
一文简单理解pulsar和优于kafka的两个痛点
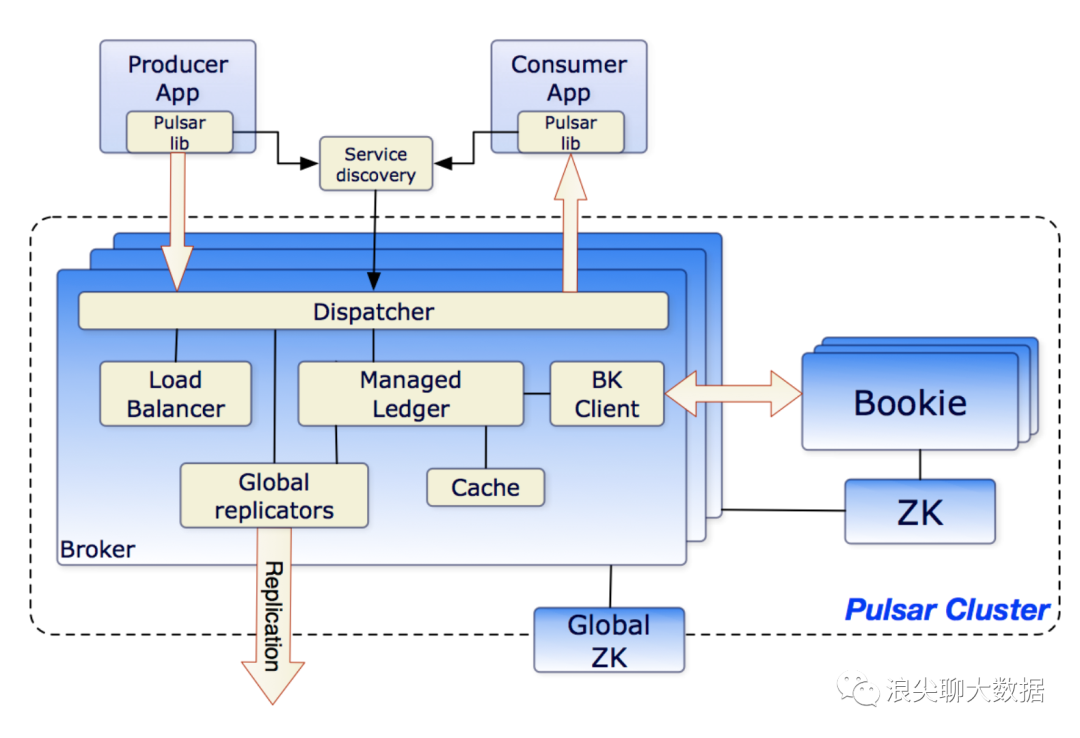
broker负责处理和负载均衡从producer接收到的消息。 broker也负责分发消息给consumer。 broker也负责和pulsar的配置存储同步,以应对多变的协调任务。 broker负责将消息存储到BookKeeper集群中。 broker也依赖zookeeper集群,负责元数据存储,集群配置,协调任务。 broker是无状态的,跟kafka的broker不同之处就是broker本书不会负责数据存储,数据存储是交给了BookKeeper。 等等
消息持久化投递-衍生出来的目的就是为了保证那些未确认送达的消息被再次消费处理的需求。
能让Pulsar创建多个独立的日志,这种独立的日志就是ledgers. 随着时间的推移,Pulsar会为Topic创建多个ledgers。
为按条目复制的顺序数据提供了非常高效的存储。
保证了多系统挂掉时ledgers的读取一致性。
提供不同的Bookies之间均匀的IO分布的特性。
容量和吞吐量都能水平扩展。并且容量可以通过在集群内添加更多的Bookies立刻提升。
Bookies被设计成可以承载数千的并发读写的ledgers。使用多个磁盘设备,一个用于日志,另一个用于一般存储,这样Bookies可以将读操作的影响和对于写操作的延迟分隔开。
除了消息数据,cursors也会被持久化入BookKeeper。Cursors是消费端订阅消费的位置。BookKeeper让Pulsar可以用一种可扩展的方式存储消费位置。

