
可观测系统实践:基于海量数据的采集优化方案
可观测性并不是最近才出现的新概念,但云原生时代的可观测系统确实是最近几年才开始快速发展起来的,这是当前云原生时代系统的复杂性和规模性结合的必然结果。
可观测系统将系统各个环节原本隔离的数据采集到一个统一的平台上,从全局的视角进行分析和处理,能够对系统中存在的异常进行风险预测。
软件系统所有环节的可观测数据都会被采集到可观测系统中进行统一的分析和处理,这包括了云和基础设施、系统和容器、中间件、业务框架、业务服务这几部分的数据,如图1所示。从中我们可以轻易地发现,可观测系统中的数据量必然是巨大的。
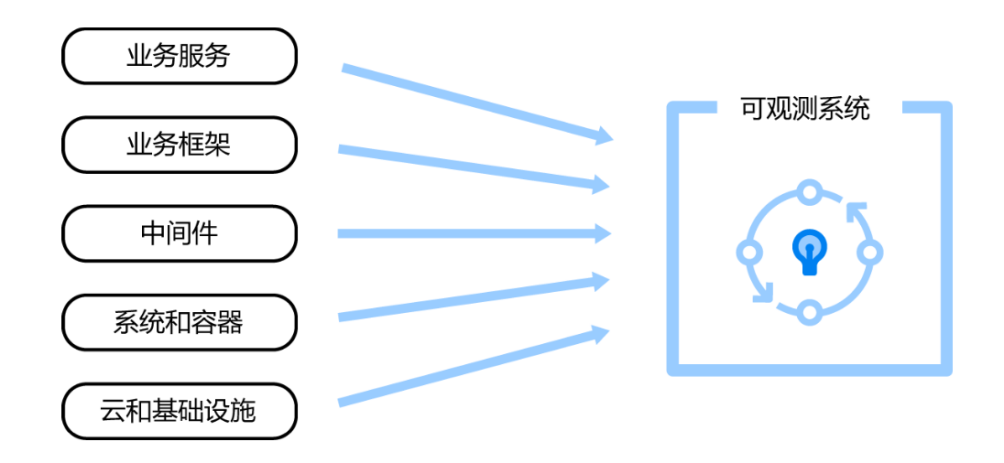
图1
对于这样的海量数据来说,采集无疑也是一个巨大的技术难题,尤其是要对整个系统的健康情况做到及时的了解,以及对系统中出现的异常和潜在的风险做出及时的响应,既需要数据完整的上报到平台,也需要数据能够及时上报到平台。
01
数据采集方案
可观测数据采集的原理是通过对指定位置的埋点,将系统进行可观测分析所必要的数据采集出来,并上报到可观测平台。
这里进行数据采集的方案主要可以分为两种类型,一种是由业务服务和可观测平台之间直接通信,将数据直接推送到可观测平台,如图2所示。
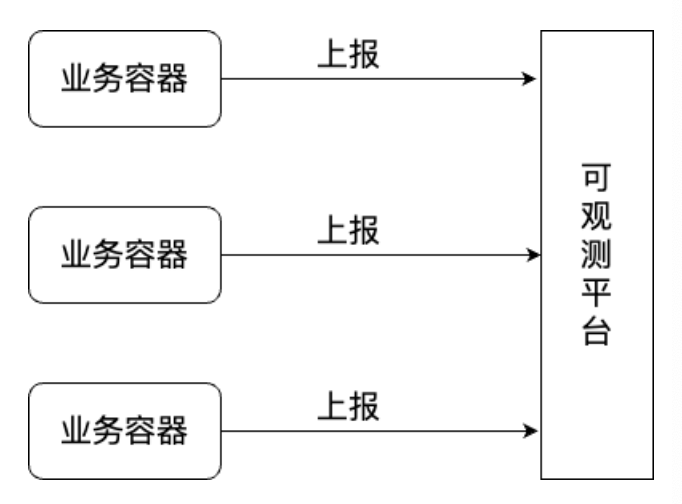
图2
另一种是将数据存放在本地,由采集组件将数据进行采集之后推送到可观测平台,如图3所示。
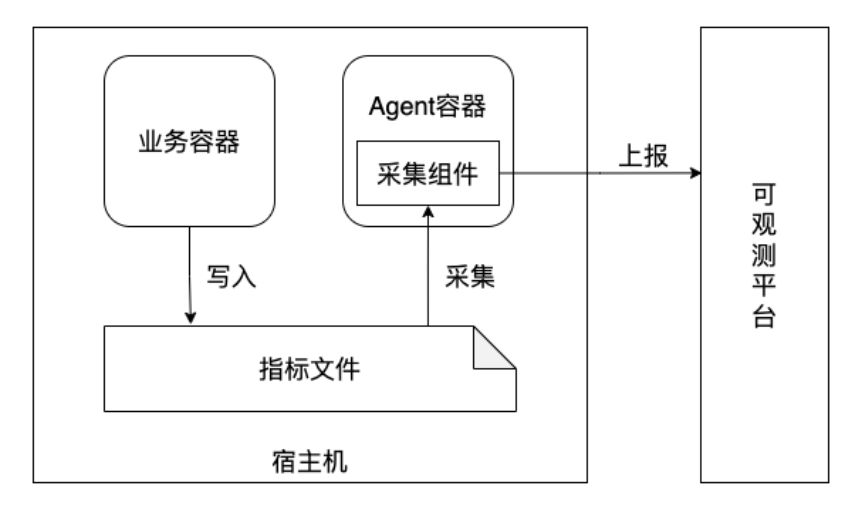
图3
通过图2和图3的采集架构图可以直观的看出两种采集方案从原理上的区别。
通过业务服务直接上报,可以保证数据的实时性,同时架构简单,不需要额外的组件支持,但是在业务容器中进行数据上报,会占用业务容器的资源,在业务出现快速飙升的时候,可观测数据上报对资源的占用也会增多,当业务服务出现异常时,也可能会导致可观测数据上报异常。
通过将数据写入文件,在通过文件采集组件进行上报的方式可以保证数据的完整性,遇到服务异常中断时,也不必担心当前数据是否上报完全,只要数据写入了文件,最终一定会全部完成上报。但是这样也会带来一个额外的采集组件,系统复杂度提升,同时维护成本增加。
02
数据采集优化
基于数据采集的原理,在海量数据的场景下,想要对数据采集进行优化,要保证数据上报的完整性和实时性,那么可以通过对埋点和采集上报两个环节进行优化。
首先是对于埋点的情况,对于大多数组件和业务来说,埋点是通过开源或者公共的组件进行,本身没有太多的优化空间,但是我们可以通过调整采样率来进行数据采集的优化。
使用链路追踪系统全量地跟踪系统调用情况,会产生大量的数据,而这些链路数据大部分是不需要使用到的,对系统资源造成了大量的浪费,同时还会对系统性能造成影响。
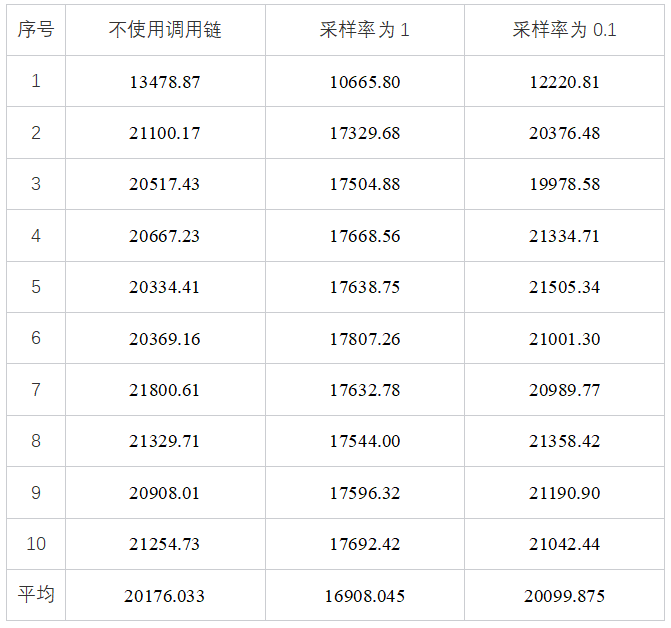
