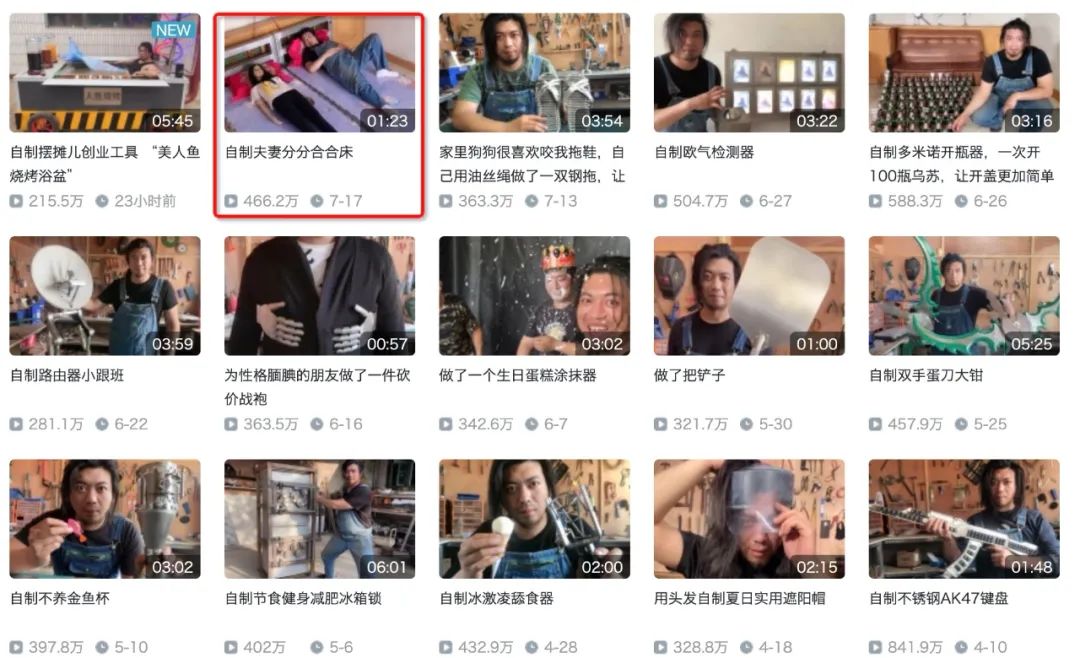
自制夫妻分分合合床,一听就知道是废品了,该视频自7.17发布以来共获得460万+播放,1.3万+条实时弹幕,用Python爬取21000条弹幕并制作词云图(点击图片可以直达该视频播放)

除了满屏的哈哈哈,手工耿也有属于自己的弹幕热词,比如刑部尚书、害怕、申请专利、量产、有用,取关了、这个项目我王多鱼投了等,当然由于这期视频为夫妻分分合合床,所以类似老婆、嫂子等词语也被疯狂刷屏。
美食区-我是郭杰瑞
现在我们来到b站美食区-郭杰瑞的弹幕区,虽然现在更像是战地记者的郭锥近期也回归了老本行,7.21日更新了美食相关视频,并且也获得了七月视频的最高播放
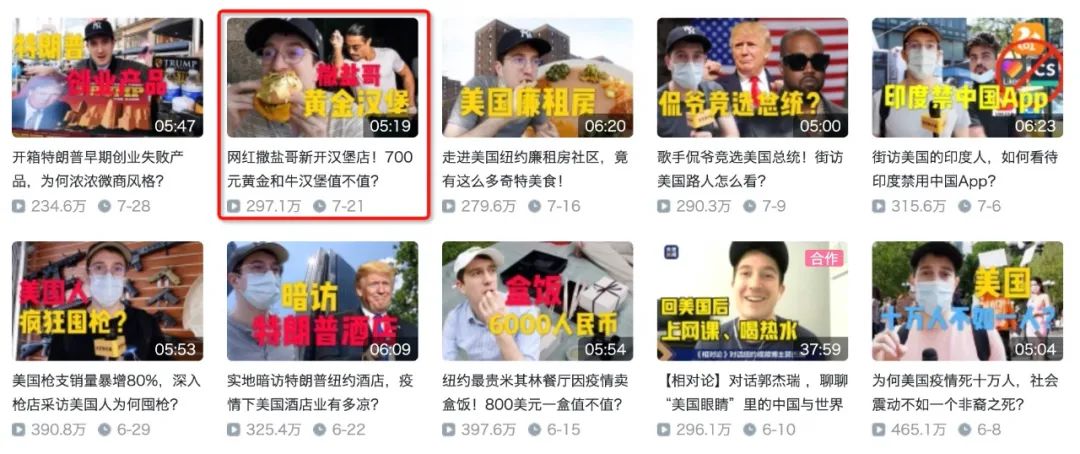
我们爬取该视频的15000条弹幕进行分析并制作词云图如下(点击图片可以直达该视频播放)