着重介绍下ledger
Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,这个ledger只会以只读模式打开。
最后,当ledger中的条目不再有用的时候,整个legder可以被删除(ledger分布是跨Bookies的)。
读一致性。由于ledger只能被一个进程(也就是写入器进程)写入,这样这个进程就不会在写入时不会有冲突,从而保证了写入的高效。在一次故障之后,ledger会启动一个恢复进程来确定ledger的最终状态并确认提交到日志的是哪一个条。这就保证了所有ledger读进程读取到相同的内容。
Managed ledgers 。
由于BookKeeper提供了单一的日志抽象,在ledger的基础上pulsar提供了一个叫做managed ledger的库,用于表示单个topic的存储层。managed ledger即消息流的抽象,有一个写入器进程不断在流结尾添加消息,并且有多个cursors消费这个流,每个cursor有自己的消费位置。
一个managed ledger在内部用多个BookKeeper ledgers保存数据,这么做有两个原因:
在故障之后,原有的某个ledger不难再写了,需要创建一个新的。
ledger在所有cursors消费完它所保存的消息之后就可以被删除了,这样可以实现ledgers的定期翻滚从头写。
配置和仲裁存储:
存储租户,命名域和其他需要全局一致的配置项。
每个集群有自己独立的zookeeper保存集群内部的配置和协调信息,例如归属信息,broker负载报告,BookKeeper ledger信息(这个是BookKeeper自身的依赖)等等。
Pulsar 通过“订阅”,抽象出了统一的: producer-topic-subscription-consumer 消费模型。Pulsar 的消息模型既支持队列模型,也支持流模型。
生产者没啥好介绍的,重点介绍一下,消费者的订阅模式。pulsar也有topic的概念,每个topic对应着BookKeeper中的一个分布式日志。生产者发送消息到指定topic,然后bookKeeper会讲消息存储到多个节点上。topic的消息可以被反复订阅。
跟kafka一样,一个topic可以被多个消费者组消费,不同的是pulsar的每个消费者组可以拥有自己不同的消费方式:独占(Exclusive),故障切换(Failover)或共享(Share)。
独占订阅(Stream 流模型)
一个消费者组
有且仅有一个消费者消费topic的消息。任何新加消费者都不被允许。独占模式消费者体现互斥性。

故障切换(Stream 流模型)
多个消费者可以添加到同一个消费者组订阅中,但是一个订阅中的所有消费者,只能有一个活跃的消费者作为主消费者。其他消费者是备胎型消费者。
顺序性和安全性有点保证。

共享订阅(Queue 队列模型)
该模式同一个订阅组可以按照需要挂在多个消费者。topic中的所有消息以循环分发的形式发送给订阅组内的多个消费者,一个消息仅传递给一个消费者。
当消费者断开连接时,所有传递给它但是未被确认(ack)的消息将被重新分配和组织,以便发送给该订阅上剩余的剩余消费者。
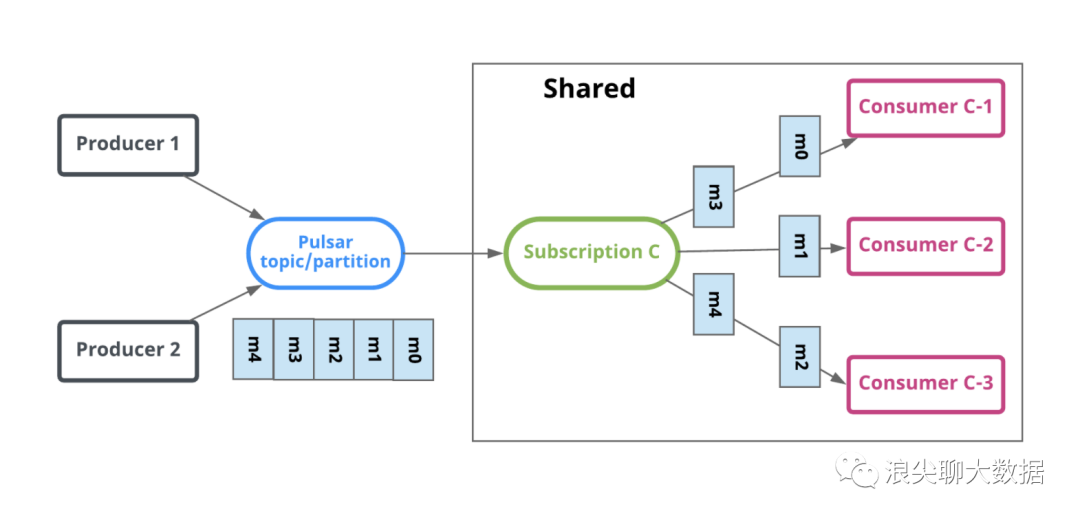
无顺序性。
kafka集群容量受限于做弱的机器最小的磁盘,当然这种不均衡很少发生,企业中kafka的机器配置往往最硬的。
kafka扩容感觉管理过kafka的朋友都应该体会过其复杂,扩容难点: