
Kyuubi 实践 | Apache Kyuubi 在 T3 出行的深度实践
支撑了80%的离线作业,日作业量在1W+
大多数场景比 Hive 性能提升了3-6倍
多租户、并发的场景更加高效稳定
引入 Kyuubi 前的技术架构
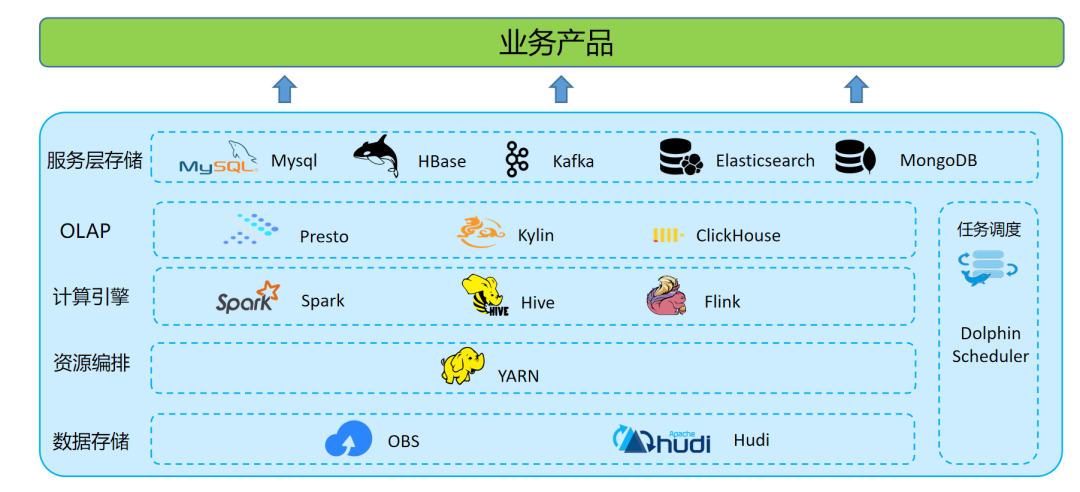
数据存储
OBS 对象存储,格式化数据存储格式以 Hudi 格式为主。
数据计算
离线数据处理:利用 Hive on Spark 批处理能力,在 Apache Dolphin Scheduler 上定时调度,承担所有的离线数仓的 ETL 和数据模型加工的工作。
实时数据处理:建设了以 Apache Flink 引擎为基础的开发平台,开发部署实时作业。
数据查询与分析
应用服务层
现有架构痛点
跨存储
SQL不统一
资源管控乏力
选型 Apache Kyuubi