使用Spring Cloud Sleuth采集链路数据,并将链路数据上报到Zipkin Server的场景进行压测,压测结果是服务QPS的数据,如下表所示,在采样率为0.1时,对系统性能几乎没有影响,但在采样率为1,即全部采集上报的场景下,性能有16%左右的损耗,这个损耗率在系统压力比较大的时候会产生很大的影响。
为了避免影响系统性能,以及节省资源,对链路追踪系统进行采样是非常有必要的。采样技术主要分为 3 种类型:基于头部的采样、基于尾部的采样和单元采样。
1. 基于头部的连贯采样
基于头部的连贯采样(以下简称头采)是在业务采集侧决定该链路是否采样,并且为了采样的连贯性,每条调用链都是在链路的起始服务就决定了是否需要采样。这种采样算法对每个请求基本上都有平等的抽样概率。例如,Spring Cloud Sleuth中采用的是头采,在生成调用链时就决定了这条链路最终是否会被采样。
头采的优点是实现简单。例如,在 Spring Cloud Sleuth 中,默认有两种采样算法是基于头采实现的,分别是 ProbabilityBasedSampler和RateLimitingSampler。
其中,ProbabilityBasedSampler 通过采样率百分比的方式进行采样,RateLimitingSampler通过配置每秒采集的最大请求量进行采样。在起始服务生成调用信息时就已经决定了这条链路是否最终被采样,在后续的服务中根据是否采样的标志判断即可。使用头采可以减少大量上报的数据,极大地降低了对应用的性能损耗。
头采的缺点也十分明显,在分布式系统中,一个请求往往要经过几个甚至几十个服务,起始服务生成调用链时不知道后续服务是否存在异常。另外使用头采会使一些异常调用的数据在起始服务中就可以决定该链路不采样而被丢弃。
2. 基于尾部的连贯采样
基于尾部的连贯采样(以下简称尾采)的每条调用链都是在调用完成后,在服务端根据规则决定这条调用链是否需要被采样,所以需要将链路信息进行缓存,在决定是否采样之后才存储数据或丢弃数据,以保证数据的连贯性。
这种采样算法可以利用一些规则对链路数据进行采样,如请求慢的或错误请求链路数据更有价值,在采样过程中可以偏重采集这些更具有价值的数据,使最终采集上报的数据更具有使用价值。
尾采的优点是当调用完成后根据调用链的耗时、状态等决定是否被采样,这样采集的就是一条连贯的链路。例如,在调用链中,将所有耗时大于10秒的数据全部采样,这样就能保留所有耗时较长的异常数据,从而根据这些数据分析系统中耗时异常的情况和根因。又如,在调用链中,将所有错误的调用链全部采样,这样就可以保留所有调用发生错误的调用链现场数据,用于分析错误原因。
尾采的缺点也显而易见,需要将调用链数据上报到服务端才能决定是否采样,对于应用侧的 性能损耗并不能减少,同时在高并发的压力下还会增加服务端采样计算的难度,但是这样能节省服务端存储组件的资源。
