
Spark SQL快速入门系列之Hive
点击上方蓝色字体,选择“设为星标”




目录
一.hive和spark sql的集成方式(面试可能会问到)
二.spark_shell和spark_sql操作
spark_shell
spark_sql
使用hiveserver2 + beeline
三.脚本使用spark-sql
四.idea中读写Hive数据
1.从hive中读数据
2.从hive中写数据
使用hive的insert语句去写
使用df.write.saveAsTable("表名")(常用)
使用df.write.insertInto("表名")
3.saveAsTable和insertInto的原理
五.聚合后的分区数
一.hive和spark sql的集成方式(面试可能会问到)
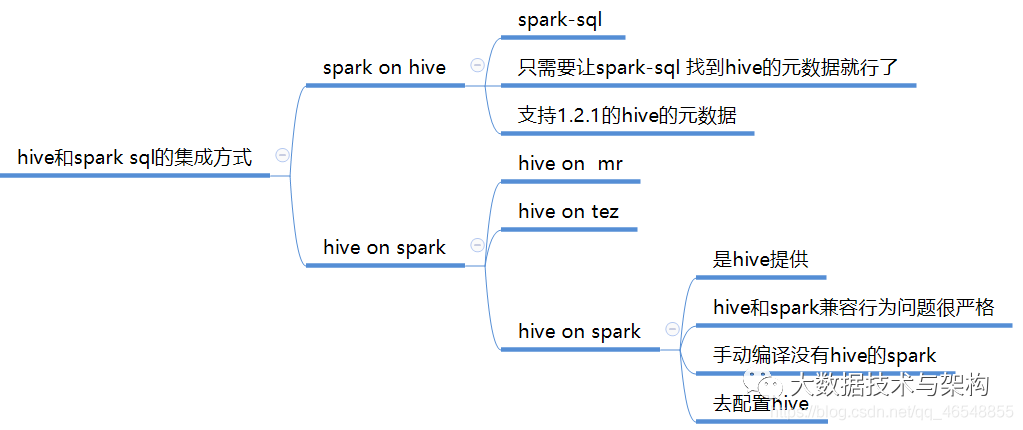
hive on spark(版本兼容)
官网https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started
spark on hive(版本兼容)
官网
http://spark.apache.org/docs/2.1.1/sql-programming-guide.html#hive-tables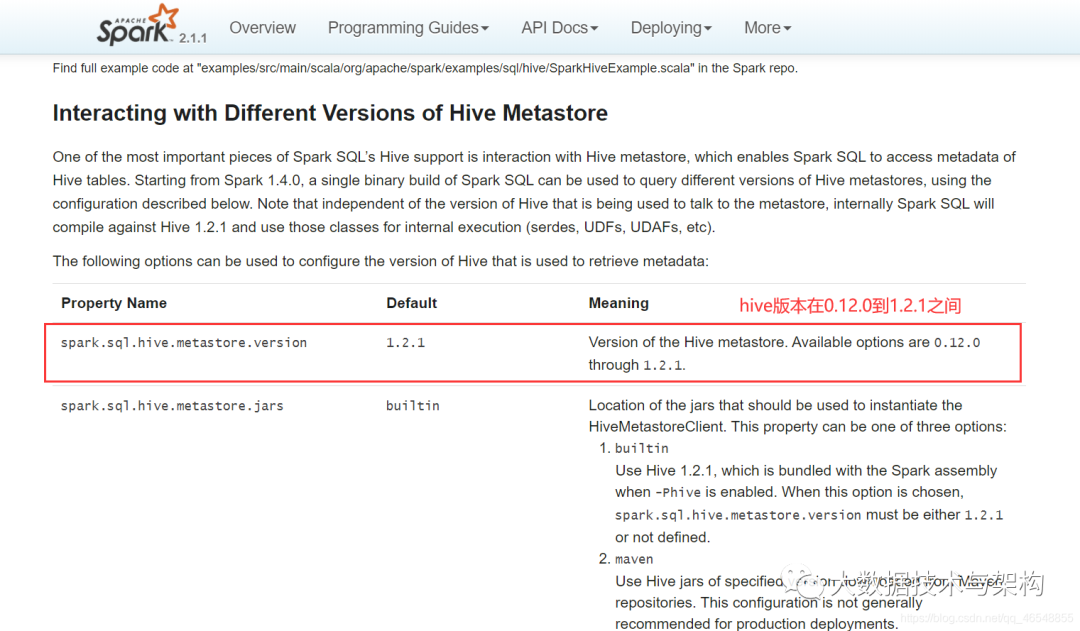
二.spark_shell和spark_sql操作
spark_shell

如果你在集群上使用了tez,你需要在spark/conf下spark-defaults.conf添加lzo的路径
spark.jars=/export/servers/hadoop-2.7.7/share/hadoop/common/hadoop-lzo-0.4.20.jarbin/spark-shell --master yarnspark_sql
完全跟sql一样

