
为什么阿里巴巴修正了HashMap关于1024个元素扩容的次数?(典藏版)
 来源|juejin.cn/post/7302724955699789863
来源|juejin.cn/post/7302724955699789863
引言
最近在翻看《阿里巴巴开发手册-嵩山版》时,发现其修正了关于HashMap关于1024个元素扩容的次数 在先前的版本泰山版我们可以看到以下描述:

而嵩山版则可以看到:

同时我们也可在嵩山版的版本历史中看到对以上变化的描述:

并且我在官网文档中也同样发现了采访视频对这一变化,主持人对孤尽老师提出了以下疑问:
主持人:
有同学问,嵩山版修正了HashMap关于1024个元素扩容的次数?那么这个泰山版中是七次扩容,我感觉是正确的,为什么现在进行了修改?
孤尽老师:
“
大家可以看到嵩山版描述都改了,就没有讲「扩容」,讲叫「resize」的次数。因为resize的这个次数的话,我们在调resize的时候,就put,如果你new了一个HashMap它并不会给你分配空间,第一次put的时候,它才会给你分配空间。所以就是说我们在第一次put的时候,也会调resize。但是很多同学就会争议,说这个算不算扩容?那其实就是说我们在这个点上,其实为了,因为计算机我们大家都是搞计算机的,都希望用没有「二义性」的语言来表示。所以在嵩山版本里面进行了修改,然后我们改成了resize的方式来说明这到底是它的容量是如何变化的。因为扩容这个词的话,大家的理解是不一样的。这也是我们有一次大概在业界我们有一个打卡就是一个打卡测试题,这个题里面我们有一个选项。当时选的同学是两种答案,但是这两种答案都是有自己的道理。所以我们也是借鉴了这个看法,然后在这个嵩山版里面也写的更加明确了。就是叫resize的次数,不叫扩容的次数。
以下是文档下载链接和采访视频地址。
https://developer.aliyun.com/topic/java20
我们可以从孤尽老师的回答中提炼出主要发生的变化是:
扩容次数修改为resize次数。主要的问题是每个人对「扩容」这个定义存在分歧。
扩容的主要分歧是在:没有给HashMap进行初始化的时候,第一次put的时候才会分配空间,也会调用resize。那这操作个算不算扩容?即初始化容量这个操作算不算扩容?
所以扩容次数修改为resize次数。

那么我们先来看一下第一次put的时候调用resize这个操作是什么?
第一次put调用resize()
前面孤尽老师的回答中也强调了这个put()方法调用resize()方法是存在一个条件的:
“
如果你new了一个HashMap它并不会给你分配空间。同时文档中也写了由于没有设置容量初始大小。
“
除了这个条件其实还有一个额外的条件,就是这是在JDK1.8之后HashMap才会有的操作。
要理解这句话我们首先要看下HashMap的源码,看下它的构造器方法。
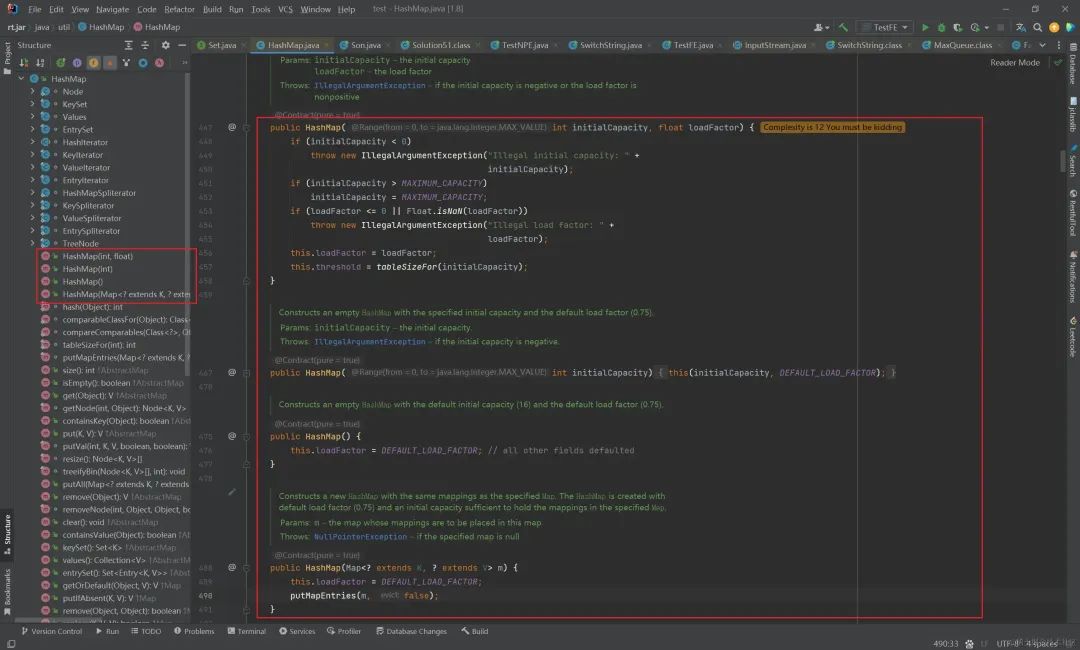
存在四个构造方法
//参数:初始容量,负载因子
public HashMap(int initialCapacity, float loadFactor) { }
//参数:初始容量。调用上一个构造函数,默认的负载因子(0.75)
public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); }
//参数:无参构造器。创建的HashMap具有默认的负载因子(0.75)
public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted }
//参数:使用与指定Map相同的映射构造一个新的HashMap。创建的HashMap具有默认的负载因子(0.75)和足够在指定Map中保存映射的初始容量。
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
也就是说当我们使用一个无参构造器创建HashMap的时候
Map<String,String> map = new HashMap<>();
调用的就是上述构造方法的第三个方法,只会设置默认的负载因子为0.75。就没有其他操作了。。
而当我们对这个HashMap进行put()操作的时候
Map<String,String> map = new HashMap<>();
map.put("first","firstValue");
我们看一下源码,进行了什么操作?