除了满屏的哈哈哈之外,这个不辣 是刷的最多的弹幕,你也可以在郭杰瑞的任何视频中看到刷这个梗的弹幕。当然类似于血亏、汉堡、黄金等就是和该视频相关的热词了其次由于该视频是在纽约录制,所以美丽的风景线、no justice no peace也是弹幕一直在刷的
鬼畜区
最后,我们来到B站的鬼畜区,看看最火的鬼畜区弹幕都爱刷什么,我们打开b站鬼畜区的7月排行榜
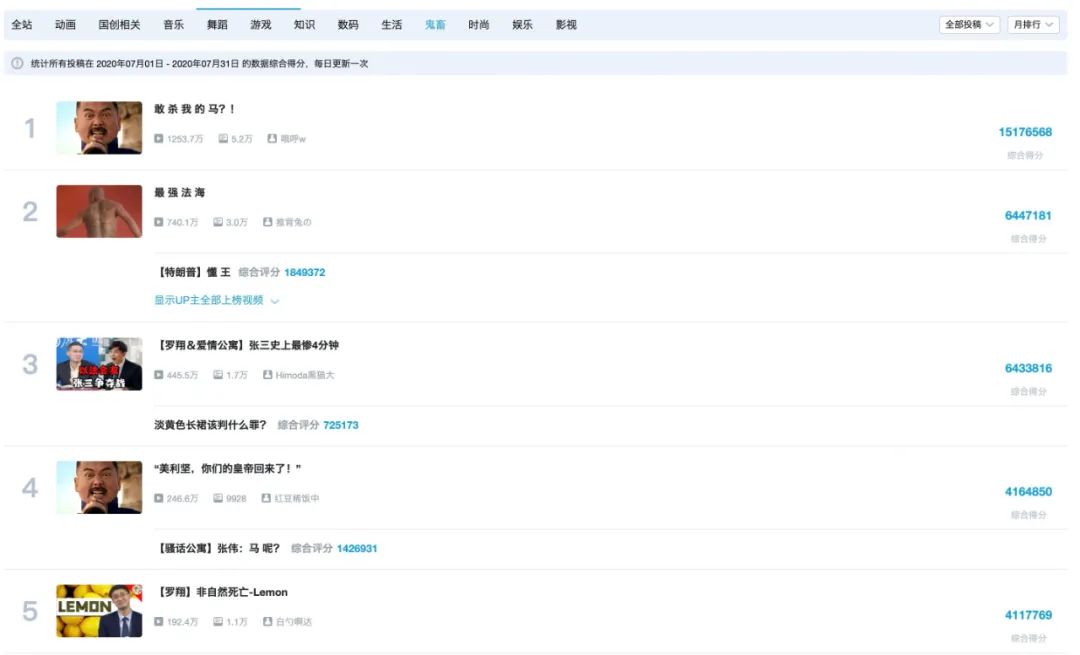
可以看到,7月最热的5个鬼畜视频中,两个是基于让子弹飞制作,两个是基于罗翔制作,为了采集更多的弹幕数据,本文选择月初发布的基于罗翔x爱情公寓的鬼畜视频【张三史上最惨4分钟】,共爬取到近4万条弹幕数据并制作词云图如下(点击图片可以直达该视频播放)

来到鬼畜区肯定就少不了好活当赏和下次一定,当然有张三的地方就有法外狂徒,有爱情公寓的地方就有肾宝。其次一个优秀的鬼畜视频开头一定会有人刷欢迎回来和每日亿遍,持续的押韵、skr、上头也是少不了~
技术解析
本节介绍如何使用Python爬取B站指定视频的全部弹幕,如果你尝试去搜索Python爬取B站弹幕等关键词,会发现大多数教程是通过请求存储弹幕的xml文件来获取数据,但是目