
程序员修神之路--它可能是分布式系统中最重要的枢纽
“灵魂拷问
分布式系统为什么需要注册中心呢? 分布式系统注册中心有哪些坑? 分布式系统注册中心怎么来实现呢? 注册中心利用现成的组件很好实现吗?
看到标题你可能会鄙视一下,注册中心有是什么讲的。注册中心作为现在架构中的一个组件来说,确实很常见。微服务作为分布式系统最典型的一种表现形式,是最近几年最流行的概念之一。每个讲微服务的文章中或多或少都会提及注册中心,但也只是一带而过,注册中心作为分布式系统或者微服务架构中最重要的一环,我觉得有必要写一篇单独的文章来详细的介绍一下,这也是有这篇文章的原因。
分布式系统的痛点
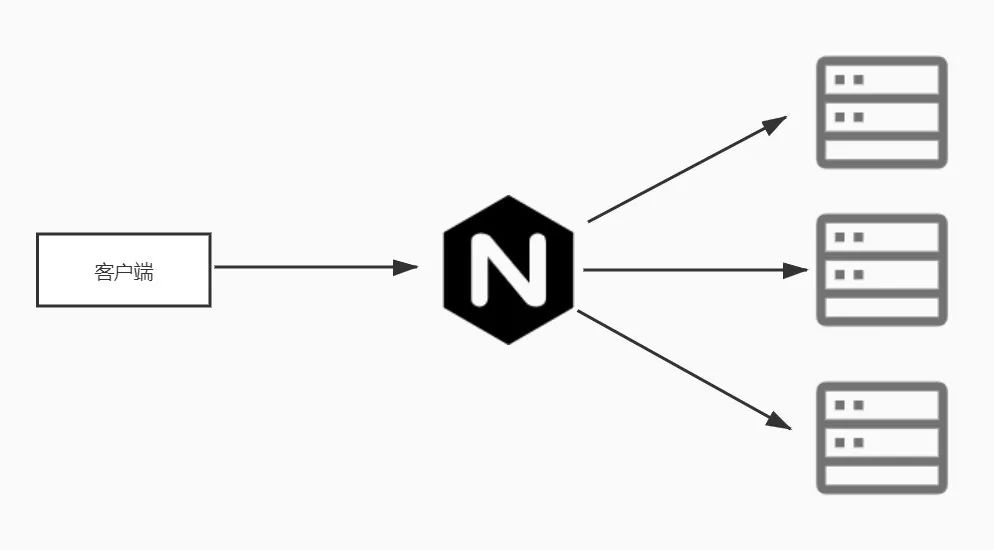
注册中心从架构的角度来讲,其实是一个统称的概念,并非现在流行的微服务所有,在很早之前利用Nginx做负载均衡(反向代理)的时候,Nginx会根据配置文件把每个请求根据配置的策略导向后端具体的处理程序,在这个流程中,站在客户端角度,Nginx很像一个网关,站在后端处理程序的角度,Nginx更像是服务的管理中心,它管理着所有可以提供服务的后端处理程序信息,并且还可以利用某些手段来达到服务的健康检查,服务的自动注册和剔除等操作。
当然现在流行微服务,网关和注册中心被分为两个并行的概念和组件。在重要性上来说,我觉得注册中心的权重要大于网关。现在十分流行单体服务拆分操作,但是这里我要强调一点,你的单体服务是否有必要拆分,还要根据很多情况来综合考虑,毕竟拆分成小的微服务并非没有代价。
在很早之前,如果客户端需要请求后端的多个服务,很多情况下后端的服务信息是写在请求方的配置文件中的,类似于这样
{
"ServiceA":[
"http://192.168.100.100",
"http://192.168.100.101",
"http://192.168.100.102"
]
}
这种方式固然是一种解决方案,但是随着系统的不断升级会遇到很多问题:
