
收藏 | 目标检测Anchor的What/Where/When/Why/How
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
也许你正在学习计算机视觉的路上,并且已经深入研究了图像分类和滑动窗口检测器。
在掌握了这些概念之后,了解最新技术(SOTA)目标检测,往往会变得令人望而生畏和晦涩难懂,尤其是在理解Anchor时。
毋庸讳言,深入大量流行的YOLO、SSD、R-CNN、Fast RCNN、Faster RCNN、Mask RCNN和RetinaNet,了解Anchor是一项艰巨的工作,尤其是在您对实际代码了解有限时。
如果我告诉你,你可以利用今天深入学习目标检测背后的Anchor呢?本文目标是帮助读者梳理Anchor的以下内容:
What:anchor是什么? Where:如何以及在何处对图像生成anchor以用于目标检测训练? When:何时可以生成anchor? Why:为什么要学习偏移而不是实际值? How:如何在训练过程中修正选定的anchor以实现训练对象检测模型?
1、What:anchor是什么?
anchor是指预定义的框集合,其宽度和高度与数据集中对象的宽度和高度相匹配。预置的anchor包含在数据集中存在的对象大小的组合,这自然包括数据中存在的不同长宽比和比例。通常在图像中的每一个位置预置4-10个anchor。
训练目标检测网络的典型任务包括:生成anchor,搜索潜在anchor,将生成的anchor与可能的ground truth配对,将其余anchor分配给背景类别,然后进行sampling和训练。
而推理过程就是对anchor的分类和回归,score大于阈值的anchor进一步做回归,小于阈值的作为背景舍弃,这样就得到了目标检测的结果。
2、Where:如何以及在何处对图像生成anchor,以用于目标检测训练
本质上,生成anchor是为了确定一组合适的框,这些框可以适合数据中的大多数对象,将假设的、均匀分布的框放置在图像上,并创建一个规则,将卷积特征映射的输出映射到图像中的每个位置。
为了理解锚定框是如何被生成的,假设有一个包含小目标的256px x* 256px图像,其中大多数目标尺度位于40px * 40px或80px * x 40px之间。下面从两个方面考量anchor:
a、aspect ratios(横纵比):因为假设的ground turth宽高比在1:1和2:1之间。因此,应至少考虑两个纵横比(1:1和2:1),用来生成此示例数据集的anchor。
b、scales (尺度):指对象的长度或宽度占其包含图像的总长度或宽度的比例。
例如,假设一个图像的宽度=256px=1个单位,那么一个40px宽的对象占据40px/256px=0.15625个单位的宽度,即这个对象占据整个图像宽度的15.62%。
为了选择一组最能代表数据的尺度,我们可以考虑具有最极端值的对象侧度量,即数据集中所有对象的所有宽度和高度之间的最小值和最大值。如果我们的示例数据集中最大和最小的比例是0.15625和0.3125,并且我们要为anchor选择三个比例,那么三个潜在的比例可能是0.15625、0.3125和0.234375(前面两个尺度的均值)。
如果使用上面提到的两个纵横比(1:1和2:1)和这三个比例(0.15625、0.234375和0.3125)来建议此示例数据集的锚定框,那么我们将总共有六个锚定框来建议输入图像中的任何一个位置。
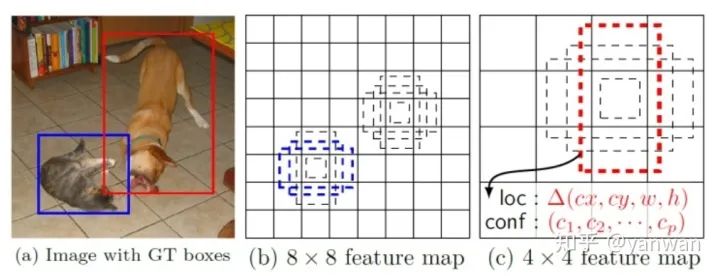
目标检测器采用这样的规则来生成anchor,假设检测器网络输入的特征图是4-channel 8*8,然后可以在每个单元格中心上生成6个不同aspect ratios和scales的anchor,那么总共384个,这样就尽可能的涵盖所有可能性。
3、When:什么时候在图像上生成anchor?
检测器不预测anchor,而是为每个anchor预测一组值:a、anchor坐标偏移(offset),b、每个类别的置信度得分。
这意味着在每次图像推理过程中都将始终使用相同的anchor,并且将使用网络预测的偏移(offset)来更正该anchor。
知道了这一点,就很容易理解ancor需要初始化,并将此数据结构存储在内存中,以供实际使用时,如:在训练中与ground ruth匹配,在推断时将预测的偏移量应用于anchor。在这些点上,anchor的实际生成其实都已经生成了。
4、Why:为什么要学习偏移而不是实际值?
理论上,如果CNN接收同一类型的物体两次,那么不管CNN在图像中的哪个位置接收到物体,CNN都应该输出大致相同的值两次。
这意味着,如果一幅图像包含两辆车,而输出结果是绝对坐标,那么网络将预测两辆车大致相同的坐标。
而学习anchor偏移,允许这两辆车具有相似偏移输出,但偏移应用于锚定,锚定可映射到输入图像中的不同位置。这是在anchor回归过程中学习锚定盒偏移的主要原因。
5、How:如何在训练过程中修正选定的anchor以实现训练对象检测模型?
(1)回归任务:训练过程中,网络回归任务学习的target并不是feature map上每个位置的所有anchor的offset,而是与ground truth匹配的anchor的实际偏移,背景框的anchor偏移保持为零。
这意味着,一旦anchor内的像素空间被完全视为背景,则anchor不需要调整坐标。换言之,由于分配给背景类别的anchor根本不应该移动或更正,因此没有要预测的偏移量。
(2)分类任务:分类损失通常是使用在总背景框的子集来处理类不平衡。还记得在我们的示例中,每个位置有6个框,总共有384个建议吗?好吧,大多数都是背景框,这就造成了一个严重的阶级不平衡。

解决这类不平衡问题的一个流行的解决方案是所谓的 hard negative mining ——根据预先确定的比率(通常为1:3;foreground:background)选择一些高权重背景框。在分类损失中处理类不平衡的另一个流行方法是降低易分类实例的权重损失贡献,这就是RetinaNet的focal loss情况。
(3)推理过程:为了获得最终的一组目标检测,网络的预测偏移量被应用到相应的anchor中,可能会有成百上千个候选框,但最终,测器会忽略所有被预测为背景的盒子,保留通过某些标准的前景检测结果,并应用NMS纠正同一对象的重叠预测。
如本文开头所述,了解SOTA的目标检测算法,通常会变得令人望而生畏和晦涩难懂,但一旦您了解anchor的作用,目标检测就有了全新的理解。
本文翻译自以下blog,并做了一些修改。
Anchor Boxes in Object Detection: When, Where and How to Propose Them for Deep Learning Apps,
本文仅做学术分享,如有侵权,请联系删文。