
Python处理Excel的另一个库-openpyxl
咪哥杂谈

本篇阅读时间约为 5 分钟。
1
前言
上篇文章中,介绍了如何使用 Pandas 来操作处理 Excel 和 Csv 文件。其中留下了一个点,即图片头像现在在 Excel 中依然是地址,现在需要将地址转为图片,写入到 Excel。
今天来介绍另一个好用的库 openpyxl ,Python操作处理 Excel 的神库。
回顾上篇文章详见:Python处理Excel&CSV文件
2
环境准备
开始之前,需要安装的第三方库有两个:
pip install openpyxlpip install pillow
3
代码演示
下面来简单介绍下我完成这次图片写入用到的功能,完整代码文末提供地址:
1. 初始化时加载,读和写的操作对象
class Excel(object):def __init__(self, file):self.file = fileself.wb = load_workbook(self.file) # 加载,可读sheets = self.wb.sheetnames # 获取所有sheet页self.sheet = sheets[0] # 默认第一sheet页self.ws = self.wb[self.sheet] # 切换到sheet页
self.wb 是读 Excel 时用到的,self.ws 则是写入时用到的。
2. 获取某列的所有值
由于我需要读取头像图片地址,所以就得需要这一列的地址:
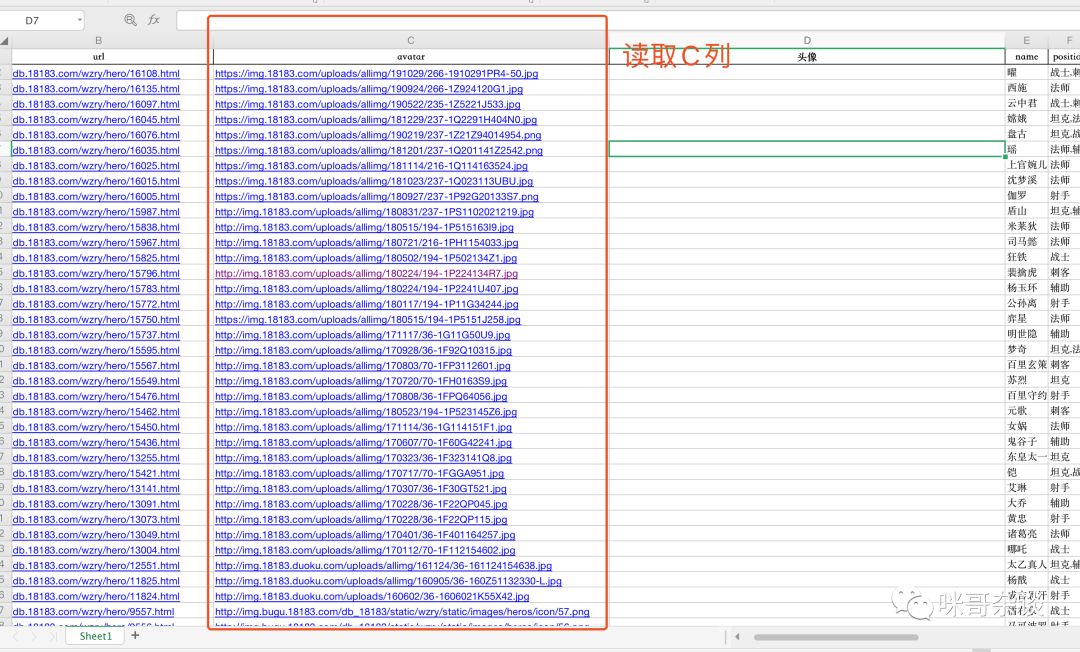
class Excel(object):# 获取某列的所有值def get_col_values(self, column):rows = self.ws.max_rowcolumn_data = []for i in range(1, rows + 1):cell_value = self.ws.cell(row=i, column=column).valuecolumn_data.append(cell_value)return column_data
注意,这里的 column 是从 1 开始的,Excel 中 A 列意味着 column 等于 1,所以传值的时候注意列数的数字。
3. 重塑图片大小,重新写入文件,设置行高列高。
重新定义图片大小是为了整齐,从网站下载下来的图片大小不一。
from PIL import Image as PILImageimg= PILImage.open(img_path)image = img.resize((75, 75), PILImage.ANTIALIAS) # 重构图片大小,设置为 75 像素image.save(img_path)