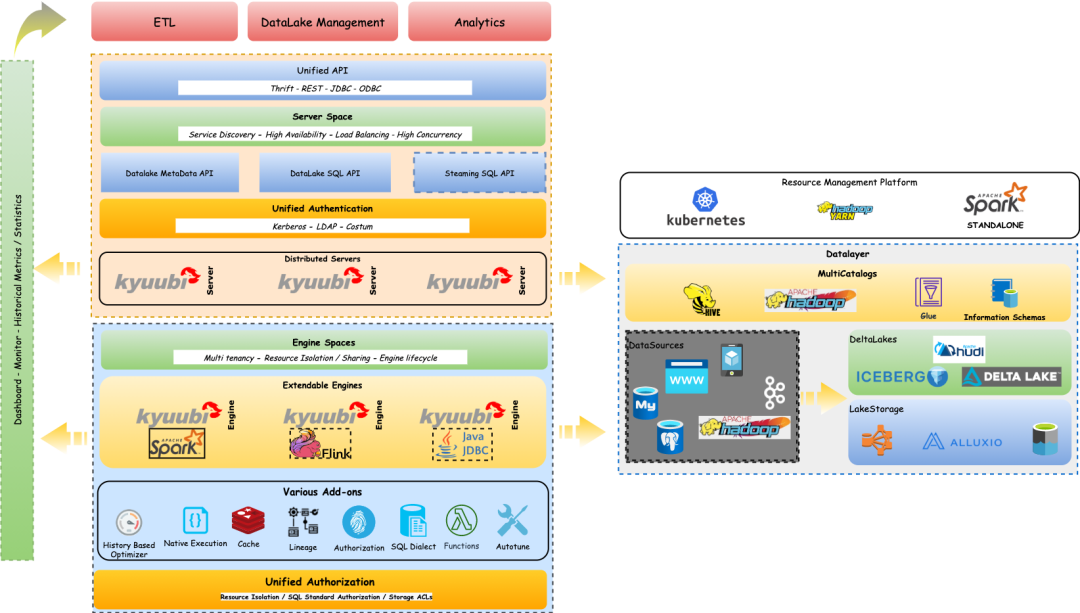
Apache Kyuubi 架构
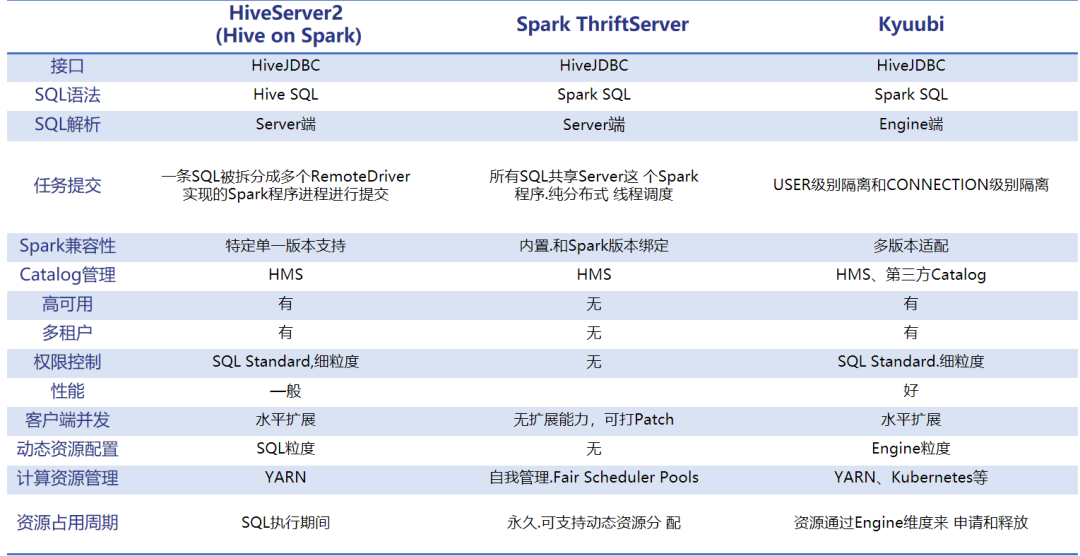
Apache Kyuubi 优势
Apache Kyuubi在T3出行场景
AD-HOC场景
[notebook][[interpreters]][[[cuntom]]]name=Kyuubiinterface=hiveserver2[spark]sql_server_host=Kyuubi Server IPsql_server_port=Kyuubi Port
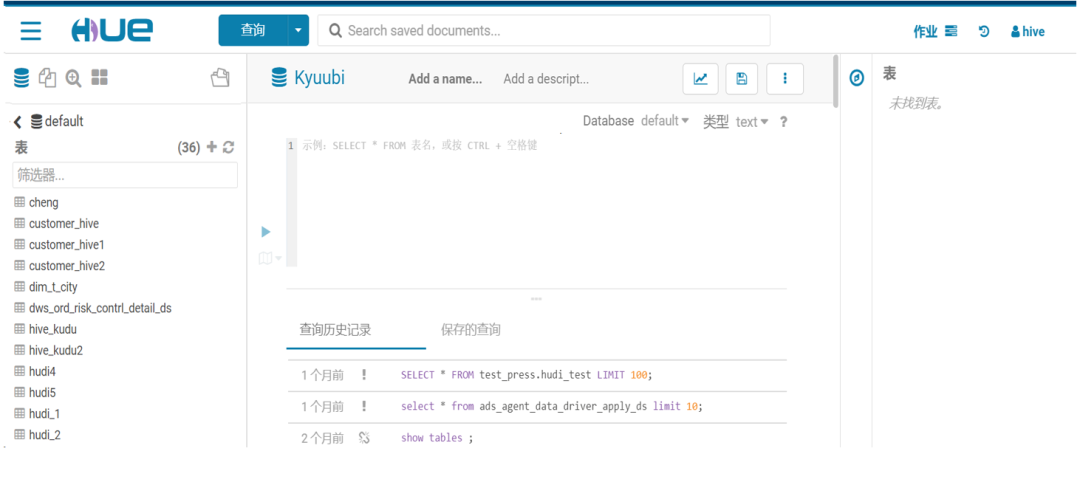
ETL场景
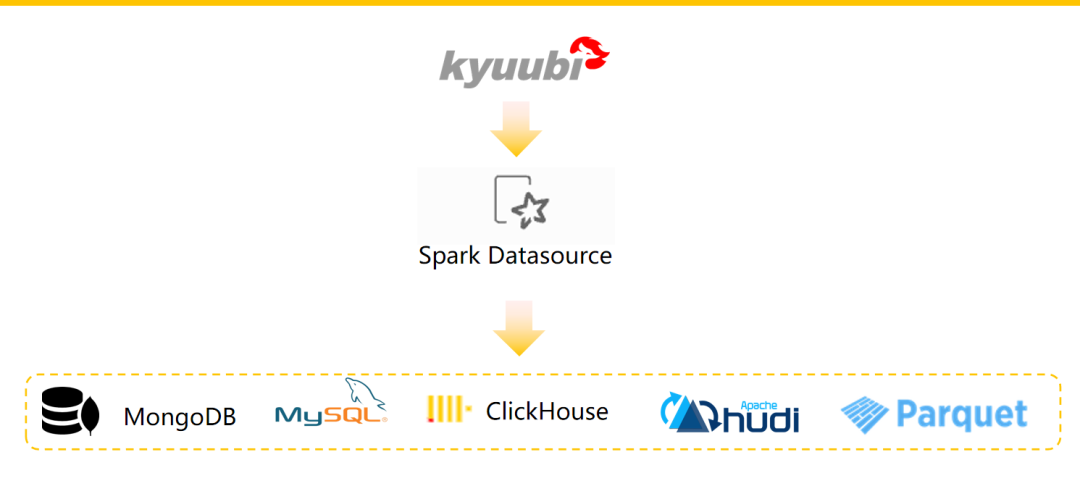
联邦查询场景