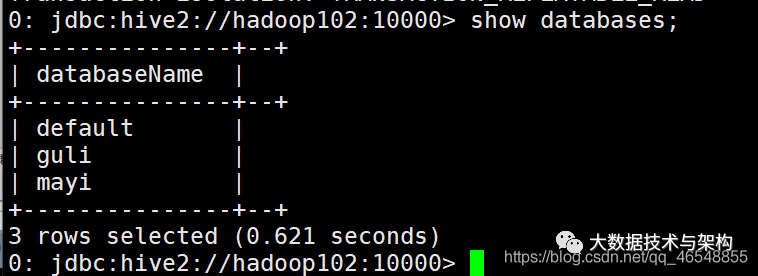
使用hiveserver2 + beeline
spark-sql 得到的结果不够友好, 所以可以使用hiveserver2 + beeline
1.启动thriftserver(后台)
sbin/start-thriftserver.shbin/beeline# 然后输入!connect jdbc:hive2://hadoop102:10000# 然后按照提示输入用户名和密码
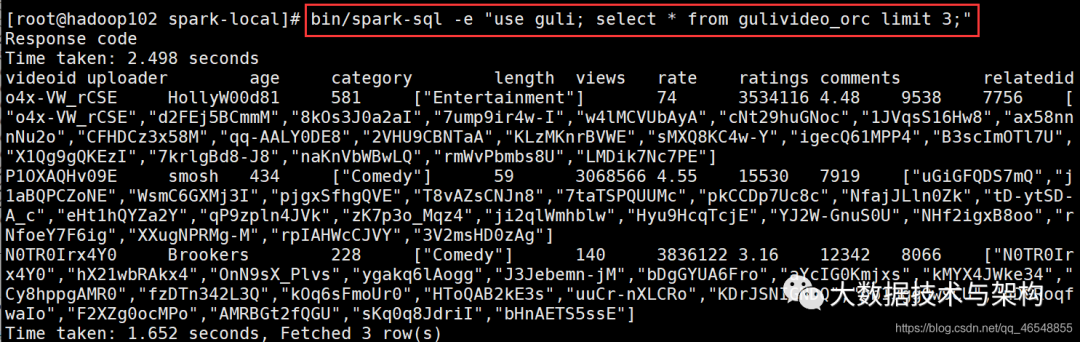
三.脚本使用spark-sql
四.idea中读写Hive数据
1.从hive中读数据

