
一文理解Kafka的选举机制与Rebalance机制
Kafka是一个高性能,高容错,多副本,可复制的分布式消息系统。在整个系统中,涉及到多处选举机制,被不少人搞混,这里总结一下,本篇文章大概会从三个方面来讲解。
控制器(Broker)选举机制
分区副本选举机制
消费组选举机制
如果对Kafka不了解的话,可以先看这篇博客《一文快速了解Kafka》。
控制器选举
控制器是Kafka的核心组件,它的主要作用是在Zookeeper的帮助下管理和协调整个Kafka集群。集群中任意一个Broker都能充当控制器的角色,但在运行过程中,只能有一个Broker成为控制器。
控制器的作用可以查看文末
控制器选举可以认为是Broker的选举。
集群中第一个启动的Broker会通过在Zookeeper中创建临时节点/controller来让自己成为控制器,其他Broker启动时也会在zookeeper中创建临时节点,但是发现节点已经存在,所以它们会收到一个异常,意识到控制器已经存在,那么就会在Zookeeper中创建watch对象,便于它们收到控制器变更的通知。
那么如果控制器由于网络原因与Zookeeper断开连接或者异常退出,那么其他broker通过watch收到控制器变更的通知,就会去尝试创建临时节点/controller,如果有一个Broker创建成功,那么其他broker就会收到创建异常通知,也就意味着集群中已经有了控制器,其他Broker只需创建watch对象即可。
如果集群中有一个Broker发生异常退出了,那么控制器就会检查这个broker是否有分区的副本leader,如果有那么这个分区就需要一个新的leader,此时控制器就会去遍历其他副本,决定哪一个成为新的leader,同时更新分区的ISR集合。
如果有一个Broker加入集群中,那么控制器就会通过Broker ID去判断新加入的Broker中是否含有现有分区的副本,如果有,就会从分区副本中去同步数据。
防止控制器脑裂
如果控制器所在broker挂掉了或者Full GC停顿时间太长超过zookeepersession timeout出现假死,Kafka集群必须选举出新的控制器,但如果之前被取代的控制器又恢复正常了,它依旧是控制器身份,这样集群就会出现两个控制器,这就是控制器脑裂问题。
解决方法:
为了解决Controller脑裂问题,ZooKeeper中还有一个与Controller有关的持久节点/controller_epoch,存放的是一个整形值的epoch number(纪元编号,也称为隔离令牌),集群中每选举一次控制器,就会通过Zookeeper创建一个数值更大的epoch number,如果有broker收到比这个epoch数值小的数据,就会忽略消息。
分区副本选举机制
由控制器执行。
从Zookeeper中读取当前分区的所有ISR(in-sync replicas)集合。
调用配置的分区选择算法选择分区的leader。
Unclean leader选举
ISR是动态变化的,所以ISR列表就有为空的时候,ISR为空说明leader副本也挂掉了。此时Kafka要重新选举出新的leader。但ISR为空,怎么进行leader选举呢?
Kafka把不在ISR列表中的存活副本称为“非同步副本”,这些副本中的消息远远落后于leader,如果选举这种副本作为leader的话就可能造成数据丢失。所以Kafka broker端提供了一个参数unclean.leader.election.enable,用于控制是否允许非同步副本参与leader选举;如果开启,则当 ISR为空时就会从这些副本中选举新的leader,这个过程称为 Unclean leader选举。
可以根据实际的业务场景选择是否开启Unclean leader选举。一般建议是关闭Unclean leader选举,因为通常数据的一致性要比可用性重要。