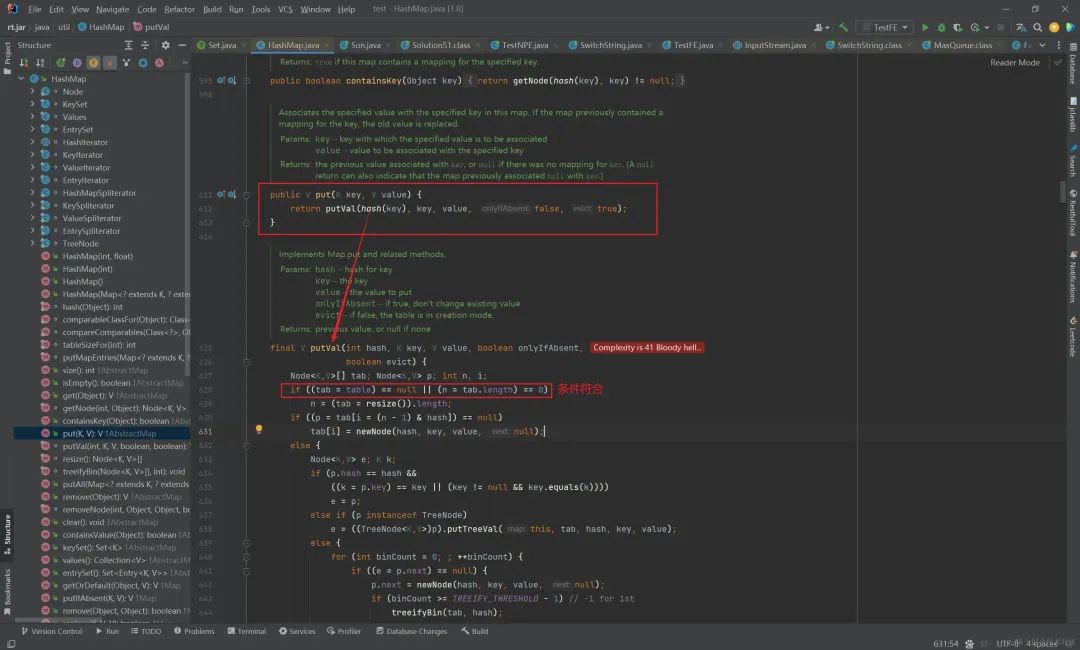
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
其实调用的是内部的putVal()方法。同时我们也可看见我们前面的构造器方法中除了设置了负载因子,就没有其他操作了,所以是符合if ((tab = table) == null || (n = tab.length) == 0),大家也可debug断点打在这进行验证。所以就会执行下面的代码n = (tab = resize()).length;调用了一次resize(),同时对n进行了赋值操作。
那么我们通过源码的确发现了,在JDK1.8中由于没有设置HashMap容量初始大小,在第一次进行put()操作的时候,HashMap会调用一次resize()方法初始化容量为16。(resize的源码也不是本篇文章的重点,所以我这边会直接提供结论,并且再次强调一下JDK1.7是会初始化容量为16的,而不是在是第一次进行put()操作时初始化容量。
调用resize()的次数
在嵩山版中修订了HashMap关于1024个元素扩容的次数修改为:resize()方法总共会调用 8 次。
那么我们来看一下到底是哪8次?