添加依赖
org.apache.spark spark-hive_2.11 2.1.1
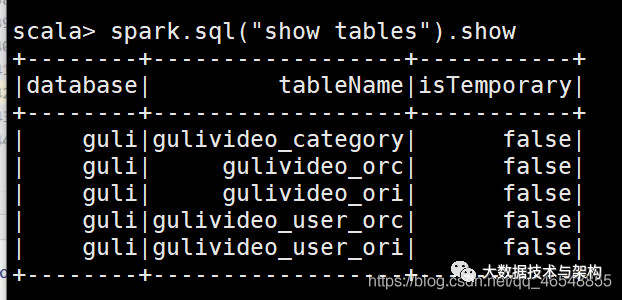
import org.apache.spark.sql.SparkSessionobject HiveRead {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("HiveRead")//添加支持外置hive.enableHiveSupport().getOrCreate()spark.sql("show databases")spark.sql("use guli")spark.sql("select count(*) from gulivideo_orc").show()spark.close()}}
结果
2.从hive中写数据
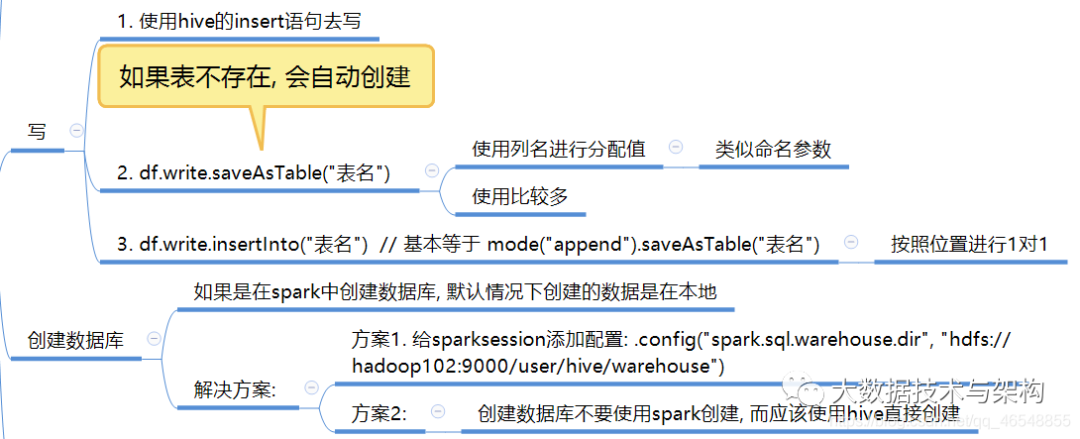
使用hive的insert语句去写
import org.apache.spark.sql.SparkSessionobject HiveWrite {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root");val spark = SparkSession.builder().master("local[*]").appName("HiveRead")//添加支持外置hive.enableHiveSupport().config("spark.sql.warehouse.dir","hdfs://hadoop102:9000/user/hive/warehouse").getOrCreate()//先创建一个数据库spark.sql("create database spark1602")spark.sql("use spark1602")spark.sql("create table user1(id int,name string)")spark.sql("insert into user1 values(10,'lisi')").show()spark.close()}}
使用df.write.saveAsTable(“表名”)(常用)
import org.apache.spark.sql.SparkSessionobject HiveWrite {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root");val spark = SparkSession.builder().master("local[*]").appName("HiveRead")//添加支持外置hive.enableHiveSupport().config("spark.sql.warehouse.dir","hdfs://hadoop102:9000/user/hive/warehouse").getOrCreate()val df = spark.read.json("D:\\idea\\spark-sql\\input\\user.json")spark.sql("use spark1602")//直接把数据写入到hive中,表可以存在也可以不存在df.write.saveAsTable("user2")//也可以进行追加//df.write.mode("append").saveAsTable("user2")spark.close()}}
使用df.write.insertInto(“表名”)
import org.apache.spark.sql.SparkSessionobject HiveWrite {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root");val spark = SparkSession.builder().master("local[*]").appName("HiveRead")//添加支持外置hive.enableHiveSupport().config("spark.sql.warehouse.dir","hdfs://hadoop102:9000/user/hive/warehouse").getOrCreate()val df = spark.read.json("D:\\idea\\spark-sql\\input\\user.json")spark.sql("use spark1602")df.write.insertInto("user2")spark.close()}}
3.saveAsTable和insertInto的原理
saveAsTable
使用列名进行分配值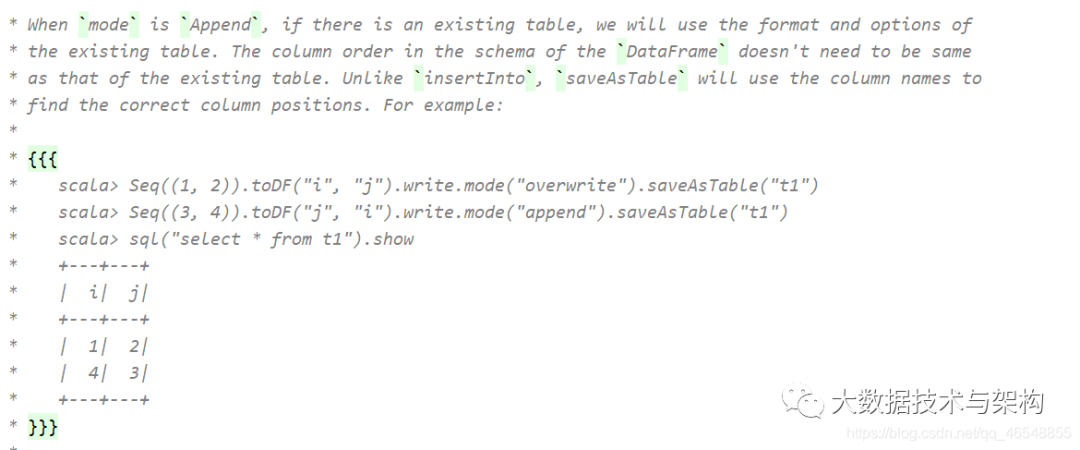
insertInto
按照位置进行1对1
五.聚合后的分区数
import org.apache.spark.sql.SparkSessionobject HiveWrite {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root");val spark = SparkSession.builder().master("local[*]").appName("HiveRead")//添加支持外置hive.enableHiveSupport().config("spark.sql.warehouse.dir","hdfs://hadoop102:9000/user/hive/warehouse").getOrCreate()val df = spark.read.json("D:\\idea\\spark-sql\\input\\user.json")df.createOrReplaceTempView("a")spark.sql("use spark1602")val df1 = spark.sql("select * from a ")val df2 = spark.sql("select sum(age) sum_age from a group by name")println(df1.rdd.getNumPartitions)println(df2.rdd.getNumPartitions)df1.write.saveAsTable("a3")df2.write.saveAsTable("a4")spark.close()}}
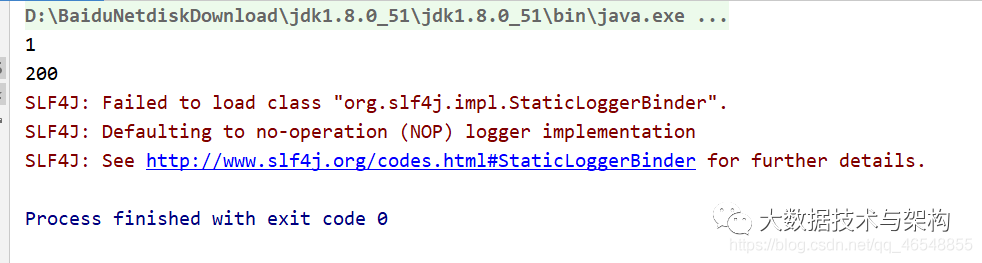
如果数据量小,没必要200两个分区,简直浪费。
df2.write.saveAsTable("a4")
df2.coalesce(1).write.saveAsTable("a4")


版权声明:
文章不错?点个【在看】吧! ?