前已经失效,除此之外GitHub上还有一些b站的API,不过为了更好的采集自己想要的数据,本文选择自行爬取,思路依旧是抓包—>requests请求数据,我们已华农兄弟的视频为例,首先打开需要采集弹幕的视频,然后F12—>Network,
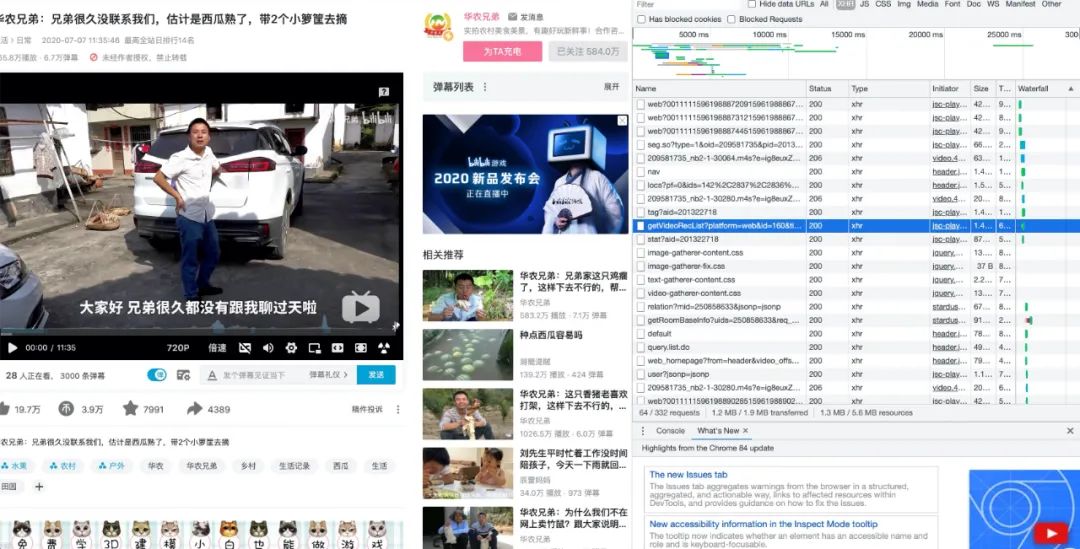
此时无论怎样查找,都找不到存储弹幕的数据包,即使你打开弹幕列表,依旧只能找到一个被类似弹幕但是被加密的数据包,因此需要按照下图指示点击弹幕列表—>查看历史弹幕,并选择任意一天的历史弹幕,此时就能找到存储该日期弹幕的ajax数据包,所有的弹幕都藏在一个i标签中
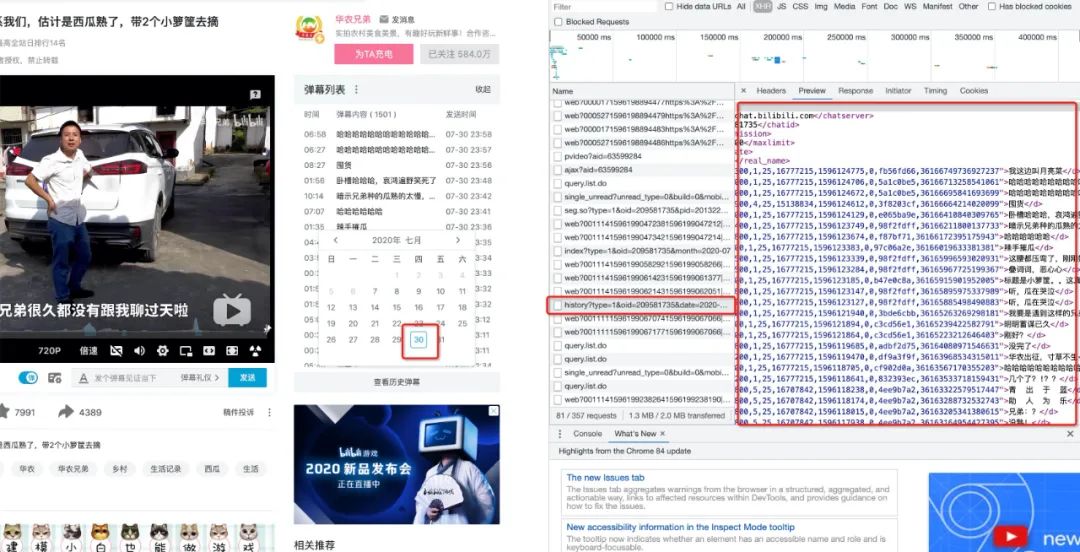
现在查看请求的相关信息
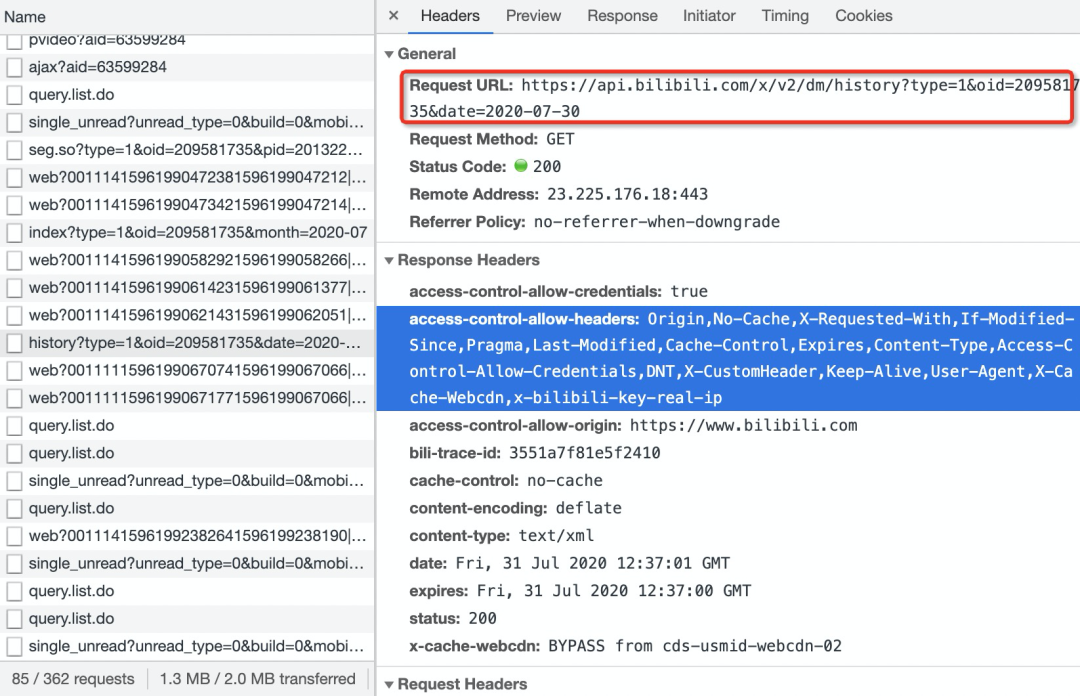
可以发现RequestURL关键就是oid和date两个参数,date是日期没什么好说的,oid虽然不知道是什么,但是一堆数据包中很多都是带有一个oid