所以,我们利用 Spark DatasourceV2 实现了统一语法的跨存储联邦查询。其提供高效,统一的 SQL 访问。这样做的优势如下:
单个 SQL 方言和 API 统一安全控制和审计跟踪 统一控制 能够组合来自多个来源的数据 数据独立性
CREATE EXTERNALTABLE mongo_test
USING com.mongodb.spark.sql
OPTIONS (
spark.mongodb.input.uri "mongodb://用户名:密码@IP:PORT/库名?authSource=admin",
spark.mongodb.input.database "库名",
spark.mongodb.input.collection "表名",
spark.mongodb.input.readPreference.name "secondaryPreferred",
spark.mongodb.input.batchSize "20000"
);
Kyuubi 性能测试
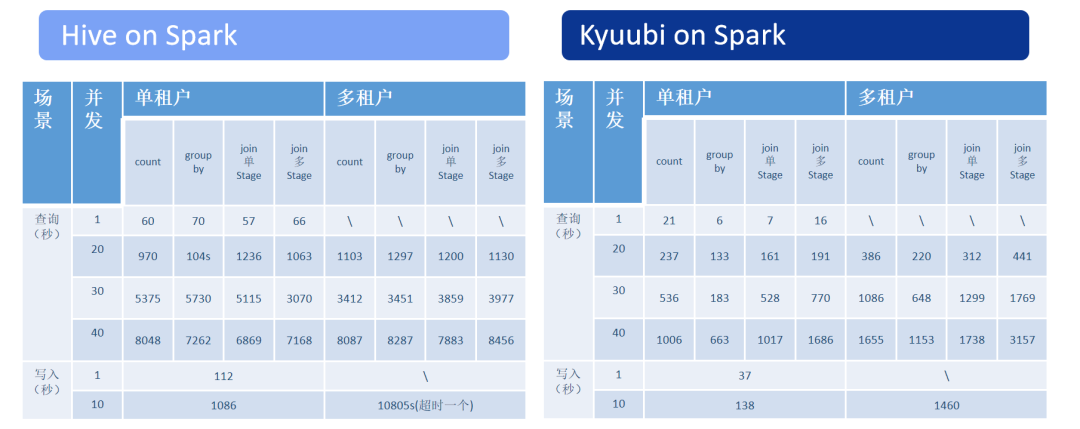
单用户和多用户场景
聚合函数性能对比
Join 性能对比
单 stage 和多 stage 性能对比
T3出行对 Kyuubi 的改进与优化
Kyuubi Web:启动一个独立多 web 服务,监控管理 Kyuubi Server。
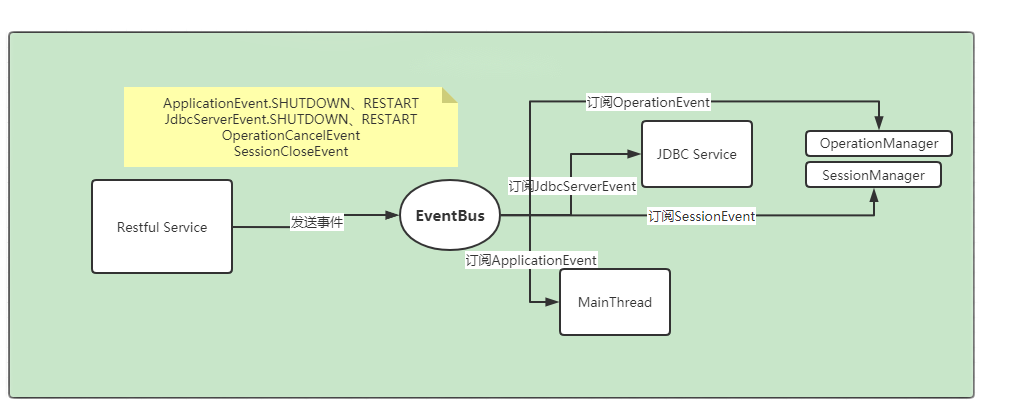
Kyuubi EventBus:定义了一个全局的事件总线。
Kyuubi Router:路由模块,可以将专有语法的 SQL 请求转发到不同的原生 JDBC 服务上。
Kyuubi Spark Engine:修改原生 Spark Engine。