消费组选主
在Kafka的消费端,会有一个消费者协调器以及消费组,组协调器(Group Coordinator)需要为消费组内的消费者选举出一个消费组的leader。
如果消费组内还没有leader,那么第一个加入消费组的消费者即为消费组的leader,如果某一个时刻leader消费者由于某些原因退出了消费组,那么就会重新选举leader,选举方式如下:
private val members = new mutable.HashMap[String, MemberMetadata]
leaderId = members.keys.headOption
在组协调器中消费者的信息是以HashMap的形式存储的,其中key为消费者的member_id,而value是消费者相关的元数据信息。而leader的取值为HashMap中的第一个键值对的key(等同于随机)。
消费组的Leader和Coordinator没有关联。消费组的leader负责Rebalance过程中消费分配方案的制定。
消费端Rebalance机制
就Kafka消费端而言,有一个难以避免的问题就是消费者的重平衡即Rebalance。Rebalance是让一个消费组的所有消费者就如何消费订阅topic的所有分区达成共识的过程,在Rebalance过程中,所有Consumer实例都会停止消费,等待Rebalance的完成。因为要停止消费等待重平衡完成,因此Rebalance会严重影响消费端的TPS,是应当尽量避免的。
触发Rebalance的时机
Rebalance 的触发条件有3个。
消费组成员个数发生变化。例如有新的Consumer实例加入或离开该消费组。
订阅的 Topic 个数发生变化。
订阅 Topic 的分区数发生变化。
Rebalance 发生时,Group 下所有Consumer 实例都会协调在一起共同参与,kafka 能够保证尽量达到最公平的分配。但是 Rebalance 过程对 consumer group 会造成比较严重的影响。在 Rebalance 的过程中 consumer group 下的所有消费者实例都会停止工作,等待 Rebalance 过程完成。
Rebalance过程
Rebalance过程分为两步:Join和Sync。
Join。所有成员都向Group Coordinator发送JoinGroup请求,请求加入消费组。一旦所有成员都发送了JoinGroup请求,Coordinator会从中选择一个Consumer担任leader的角色,并把组成员信息以及订阅信息发给leader——注意leader和coordinator不是一个概念。leader负责消费分配方案的制定。
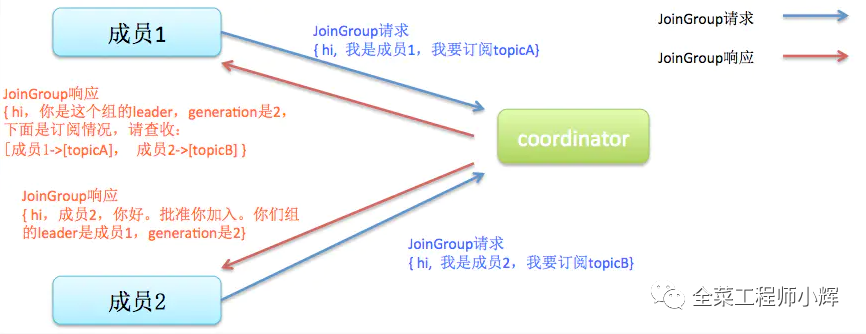
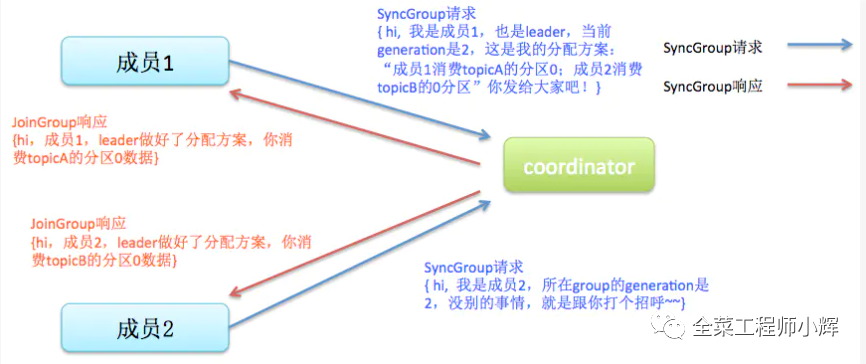
Sync。这一步leader开始分配消费方案,即哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer。这样组内的所有成员就都知道自己应该消费哪些分区了。
避免不必要的Rebalance
前面说过Rebalance发生的时机有三个,后两个时机是可以人为避免的。发生Rebalance最常见的原因是消费组成员个数发生变化。
这其中消费者成员正常的添加和停掉导致Rebalance,也是无法避免。但是在某些情况下,Consumer实例会被Coordinator错误地认为已停止从而被踢出Group。从而导致rebalance。
这种情况可以通过Consumer端的参数session.timeout.ms和max.poll.interval.ms进行配置。
有关这种情况,可以查看博客《一文理解Kafka重复消费的原因和解决方案》
