
深克隆和浅克隆有什么区别?它的实现方式有哪些?
什么是浅克隆和深克隆
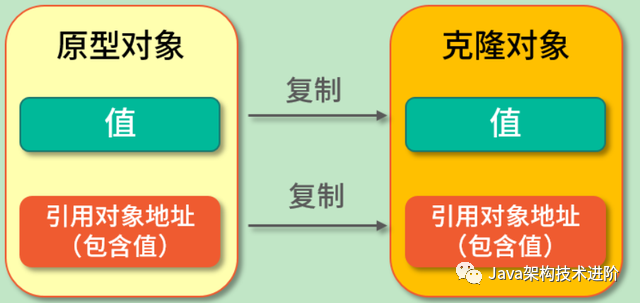
浅克隆(Shadow Clone)是把原型对象中成员变量为值类型的属性都复制给克隆对象,把原型对象中成员变量为引用类型的引用地址也复制给克隆对象,也就是原型对象中如果有成员变量为引用对象,则此引用对象的地址是共享给原型对象和克隆对象的。
简单来说就是浅克隆只会复制原型对象,但不会复制它所引用的对象
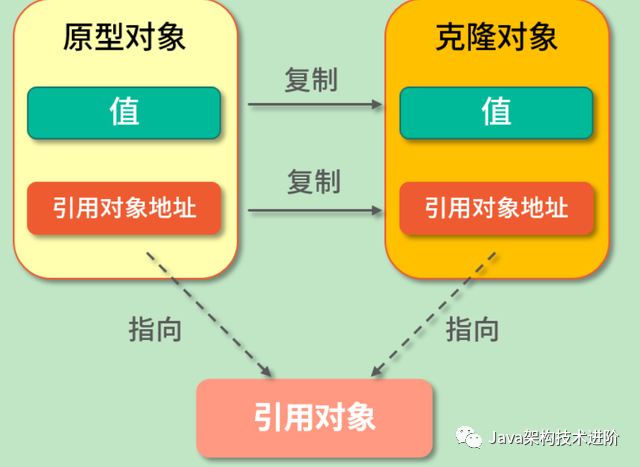
深克隆(Deep Clone)是将原型对象中的所有类型,无论是值类型还是引用类型,都复制一份给克隆对象,也就是说深克隆会把原型对象和原型对象所引用的对象,都复制一份给克隆对象,如下图所示:
如何实现克隆
在 Java 语言中要实现克隆则需要实现 Cloneable 接口,并重写 Object 类中的 clone() 方法,实现代码如下:
public class CloneExample {
public static void main(String[] args) throws CloneNotSupportedException {
// 创建被赋值对象
People p1 = new People();
p1.setId(1);
p1.setName("Java");
// 克隆 p1 对象
People p2 = (People) p1.clone();
// 打印名称
System.out.println("p2:" + p2.getName());
}
static class People implements Cloneable {
// 属性
private Integer id;
private String name;
/**
* 重写 clone 方法
* @throws CloneNotSupportedException
*/
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
}
执行结果为:
p2:Java在 java.lang.Object 中对 clone() 方法的约定有哪些?
对于所有对象来说,x.clone() !=x 应当返回 true,因为克隆对象与原对象不是同一个对象;
对于所有对象来说,x.clone().getClass() == x.getClass() 应当返回 true,因为克隆对象与原对象的类型是一样的;
对于所有对象来说,x.clone().equals(x) 应当返回 true,因为使用 equals 比较时,它们的值都是相同的。
Arrays.copyOf() 是深克隆还是浅克隆?
如果是数组类型,我们可以直接使用 Arrays.copyOf() 来实现克隆,实现代码如下:
People[] o1 = {new People(1, "Java")};
People[] o2 = Arrays.copyOf(o1, o1.length);
// 修改原型对象的第一个元素的值
o1[0].setName("Jdk");
System.out.println("o1:" + o1[0].getName());
System.out.println("o2:" + o2[0].getName());执行结果:
o1:Jdk
o2:Jdk从结果可以看出,我们在修改克隆对象的第一个元素之后,原型对象的第一个元素也跟着被修改了,这说明 Arrays.copyOf() 其实是一个浅克隆。
因为数组比较特殊数组本身就是引用类型,因此在使用 Arrays.copyOf() 其实只是把引用地址复制了一份给克隆对象,如果修改了它的引用对象,那么指向它的(引用地址)所有对象都会发生改变,因此看到的结果是,修改了克隆对象的第一个元素,原型对象也跟着被修改了。
深克隆的实现方式有几种?
所有对象都实现克隆方法;
通过构造方法实现深克隆;
使用 JDK 自带的字节流实现深克隆;
使用第三方工具实现深克隆,比如 Apache Commons Lang;
使用 JSON 工具类实现深克隆,比如 Gson、FastJSON 等。
具体代码实现方式可以查看:
https://shimo.im/docs/L9kBMnZ56GTnDRqK/ 《深克隆和浅克隆有什么区别?它的实现方式有哪些?》,可复制链接后用石墨文档 App 或小程序打开
Java 中的克隆为什么要设计成,既要实现空接口 Cloneable,还要重写 Object 的 clone() 方法?
Java 中实现克隆需要两个主要的步骤,一是 实现 Cloneable 空接口,二是重写 Object 的 clone() 方法再调用父类的克隆方法 (super.clone())
从源码中可以看出 Cloneable 接口诞生的比较早,JDK 1.0 就已经存在了,因此从那个时候就已经有克隆方法了,那我们怎么来标识一个类级别对象拥有克隆方法呢?克隆虽然重要,但我们不能给每个类都默认加上克隆,这显然是不合适的,那我们能使用的手段就只有这几个了:
在类上新增标识,此标识用于声明某个类拥有克隆的功能,像 final 关键字一样;
使用 Java 中的注解;
实现某个接口;
继承某个类。
第一个,为了一个重要但不常用的克隆功能, 单独新增一个类标识,这显然不合适;第二个,因为克隆功能出现的比较早,那时候还没有注解功能,因此也不能使用;第三点基本满足我们的需求,第四点和第一点比较类似,为了一个克隆功能需要牺牲一个基类,并且 Java 只能单继承,因此这个方案也不合适。采用排除法,无疑使用实现接口的方式是那时最合理的方案了,而且在 Java 语言中一个类可以实现多个接口。
那为什么要在 Object 中添加一个 clone() 方法呢?
因为 clone() 方法语义的特殊性,因此最好能有 JVM 的直接支持,既然要 JVM 直接支持,就要找一个 API 来把这个方法暴露出来才行,最直接的做法就是把它放入到一个所有类的基类 Object 中,这样所有类就可以很方便地调用到了。