
一文理解Kafka如何做到高吞吐
如果对Kafka不了解的话,可以先看这篇博客《一文快速了解Kafka》。
其余有关Kakfa的文章如下:
Kafka高吞吐量的原因
kafka高效文件存储设计特点
Kafka把topic中一个Parition大文件分成多个小文件segment,通过多个小文件segment,就容易定期清除或删除已经消费完的文件,减少磁盘占用。
为了进一步的查询优化,Kafka默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。
索引文件通过稀疏存储,降低index文件元数据占用的空间大小。
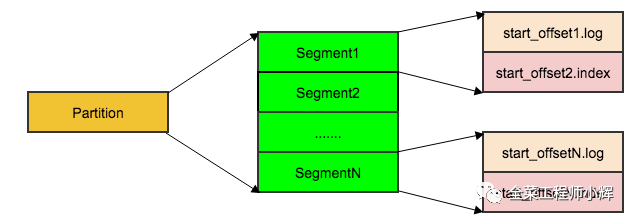
每个Partition分为多个Segment,每个Segment有.log和.index两个文件。每个log文件记录具体的数据,每条消息都有一个递增的offset;Index文件是对log文件的索引。Consumer查找offset时使用的是二分法根据文件名去定位到Segment,然后解析msg,匹配到对应的offset的msg。
顺序写入
因为硬盘每次读写都会寻址和写入,其中寻址是一个耗时的操作。所以为了提高读写硬盘的速度,Kafka使用顺序I/O,来减少了寻址时间:收到消息后Kafka会把数据插入到文件末尾,每个消费者(Consumer)对每个Topic都有一个offset用来表示读取的进度。
因为顺序写入的特性,所以Kafka是无法删除数据的,它会将所有数据都保留下来。
Page Cache
为了优化读写性能,Kafka使用操作系统缓存——Page Cache,而不是JVM空间内存。
这样做的优势:
避免Broker内存消耗。如果使用Java堆,Java对象的内存消耗会比较大;操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。
避免GC问题。随着JVM中数据不断增多,垃圾回收将会变得复杂与缓慢,使用Page Cache就不会存在GC问题。
应用重启,系统缓存不会消失。
通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
Page Cache配合mmap技术(直接内存映射),实现了用户态和内核态对指定内存区域的共享。
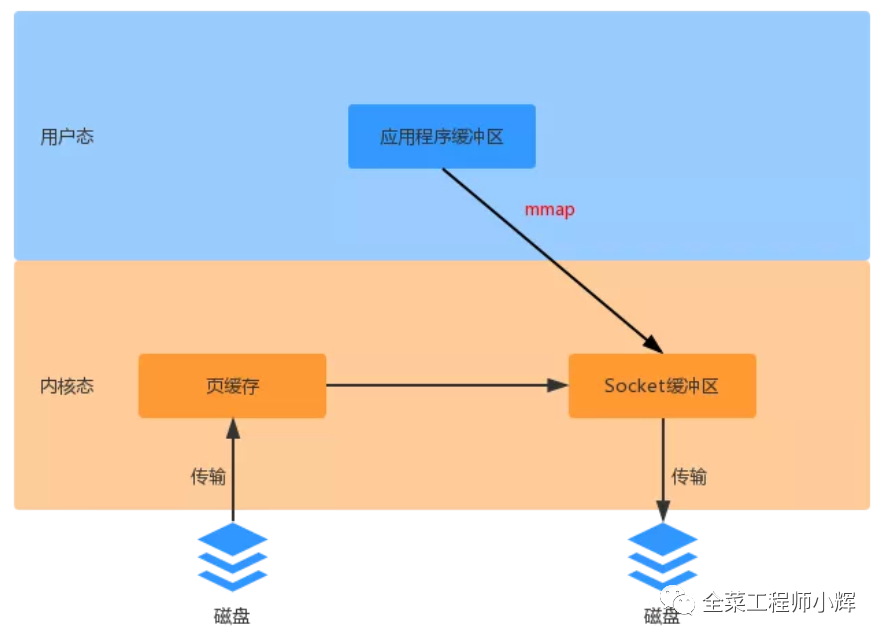
零拷贝