在系统需要扩容后端服务器的时候,需要手动修改客户端的配置文件,而且在多数情况下还需要重启客户端进程 当后端的一个服务节点出现故障的时候,需要手动删除客户端配置文件中对应的节点,而且在多数情况下还需要重启客户端进程 每次增加或者删除节点的时候需要人工干预,大大提高了维护成本
鉴于以上几个原因,注册中心应运而生。
注册中心的作用
注册中心不仅仅解决了服务节点的增加删除问题,而且在整个的查找服务可用节点的流程上做了修改,在搭配了服务健康检查的手段之后,更可以做到自动化。目前业界有很多可供选择的注册中心,比如ZooKeeper,ETCD,阿里的微服务注册中心 Nacos、Spring Cloud 的 Eureka 等等,之前菜菜的文章就有写过利用ETCD来实现一个配置中心
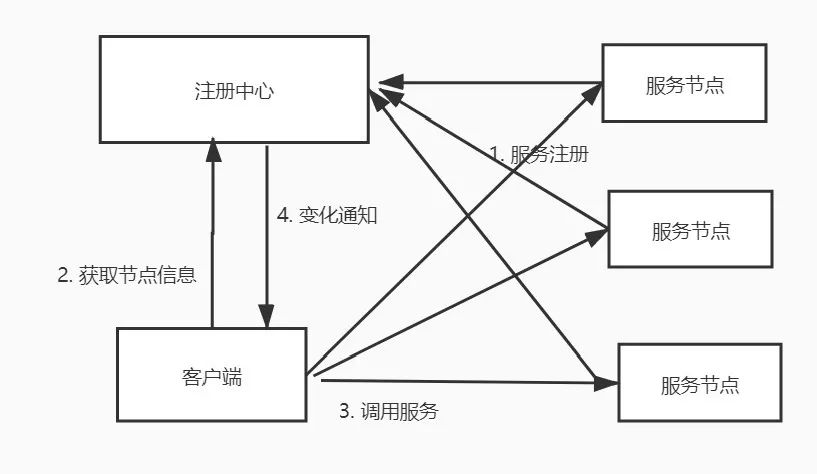
服务注册发现
服务的注册发现是注册中心提供的最基础也是最主要的功能:
当一个新的服务节点上线的时候,可以通过注册中心的接口进行注册,当一个服务节点发生故障的时候,注册中心会自动删除该服务节点 当注册中心的服务节点发生变化的时候,能够及时通知调用方,服务的调用方可以近乎实时的来更新可用的服务节点信息
负载均衡
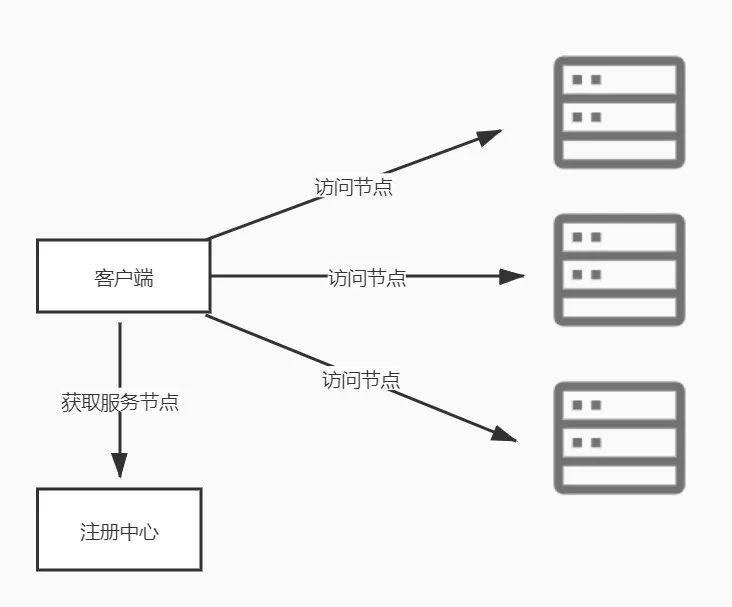
当客户端在注册中心获取到可用的服务节点之后,就可以根据轮训或者权重等策略来访问服务了,这种场景下注册中心更像一个负载均衡器,把流量导向多个不同的节点。
既然是负载均衡,在某种意义上讲就可以实现服务的横向扩展,说实话这确实没有什么问题,道理和Nginx做负载均衡道理类似。
那些坑
服务中心虽然在整体架构模式上解决了很多问题,但是在使用中我们也要直面它所带来的一些副作用,而且这些副作用有时候会成为整个系统瘫痪的导火线。
数据一致性问题
数据的一致性好像是所有系统都要面对的问题,注册中心也不例外。这里的一致性是指注册中心内存储的可用节点数据和后端真实可用节点以及客户端存储的可用节点之间的差异性问题。举个栗子:假如注册中心中存储了ABC三个服务节点信息,而这个时候节点A由于某种原因下线了,注册中心必须要及时把A节点移除掉,并且通知客户端也把A节点移除。