3. 单元采样
单元采样是一种非连贯的采样机制,每条调用链分别由每个Span的服务决定其数据是否采样上报。这种采样机制由每个服务决定自身的链路采样情况,因此上报的链路数据不是完整的。
由于单元采样和头采都是在业务采集侧决定是否采集该链路,因此单元采样兼具头采的优点,可以降低链路组件对应用的性能损耗,同时可以根据当前服务链路的情况决定是否上报该Span的链路数据。另外,系统中99%的链路是设有价值的,采用单元采样可以根据链路情况上报有价值的数据。
单元采样的缺点是上报的不是完整的链路数据,通常只有当前异常的这一个或几个Span的链路数据。例如,对于慢调用的采样,只有当前链路中耗时超过了慢调用阈值的Span会被采样,并不会对整个链路中的所有Span进行采样。
其次是我们在方案选择上,优先考虑通过将数据写入文件,再用采集组件对文件数据进行采集上报的方案,这样可以通过调整采集策略,使数据上报可以尽可能的实时且全面。
在当前云原生的场景下,我们的服务都是部署在容器集群上,通常会以一个服务实例就是一个容器的方式进行运行。在这种背景下,我们可以将采集组件和业务服务分开,分别部署到两个容器上,将服务的可观测性数据写入一个挂载的目录中,这样即使业务服务的容器遇到异常中断,也不会导致文件无法使用。
同时由于采集组件部署在另外一个容器,所以采集组件带来的额外性能压力也完全不影响业务服务的运行。数据上报的实时性就由采集组件所决定,和采集组件本身的性能以及其所在容器的配置所决定。
例如我们使用Filebeat作为采集组件,可以依赖Filebeat投递机制中的At-Least-Once机制,其可以保证数据至少成功上报一次。同时通过在Agent容器中使用脚本来来运行Filebeat以及监听Filebeat的运行状态,可以使Filebeat异常中断之后及时重新启动。
对于上报超时的问题则在服务端需要对上报超时的数据进行检测,及时发现Filebeat上报的异常,比如由于容器配置低导致无法及时上报等。通过异常检测及时调整Agent容器的配置或者Filebeat组件的配置的方式来解决上报超时的问题。
数据采集是可观测平台最重要的环节之一,由于线上系统的复杂性和数据量的不确定性,例如在某些电商大促期间的流量洪峰时期,保证可观测数据采集的实时性和完整性,对于保障整个系统的稳定性具有重要的意义。

在云原生时代,可观测性覆盖了应用的全生命周期,是云原生应用必备的工具之一。
如果想要了解更多可观测系统的内容,欢迎阅读本文作者所著《云原生时代的可观测系统最佳实战》一书!
 限时五折优惠,快快抢购吧!
限时五折优惠,快快抢购吧!
福利时刻:先到先得!
本次将送出 5本 作为粉丝福利 ,不抽奖,社区积分直接兑换!
兑换地址:http://spring4all.com/4701.html
快来一起来参与社区内容的建设,一起学习一起成长吧!
点击阅读原文,查看更多社区福利!