
【PPT 下载】Apache Kylin 在中通快递的实践
摘要 ·
Apache Kylin 在中通是如何落地的,又是怎样赋能中通快递实现 OLAP 分析能力起飞的?本文从多方面对比了 Presto 和 Kylin 的优缺点,并从业务场景、调度整合、监控系统、运维调优、源码和二次开发等多个角度进行了阐述。
1
OLAP 在中通的演进
1.1 平台架构
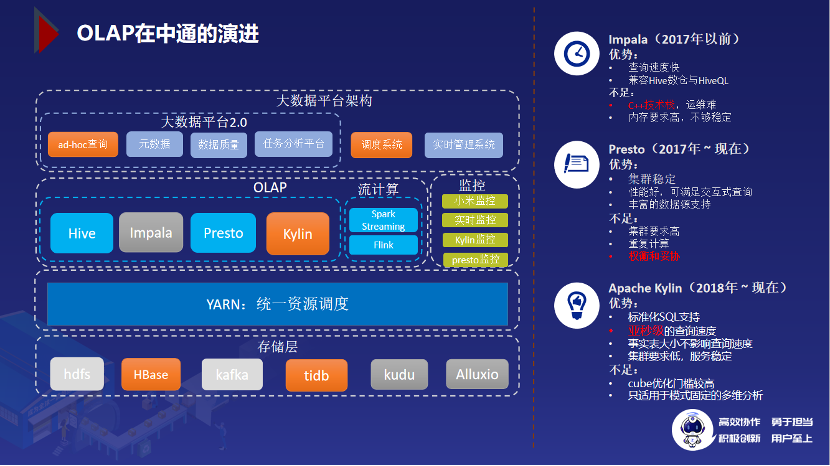
1.2 OLAP 在中通的发展历程
查询速度快:对比Hive有着显著的性能提升。
兼容Hive数仓:可以分析Hive中的数据。
内存要求高且不够稳定:偶尔会出现进程挂掉的情况。
C++技术栈:带来了额外的运维成本,难以进行二次开发。
服务很稳定:很少会出现 server 挂掉的情况。
性能非常好:可满足交互式查询甚至是跑一些 ETL 任务。
丰富的数据源支持:基于插件机制可以很方便的分析 Hive、Kudu、kafka 和 Tidb 等其他组件中的数据,甚至可以进行不同数据源的关联分析,例如在一个 SQL 中关联 Hive 与 Kafka 中的数据。
Presto 虽然优点很多,却也存在几点不足:
集群要求较高:想要更快的查询速度就需要更多的机器,更好的网络带宽,更大的内存以及更强的CPU去支撑。
重复计算:相同的查询也要重复的拉数据进行分布式计算。这个重复计算有时会给我们带来痛苦,比如说集群繁忙,有时namenode负载高、网络出现抖动等都会给查询速度带来影响。为此,我们引入了alluxio,对Presto常用的hive表进行加速,如此一来可以大幅提升scan hive table的速度。
需要权衡和妥协:你需要在查询速度和查询复杂度上面妥协。这一点先卖个关子,将在后面的“中通为什么选择Apache Kylin”中重点说明。
具有标准化的 SQL 支持:提供了 JDBC/ODBC/Rest API 接口,便于做系统集成。
亚秒级的查询速度:这一点是难能可贵的,在大数据领域,将查询速度提高到亚秒级,凤毛麟角。这不单单是查询速度的提升,更是用户体验的巨大提升。
事实表大小不影响查询速度:随着数据量的不断增长,其他的 OLAP 引擎都会有不同程度的查询速度下降。反观 Kylin,数据的增长只会影响 cube 的构建速度,对查询速度影响很小。
集群要求低且服务稳定,中小企业也养得起 Kylin。在过去2年多的时间里,Kylin 集群一直很稳定,没有出现过进程异常退出的情况。
cube 优化门槛较高:需要专门的学习与实践。
只适用于模式固定的多维分析:也就是说模型不能总变。
2
为什么选择 Apache Kylin
2.1 Apache Kylin 简介
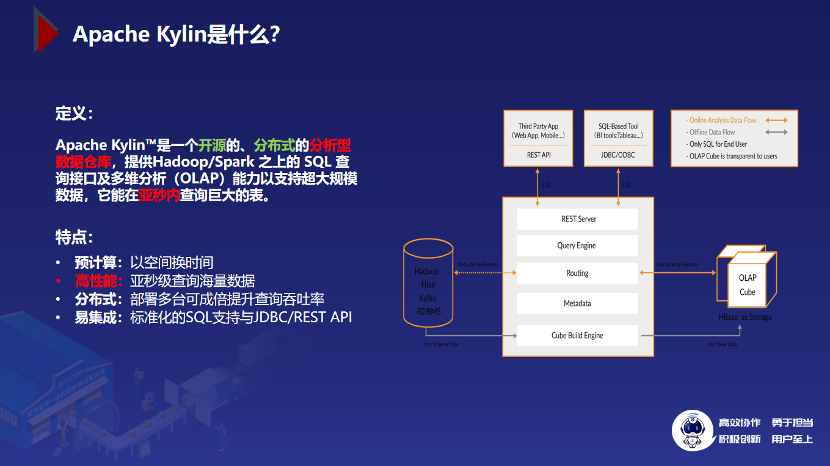
预计算:以空间换时间的方式事先根据模型计算出各种可能,让查询引擎做很更少的计算。
高性能:Kylin 在中通97%以上的查询都能在1s内返回结果。
分布式:部署多台可成倍提升查询吞吐率。
易集成:提供 JDBC/Rest API,易于做系统集成。
2.2 基于 Presto 的经典实现