从理论上来讲,以上过程跨越了注册中心和调用方以及被调用方的交互流程,属于分布式中的事务问题,即:分布式事务问题。在之前菜菜的文章中也说过,分布式的事务要想保证严格的一致性必然会影响可用性
而且从目前主流的注册中心技术来看,注册中心和双方的通信流程属于异步流程,所以做不到实时的事务性要求。
目前注册中心在通知客户端变化的方面可以做到近乎于实时(其实并非实时),但是在监测后端服务节点是否可用的过程中,却很难做到近乎实时。其中的原因一是因为网络的不可靠特性,一次网络通信失败,并非意味着下次网络通信失败,二是监测后端服务可用的方式并非实时的。目前流行的两种探测后端服务可用的方式为:
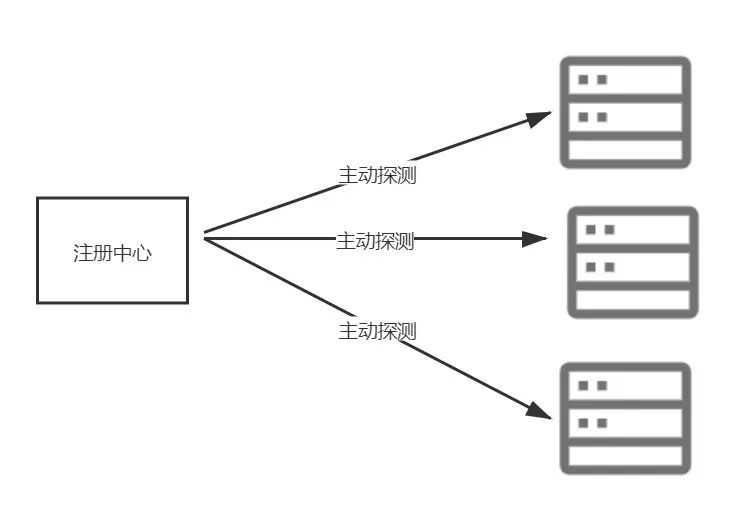
注册中心主动探测
很多注册中心的组件都支持这种方式,在这种方式下,后端的每个服务需要提供一个可供探测的接口或者端口,注册中心根据配置每隔一段时间去调用一次服务的接口或端口,如果返回正常就认为服务处于正常运行状态,否则则认为服务不可用,不可用的情况下注册中心会主动把当前服务移除列表,并通知客户端。
虽然这种方式看似很完美,其实还是有坑:
注册中心在探测的过程中,可能会由于网络问题而出错,但是服务其实是在正常运行状态,也就是说会产生误判的结果,当然这种问题,我们可以设置通过多次探测结果来确定,而不是通过一次探测结果就草草确定。 如果服务节点比较多,注册中心相当于承受了比较重的探测任务,会对注册中心的性能造成一定损失,影响它的可用性。 如果服务是以端口的形式开放探测接口,在服务较多的情况下可能会产生端口抢占的情况,毕竟这些服务可能会是不同团队开发的。
后端服务主动心跳
相比较注册中心主动探测的模式,我更喜欢使用服务主动上报心跳的模式。采用心跳的模式大体流程是这样的:
后端的每个服务节点都按照配置(这个配置可以修改)每隔固定时间就主动向注册中心发送心跳包,至于心跳包的内容可以协商约定,比如有的系统只发送ping命令,有的会发送比较详细的服务状态,比如cpu使用率,内存使用率等信息,然后注册中心就可以根据这些信息来做更精确的流量分配工作,比如,可以让资源充沛的服务节点承担更多的流量。 注册中心在接收到服务节点的心跳包之后,可以以滑动窗口的形式给服务节点续约时间(存活时间),只要服务节点不停的发送心跳包,注册中心就可以判定这个节点一直在正常运行。