定义单元格行宽高:
class Excel(object):# 设置单元格宽度和高度def set_cell_height(self, row, col, row_height, column_weight):self.ws.row_dimensions[row].height = row_heightself.ws.column_dimensions[col].width = column_weight
4. 设置某列的值
通过 requests 库读取到图片,落地,再次设置图片。
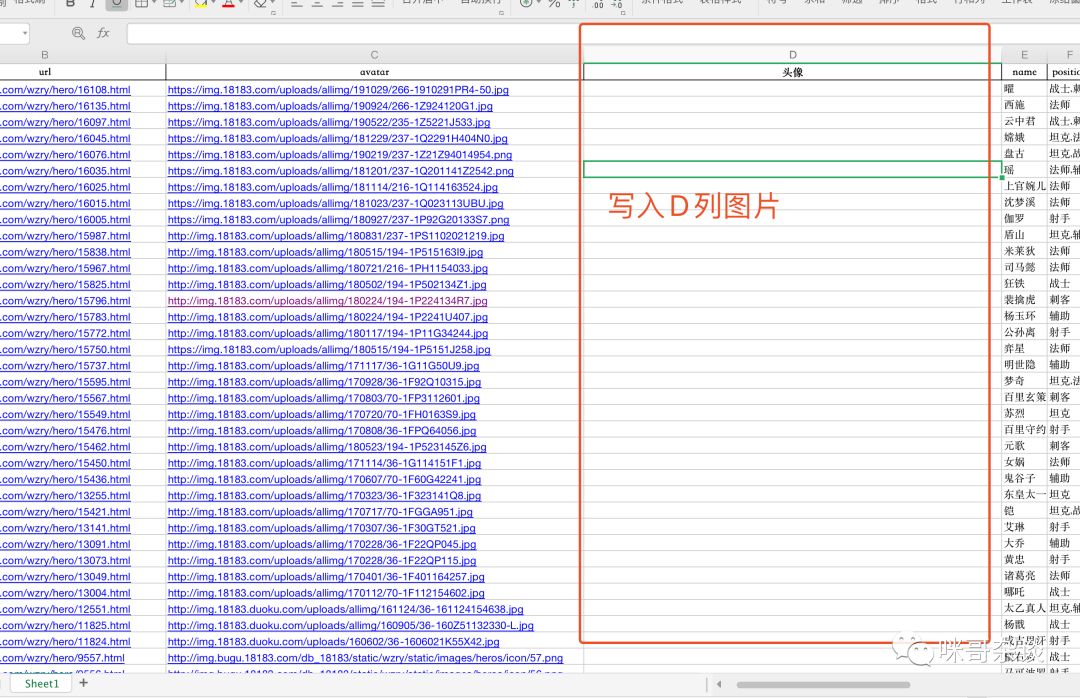
classExcel(object):# 设置某个单元格的值def set_cell_value(self, row, column, cell_value):try:if isinstance(cell_value, Image):self.ws.add_image(cell_value, f'{row}{column}')else:self.ws.cell(row=row, column=column).value = cell_valueexcept Exception as e:self.ws.cell(row=row, column=column).value = "None"
5. 保存文件
class Excel(object):# 保存文件def save_file(self, file_name=None):if file_name:self.wb.save(file_name)else:self.wb.save(self.file)
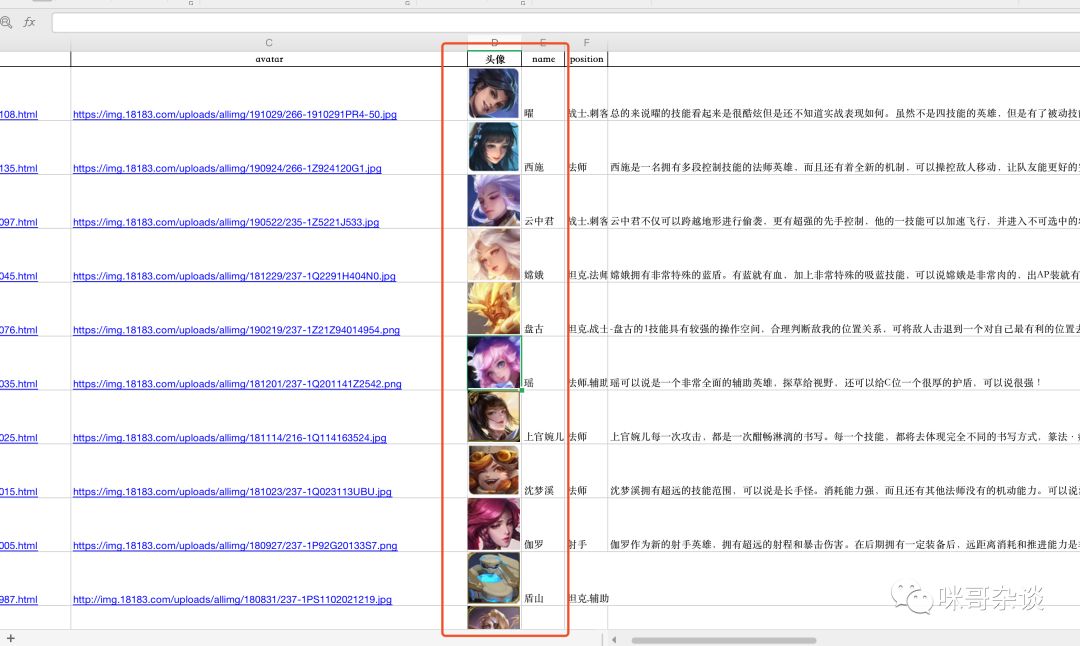
可以看到这样是不是就很整齐了呢?
4
使用对比pandas库处理Excel
通过这两篇文章比较,个人觉得还是 pandas 库操作数据方便些。但不同场景下使用也不同。
比如我要写入图片,可能 pandas 支持就不那么好,但比如我想合并多个 Excel ,那无疑使用 pandas 的 concat 函数要简单的多。
可以说,openpyxl 库更多地是对 Excel 细节操作的实现,而 Pandas 多数注重于数据的处理,大家根据自己的场景需求选择使用就好~
5
总结
有想看这章完整代码的朋友,可以后台回复 最终王者 即可获得。
题图 :
Tirachard Kumtanom - pexels
pyspider爬取王者荣耀数据(下)
 你点的每个在看,我都认真当成了喜欢
你点的每个在看,我都认真当成了喜欢评论