开发周期长:首先需要ETL的同学先将数据预计算成大宽表,然后利用 alluxio 对这张宽表加速,最后应用组的同学写 sql 写代码,开发成本很高。
灵活性差:可能一个很小的改动都会导致重大的调整。
浪费集群资源:presto会不厌其烦的重复去拉数据,重复去计算,带来了集群压力和网络带宽压力。
2.3 Apache Kylin VS Presto

Kylin 对比 Presto 带来了上百倍的查询性能提升。
绝大多数的查询在亚秒内返回结果。
集群要求更低,更少的机器带来了更高的查询性能。
3
Apache Kylin 在中通的实践

3.1 业务描述
维度多:大概有 20 多个维度;
查询慢:现有的技术方案不能很好的满足查询需求
要求高:要求 5s 内出结果
数据量大,日新增 2 亿多条。
3.2 Kylin 如何赋能
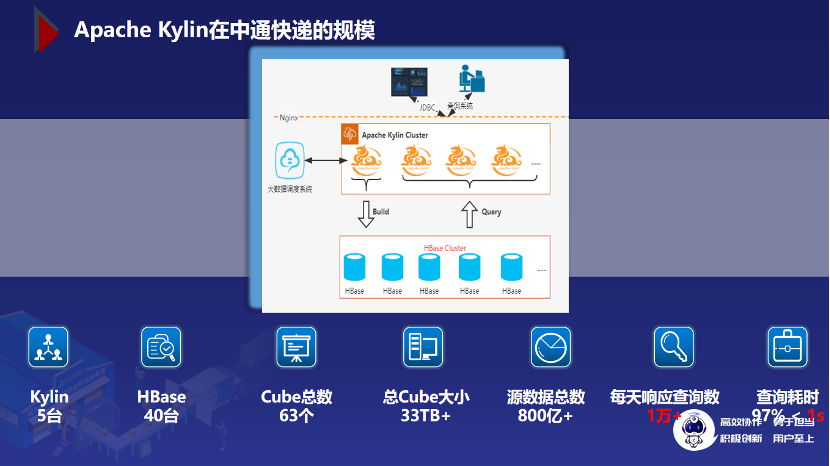
3.3 Apache Kylin 在中通的规模
3.4 Apache Kylin 与调度系统集成

3.5 Apache Kylin 监控系统--分钟级监控

每分钟的查询量统计:统计每分钟请求 Kylin 的查询数,可用于查看业务系统在不同时段的查询量,快速定位异常流量。
每分钟失败的查询:统计每分钟里失败的查询数,可用于判断 Kylin 是否存在问题或者是应用系统发出来的查询是否有异常。
第三个是异常 SQL 自动 kill:坏查询会给集群带来波动,异常 SQL 自动 kill 可降低这种影响,保障集群稳定。
3.6 Apache Kylin 监控系统--天级别监控
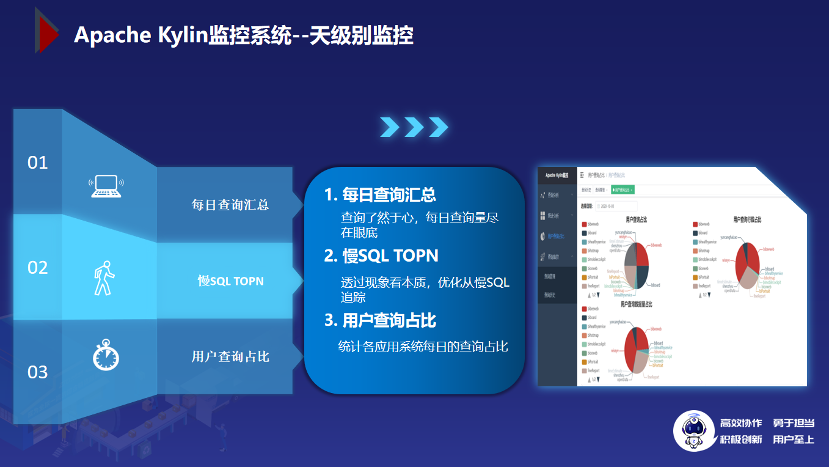
每日查询统计:通过这个功能可以清晰的看到每天Kylin 响应的查询总数,命中缓存的查询也能被统计到。
慢 SQL TOPN:很有用的一个功能,它可以对每天的查询按耗时降序排列,有哪些坏查询,对应的cube 是否具有优化的空间,一目了然。用户查询占比:这个功能可用来统计各应用系统每日的查询量占比,辅助分析各系统的使用情况。
3.7 Apache Kylin 监控系统--异常监控

cube 膨胀率监控:根据官方的建议,当扫描到某些cube 的膨胀率超过1000%时会发出钉钉告警。
Segment 异常监控:我们曾经有一个线上的 cube,跑着跑着发现数据对不上,经定位发现几天前的一个构建任务没跑成功,导致了 segment 存在空洞,有了这个监控可以很好的避免此类问题的发生。
job失败监控:当构建任务失败时,会主动推送告警信息。
TTL 未设置监控:这个监控是为了防止有些 cube 在创建过程中忘记设置 TTL 时间,避免历史数据无法得到清理。
Kylin 进程监控:7*24小时监控 Kylin 进程,重中之重。
3.8 Apache Kylin 的优化实践

3.9 Apache Kylin 的源码与升级

4
未来规划

Kylin智能诊断:作为监控系统的补充,智能诊断同样具有重要的作用。它可以根据预设的规则给出初步的诊断结果,辅助用户排查问题。
查询下压Presto:Kylin已经支持查询下压的功能,未来将探索将Kylin作为统一的查询入口,对于未命中cube的查询下压到presto,形成优势互补。
自助分析系统:最后一个则是自助分析系统,相信Kylin在这个系统中会发挥更大的作用。