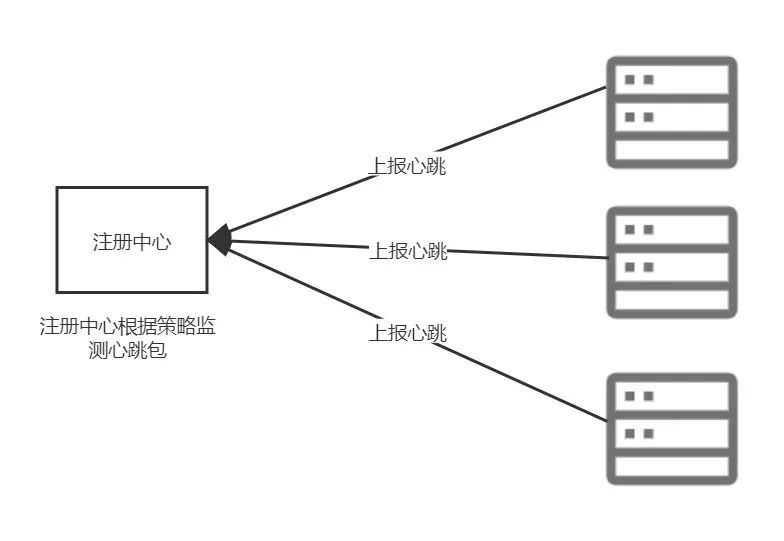
当然这个流程中也会有意外情况发生,比如由于网络情况,某个服务节点上报心跳失败,但是服务是在正常运行的,这种场景下,最直接的解决方案是:注册中心判断服务存活的时间窗口大于上报时间间隔即可,比如:心跳上报时间是10秒的话,注册中心判定服务不可用的时间窗口设置为30秒,既:三次心跳时间都没有上报心跳,就判定服务不可用。
当然以上只是注册中心的一个假设而已,其实系统可以结合主动探测的方式来判定服务是否可用,这样的话,结果的正确率会更高。也就是说:当服务的某个节点,超过配置的N次心跳时间仍然没有上报心跳数据,注册中心可以通过主动探测的方式来再次确定服务是否处于正常运行状态,当然,这在设计上增加了一定的复杂度,需要编写更多的代码。
还有一个不太常见的但是我们需要考虑的场景,假如所有的服务节点都因为网络异常情况而发生心跳上报超时,而且主动探测失败的情况,按照约定,注册中心会逐步移除所有的节点信息,这样造成的后果是系统肯定会出问题,有的时候系统设计的同时可以考虑一些保护措施,比如:当节点信息移除的数目大于一定比率的时候,就停止移除操作并且发送报警信息,这在一定程度上可以避免注册中心无节点数据的情况发生,当然客户端也可以有这样的保护策略。
通知风暴
虽然这个问题在多数情况下不算是个问题,但是还是有必要提及一下。当注册中心随着项目的升级承担起越来越多的服务节点的时候,服务间的调用链复杂度也随之上升,伴随而来的是新增一个节点可能要通知数十个客户端,移除一个节点也会有类似情况发生,如果有多个服务同时发生新增或移除节点操作,注册中心推送的消息将会更多。这样的场景下就需要系统设计者控制注册中心服务节点的数量来避免产生网络风暴,这个数量具体多少可以根据服务器的峰值带宽来确定。

更多精彩文章