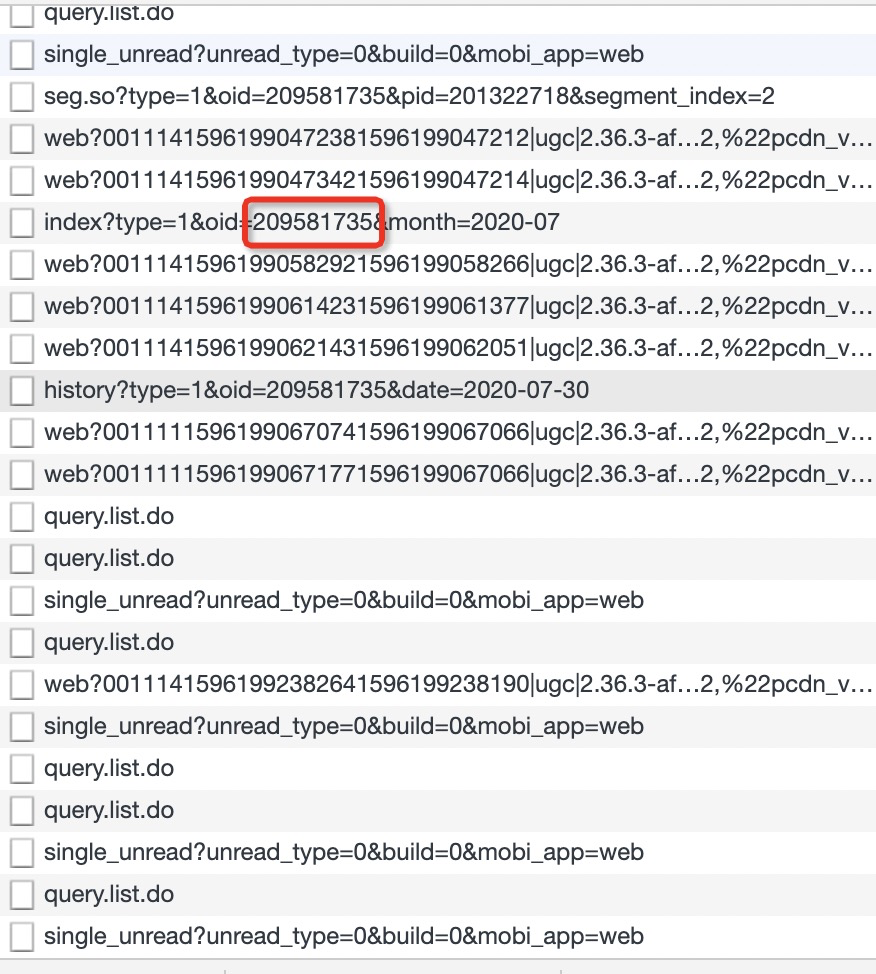
所以找到一个视频的oid并不困难,接下来要做的就是根据这两个参数构造不同日期的弹幕URL
def get_url(oid,start,end):
'''
获取指定日期的弹幕
oid:视频oid
start,end:起止日期
'''
url_list = []
date_list = [i for i in pd.date_range(start,end).strftime('%Y-%m-%d')]
for date in date_list:
url = f"https://api.bilibili.com/x/v2/dm/history?type=1&oid={oid}&date={date}"
url_list.append(url)
return url_list这里注意的是我们构造日期使用了pandas中的date_range函数,非常好用,感兴趣的读者可以自行搜索了解,现在我们获得了指定日期的弹幕数据URL,接下来要做的就是使用requests请求网站并使用bs4解析数据,最后将数据写入TXT即可