kafka基于sendfile实现零拷贝,数据不需要在应用程序做业务处理,仅仅是从一个DMA设备传输到另一个DMA设备。此时数据只需要复制到内核态,用户态不需要复制数据,然后发送网卡。
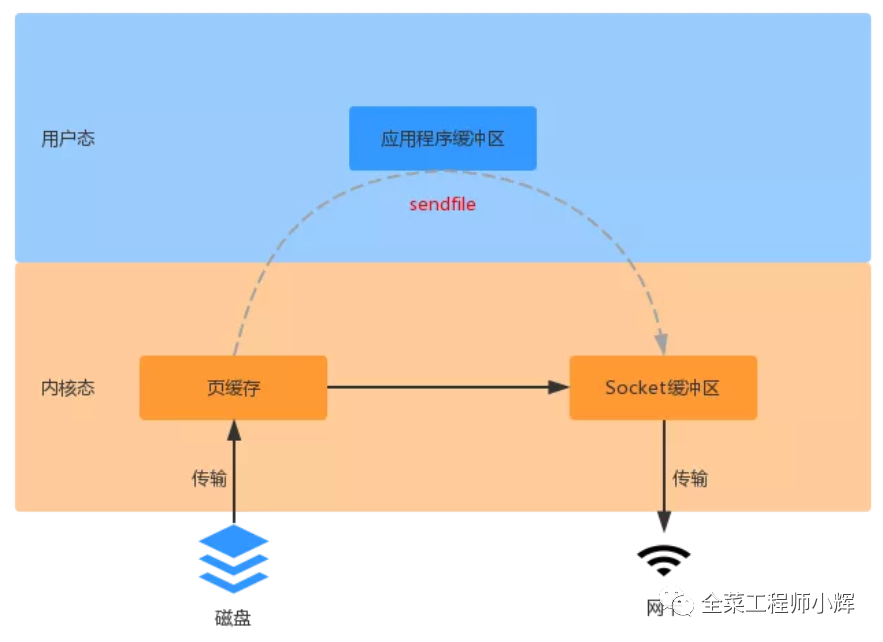
sendfile是Linux 2.1开始引入的,在Linux 2.4又做了一些优化:上图中磁盘页缓存中的数据,不需要复制到Socket缓冲区,而将数据的位置和长度信息存储到Socket缓冲区。实际数据是由DMA设备直接发送给对应的协议引擎,从而又减少了一次数据复制。
零拷贝并不是Kafka特有的机制,而是一种操作系统的底层支持,在NIO和Netty中都有应用,可以查看博客《NIO效率高的原理之零拷贝与直接内存映射》与《彻底搞懂Netty高性能之零拷贝》
批量压缩
Kafka支持多种压缩协议(包括Gzip和Snappy压缩协议),将消息进行批量压缩。
效果与Nginx压缩类似,都是牺牲部分CPU性能换取IO吞吐量的提升。
批量发送
生产者发送多个消息到同一个分区的时候,为了减少网络带来的系能开销,kafka会对消息进行批量发送:
batch.size:通过这个参数来设置批量提交的数据大小,默认是16k。当积压的同一分区的消息达到这个值的时候就会统一发送。linger.ms:这个设置是配合batch.size一起来设置,可避免消息长时间凑不满单位的Batch,导致消息一直积压在内存里发送不出去的情况。默认大小是0ms(就是有消息就立即发送)。
上面两个参数条件,只要满足一个就会发送消息。
补充
消息写的过程
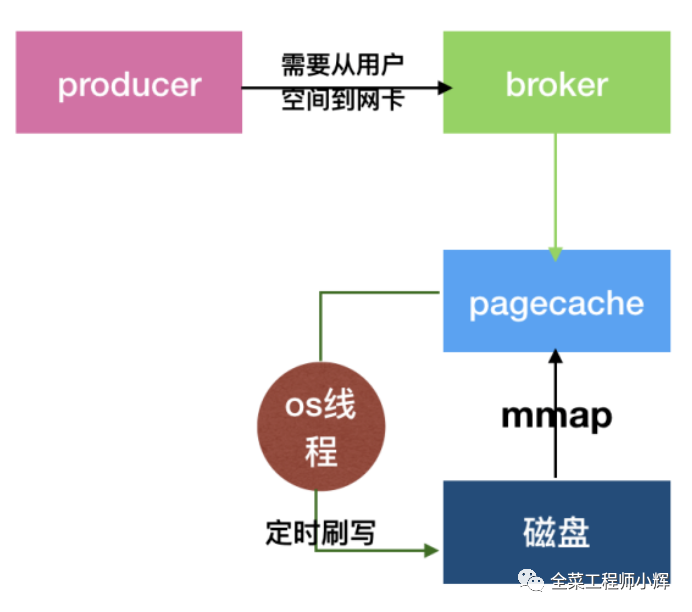
生产者发送批量压缩的数据到broker。
broker通过直接内存映射,直接将数据写入Page Cache中。
过一段时间之后,由os的线程异步将Page Cache数据刷入磁盘中。
消息读的过程
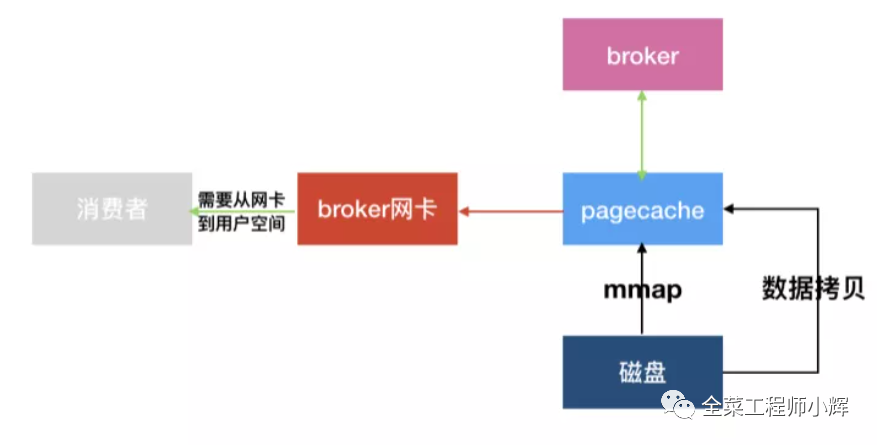
读取数据的时候,broker会先判断Page Cache中是否存在数据:存在就可以直接从Page Cache中消费,所以消费实时数据就会速度快很多。
消费历史数据就需要将历史数据从磁盘重新加载到Page Cache。Page Cache在加载历史数据的时候,会将加载的数据块临近的其他数据块一起加载到Page Cache里去,这是一个预读过程,对于需要连续读取历史数据的,也是不小的性能优化。