再次重申一下本篇文章主要是讲嵩山版对这个扩容次数的修改,涉及相关的源码已在Java不得不知道的八股文之哈希表 中写过,为了避免重复啰嗦,有水文之嫌,所以本文不会再次分析会直接给出对应的结论为已知条件进行分析。如想知道更多细节和版本差异,请移步之前的文章:
“
https://juejin.cn/post/7168631540518223903
以下是我们可以从源码中得出的结论:
HashMap没有初始化容量时默认负载因子为0.75,在第一次put()时会调用resize()进行初始化,容量为16。(JDK1.8)
HashMap中的阈值threshold为
capacity * load factor就容量*负载因子。例如容量为16,那么阈值threshold就为16*0.75=12。
当HashMap进行put()的时候,元素个数大于等于当前阈值的时候
size>=threshold,会进行resize()操作。容量和阈值都会乘以2。例如初始容量为16,那么当我们put第12个元素的时候,就会进行resize()操作。
基于以上已知的结论,那么我们就能很容易的知道,在JDK1.8中没有给HashMap初始化容量时,存储1024个元素调用resize()的次数和时机了。(默认阈值为0.75)
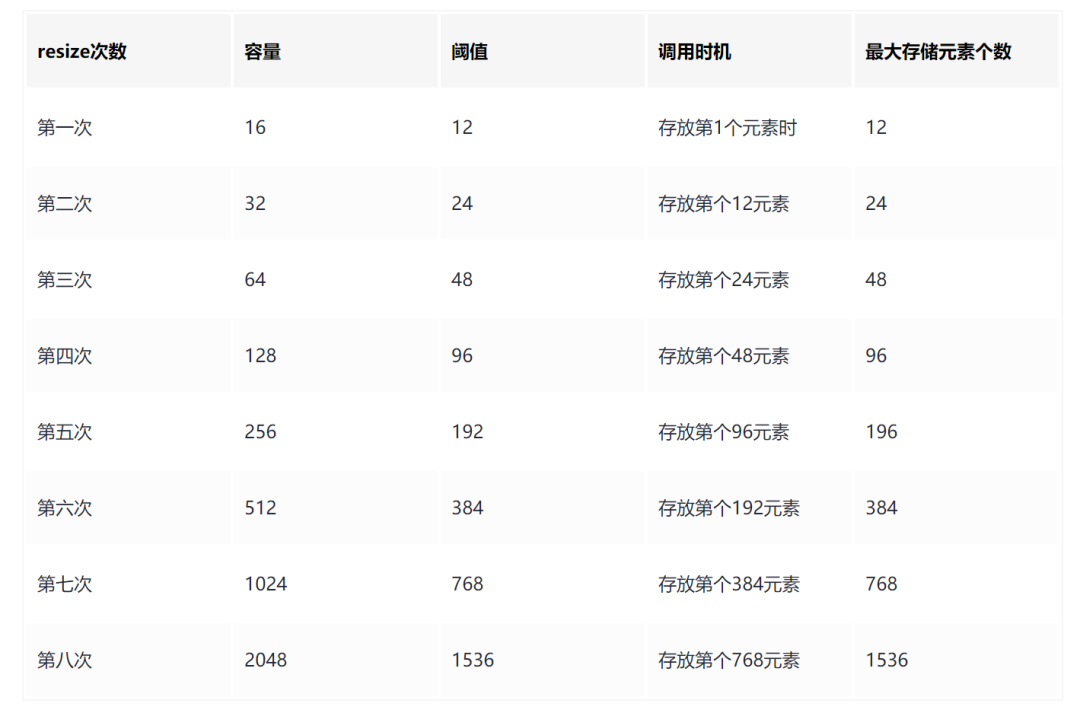
所以在第7次进行resize()后,HashMap的capacity为1024了,但是当我们存放第768个元素时,size>=threshold就会进行第8次扩容,此时才能真正的存放下1024个元素。
所以在JDK1.8中没有给HashMap初始化容量时,存储1024个元素,会调用resize()8次。
“
其实resize()操作也是十分消耗性能的,我们存储1024个元素的时候没有设置初始值就会调用8次。如果我们给其设置了2048容量,那么我们可以避免了。所以阿里巴巴同时建议我们给HashMap初始化时给定容量。
总结
此番修正主要是每个人对「扩容」定义存在了分歧,在JDK1.8中如果没有给HashMap设置初始容量,那么在第一次put()操作的时候会进行resize()。而有的人认为这算一次扩容,有的人认为这不是一次扩容,这只是HashMap容量的初始化。
所以存储1024的元素时:
前者的人认为扩容次数为8次。
后者的人认为扩容次数为7次。
孤尽老师说对此分歧,希望用没有「二义性」的语言来表示,所以「扩容次数」修正为「resize次数」。
程序汪资料链接
欢迎添加程序汪微信 itwang007 进粉丝群