Kyuubi Lineage:数据血缘解析服务,将执行成功多 SQL 解析存入图数据库,提供 API 调用。
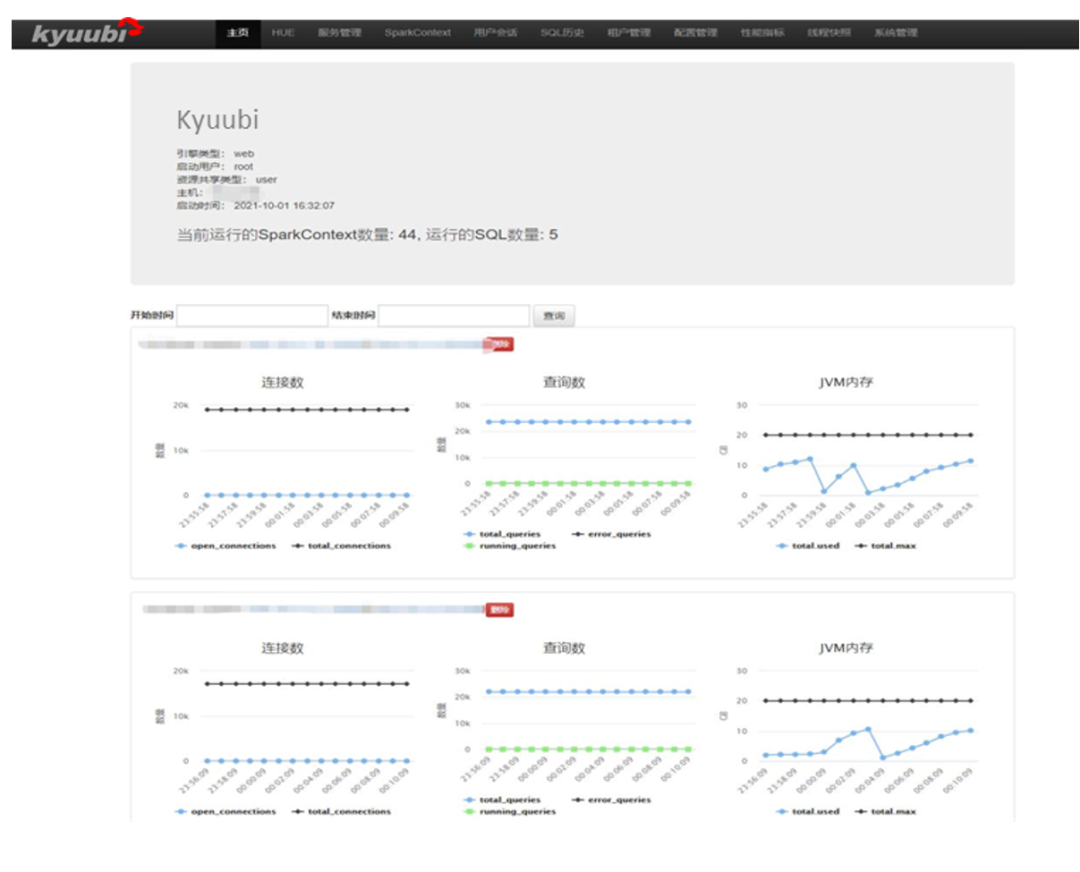
Kyuubi Web 服务功能
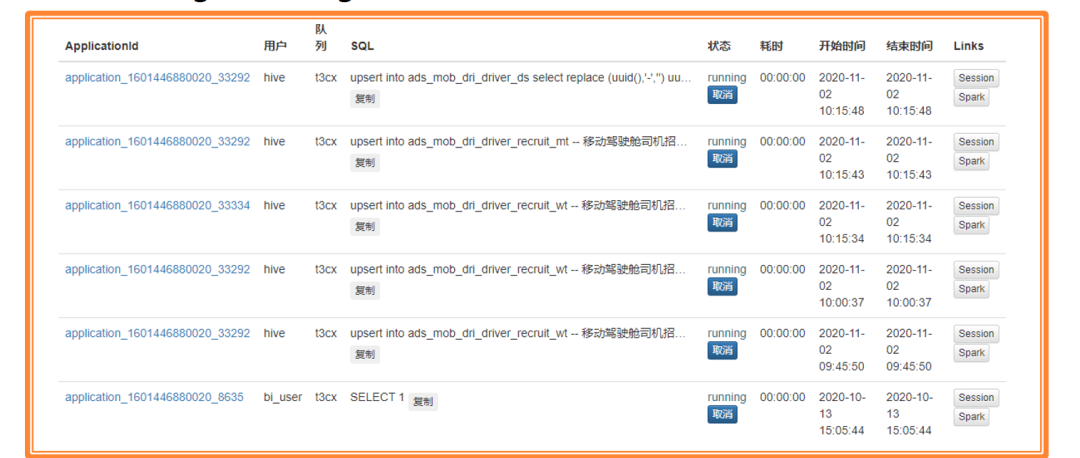
当前运行的 SparkContext 和 SQL 数量
各个 Kyuubi Server 实例状态
Top 20: 1天内最耗时的 SQL
用户提交 SQL 排名(1天内)
展示各用户 SQL 运行的情况和具体语句
SQL 状态分为:closed,cancelled,waiting和running。其中waiting和running 的 SQL 可取消
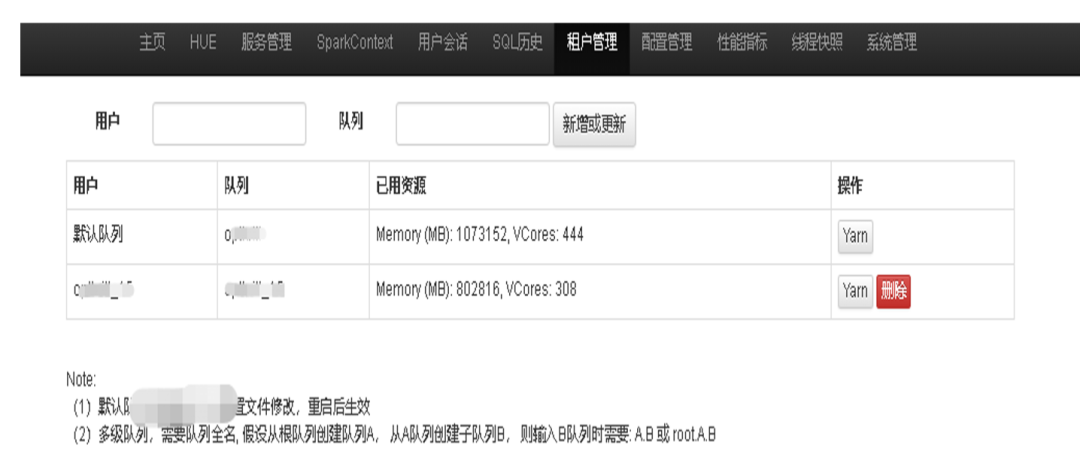
根据管理租户引擎对应队列和资源配置、并发量