def get_danmu(url_list,name):
'''
下载弹幕存至本地txt
'''
headers = {"cookie": "修改为你的cookie",
"origin": "https://www.bilibili.com",
"referer": "https://www.bilibili.com/video/BV1gW411b735",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"}
file = open(f"{name}.txt",'w')
for i in trange(len(url_list)):
url = url_list[i]
res = requests.get(url,headers = headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text)
data = soup.find_all("d")
danmu = [data[i].text for i in range(len(data))]
for items in danmu:
file.write(items)
file.write("\n")
time.sleep(2)
file.close()上面的代码并不复杂,使用自己的cookie等参数构造请求头循环请求数据即可,唯一要注意的就是返回的结果编码为ISO-8859-1,需要先使用res.encoding = 'utf-8'修改编码,否则就会乱码,当然我这里还是用了tqdm来添加进度条
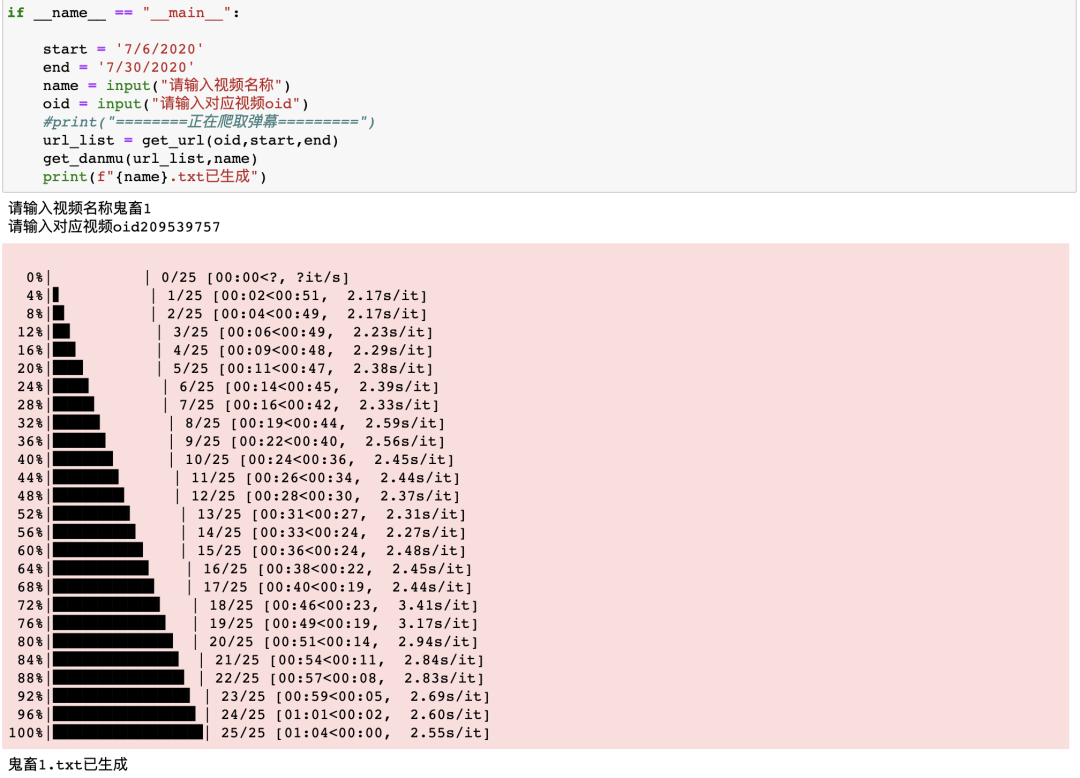
以上就是有关Python爬取弹幕的技术解析,而词云图的制作我们在之前的文章中有过详细的讲解,此处就不再赘述,如果你对代码感兴趣的话可以在后台回复0802获取。最后如果你喜欢本文的话,不要忘记点击文末三连,是这次而不是下次一定!
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~