除了这个参数,Consumer还提供了控制发送心跳请求频率的参数,就是heartbeat.interval.ms。这个值设置得越小,Consumer实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更快地知道是否开启Rebalance,因为Coordinator通知各个Consumer实例是否开启Rebalance就是将REBALANCE_NEEDED标志封装进心跳请求的响应体中。
总之,要为业务处理逻辑留下充足的时间使Consumer不会因为处理这些消息的时间太长而引发Rebalance,但也不能时间设置过长导致Consumer宕机但迟迟没有被踢出Group。
补充
Kafka控制器的作用
Kafka控制器的作用是管理和协调Kafka集群,具体如下:
主题管理:创建、删除Topic,以及增加Topic分区等操作都是由控制器执行。
分区重分配:执行Kafka的reassign脚本对Topic分区重分配的操作,也是由控制器实现。
Preferred leader选举。
因为在Kafka集群长时间运行中,broker的宕机或崩溃是不可避免的,leader就会发生转移,即使broker重新回来,也不会是leader了。在众多leader的转移过程中,就会产生leader不均衡现象,可能一小部分broker上有大量的leader,影响了整个集群的性能,所以就需要把leader调整回最初的broker上,这就需要Preferred leader选举。
集群成员管理:控制器能够监控新broker的增加,broker的主动关闭与被动宕机,进而做其他工作。这也是利用Zookeeper的ZNode模型和Watcher机制,控制器会监听Zookeeper中/brokers/ids下临时节点的变化。
数据服务:控制器上保存了最全的集群元数据信息,其他所有broker会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
Kafka协调器
Kafka中主要有两种协调器:
组协调器(Group Coordinator)
消费者协调器(Consumer Coordinator)
Kafka为了更好的实现消费组成员管理、位移管理以及Rebalance等,broker服务端引入了组协调器(Group Coordinator),消费端引入了消费者协调器(Consumer Coordinator)。
每个broker启动时,都会创建一个组协调器实例,负责监控这个消费组里的所有消费者的心跳以及判断是否宕机,然后开启消费者Rebalance。
每个Consumer启动时,会创建一个消费者协调器实例并会向Kafka集群中的某个节点发送FindCoordinatorRequest请求来查找对应的组协调器,并跟其建立网络连接。
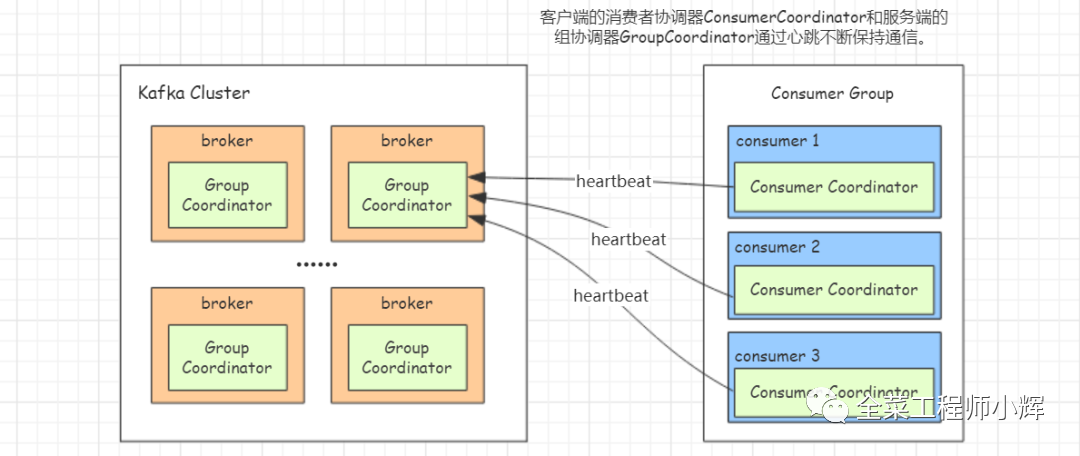
客户端的消费者协调器和服务端的组协调器会通过心跳保持通信。
Kafka舍弃ZooKeeper的理由
Kafka目前强依赖于ZooKeeper:ZooKeeper为Kafka提供了元数据的管理,例如一些Broker的信息、主题数据、分区数据等等,还有一些选举、扩容等机制也都依赖ZooKeeper。
运维复杂度
运维Kafka的同时需要保证一个高可用的Zookeeper集群,增加了运维和故障排查的复杂度。
性能差
在一些大公司,Kafka集群比较大,分区数很多的时候,ZooKeeper存储的元数据就会很多,性能就会变差。
ZooKeeper需要选举,选举的过程中是无法提供服务的。
Zookeeper节点如果频繁发生Full Gc,与客户端的会话将超时,由于无法响应客户端的心跳请求,从而与会话相关联的临时节点也会被删除。
所以Kafka 2.8版本上支持内部的quorum服务来替换ZooKeeper的工作。