可以在线查看、修改 Kyuubi Server、Engine 相关配置
Kyuubi EventBus
Kyuubi Router

Kyuubi Spark Engine
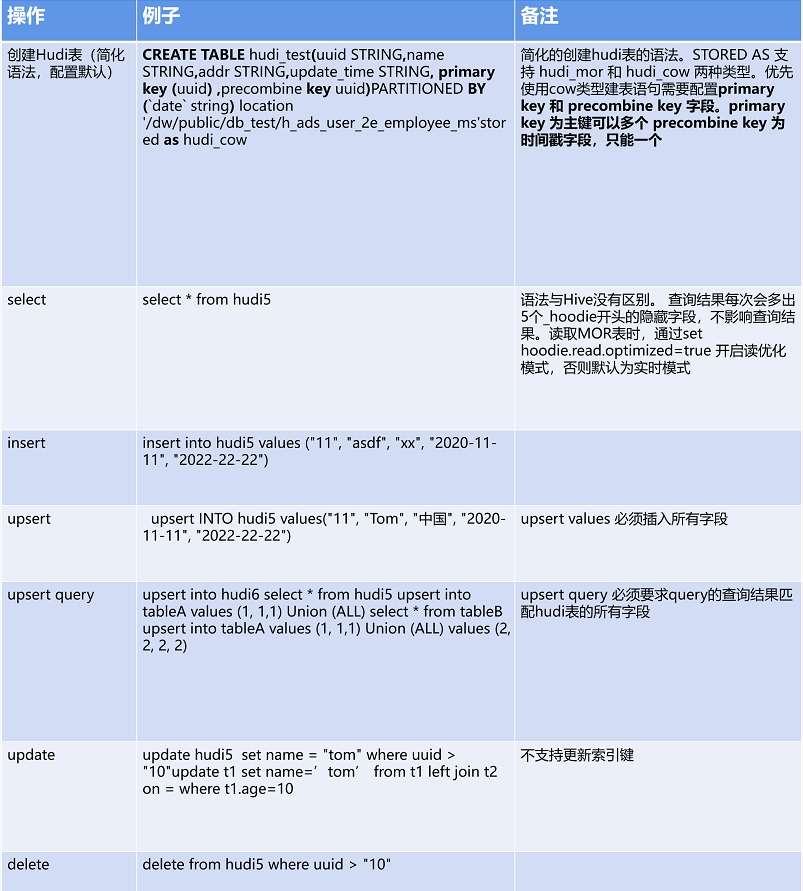
将 Kyuubi-Spark-Sql-Engine 的 Spark 3.X 版本改成了 Spark 2.4.5,适配集群版本,后续集群升级会跟上社区版本融合
增加了Hudi datasource 模块,使用 Spark datasource 计划查询 Hudi,提高对 Hudi 的查询效率
集成 Hudi 社区的 update、delete 语法,新增了 upsert 语法和 Hudi 建表语句
Kyuubi Lineage
基于 Kyuubi 的解决方案
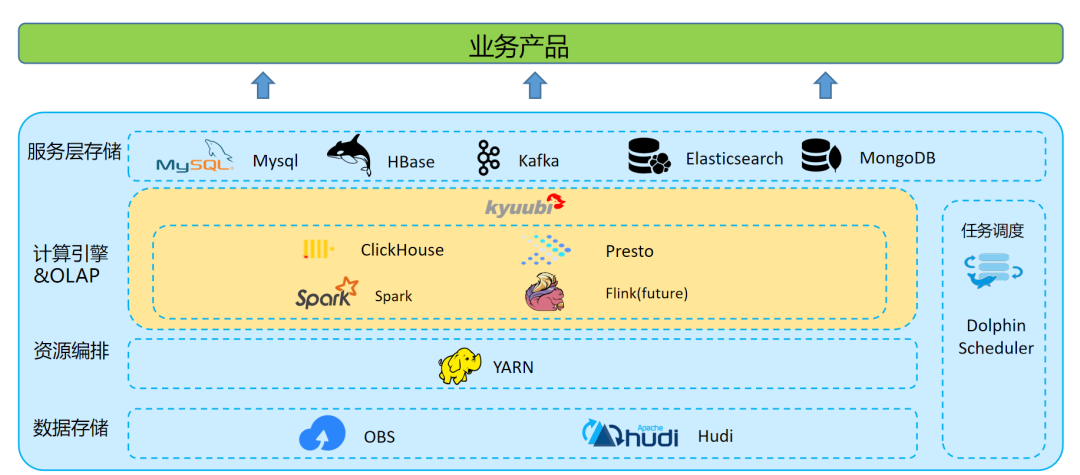
总结