
Kyuubi 实践 | 有了它!爱奇艺加速 Hive SQL 迁移 Spark

Hive 作为爱奇艺数仓的基础,Hive SQL 是爱奇艺大数据平台目前主要的数据处理工具,各个业务积累大量的 Hive ETL 任务。Spark 相对于 MapReduce 有着更为灵活的的计算模型,这使得 Spark 相对于
Hive (on MapReduce) 有更好的性能。
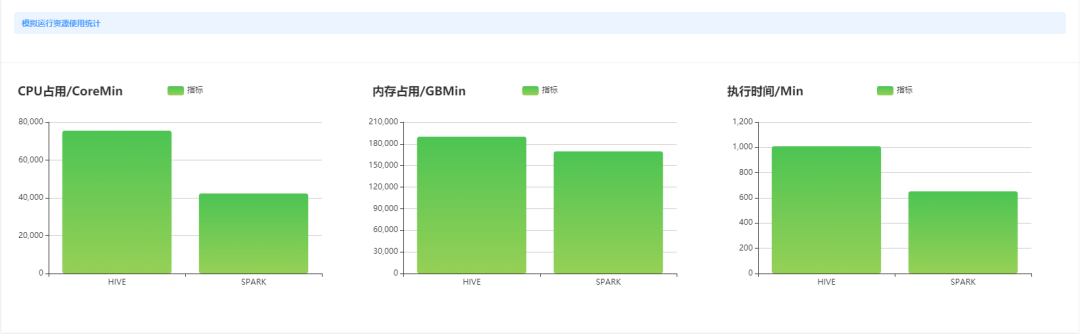
经过测试对比,我们发现迁移 Hive SQL 到 Spark 将会带来很大的性能提升和资源节省。
Apache Kyuubi (Incubating) 项目提供一个分布式多租户的 Spark Thrift Server,相对于 Spark 原生的
Spark Thrift Server 有更好的架构优势和更多优秀的特性,具体对比可参考:Kyuubi v.s. Spark Thrift
JDBC/ODBC Server (STS)。
![]() 1.1 双跑对比
1.1 双跑对比
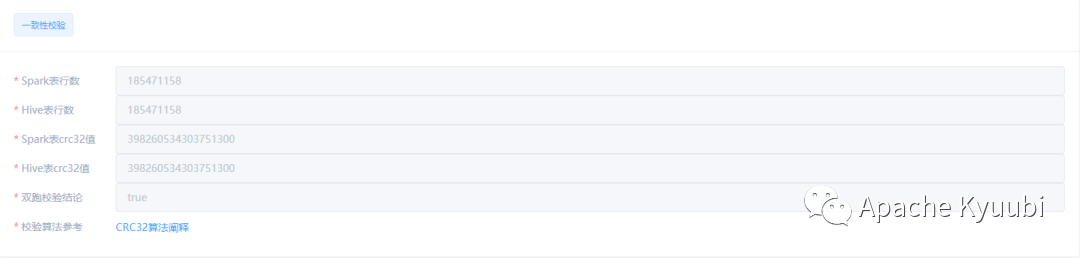
select sum(cast(CRC32(concat(*)) as decimal(19,0))) as checksum, count(*) as count from mock_db.mock_table
Spark 删除不存在分区报错,而 Hive 中允许删除不存在分区
Spark 执行 set mapreduce.job.reduces=-1 报错
数字类型与字符串比较,结果与 Hive 不一致
.....
为了加快迁移的进度,减少用户参与,我们需要兼容部分 Hive 语法。
在 Kyuubi 中提供 kyuubi-extension-spark 模块,维护Spark SQL的 Extensions,用于优化Spark SQL的执行计划,社区已经提供了很多优化,详细文档:Auxiliary
SQL extension for Spark SQL。我们基于此模块,为不兼容的语法修改其执行计划,使得与 Hive 保持一致的语义。


Adhoc:用于即席查询平台任务,数据量小,要求快速响应。配置 USER 共享级别的引擎,较大 Driver 内存,以及 Spark 任务抢占策略等。 Batch:用于数据开发平台任务,定时调度运行,稳定要求较高。配置 CONNECTION 级别独立引 擎,使得任务完全资源隔离,并添加小文件、AQE 等优化配置。 User/Business/Custom:允许定义用户、业务或其他自定义标签,绑定特有的一些配置,如:队列、资源、兼容性适配相关配置等,降低用户使用门槛。
KyuubiServerInfoEvent:Kyuubi Server 启动、停止事件信息 KyuubiSessionEvent:Session 开启、关闭事件,以及连接相关信息 KyuubiOperationEvent:Kyuubi Operation 执行事件,包括了 SQL 执行相关信息

文中文档可参考:
Kyuubi
v.s. Spark Thrift JDBC/ODBC Server (STS) ——https://kyuubi.apache.org/docs/latest/overview/kyuubi_vs_thriftserver.htmlAuxiliary
SQL extension for Spark SQL—— https://kyuubi.apache.org/docs/latest/sql/rules.html#DropIgnoreNonexistent——https://github.com/apache/incubator-kyuubi/blob/master/extensions/spark/kyuubi-extension-spark-3-1/src/main/scala/org/apache/kyuubi/sql/DropIgnoreNonexistent.scala
User
Defaults—— https://kyuubi.apache.org/docs/latest/deployment/settings.html#user-defaults
![]() END
END

Apache Kyuubi 推特账号 现已开通
推特搜索 Apache Kyuubi 或 浏览器 打开下方链接
即可关注~
https://twitter.com/KyuubiApache
还可以加入 Apache Kyuubi Slack
https://join.slack.com/t/apachekyuubi/shared_invite/zt-1bhswm1n6-n~0wMbkvhsp0WZX0FZXvPA
和海外开发者交流互动哦~
最后
Kyuubi 在这里提醒大家
文明上网 科学上网
往期精彩
丨记得点关注

