
为什么HashMap的长度始终是2的N次方?
文章目录:
①、抛出问题
②、给出结论
③、论证问题
④、& 和 % 运算效率对比
相信对 JDK 源码感兴趣的小伙伴,HashMap 的源码你一定不会错过,里面有很多精妙的设计,也是面试的常用考点,本文我会点出一些。
但是本文我不详细介绍 HashMap 源码,想了解的可以看我之前的文章,本篇文章主要是给大家解惑这样几个问题。
1、抛出问题
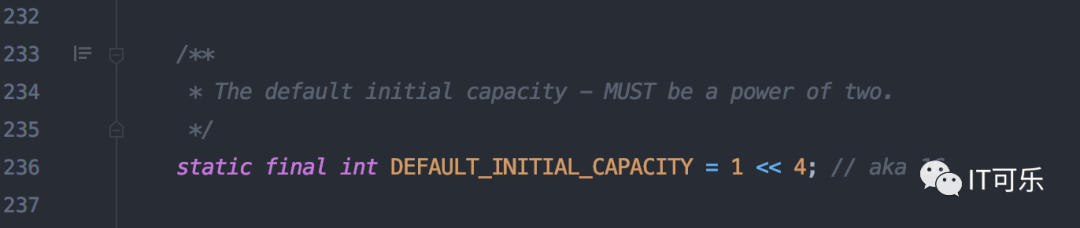
1.1 为什么 HashMap 的默认初始容量长度要是 1<<4 ?
为啥源码这里不直接写 16 ?要写成 1<<4?知道的可以在评论区留言。
1.2 为什么 HashMap 初始化即使给定长度,依然要重新计算一个 2 的数?
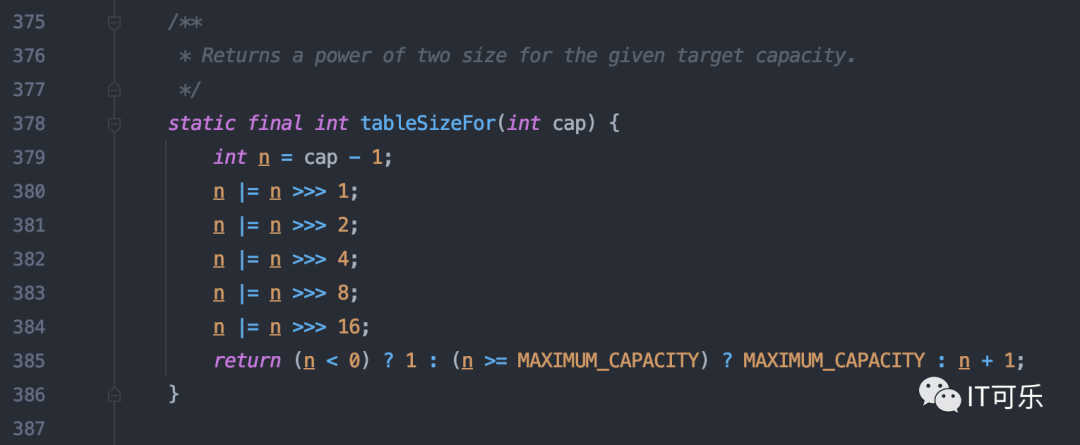
PS: 这个方法是 HashMap 用于计算初始化容量,结果是返回大于给定值的第一个2,比如 :
new HashMap(10),其实际长度是 16;
new HashMap(18),实际长度是32;
new HashMap(40),实际长度64。
涉及到两个运算符:
①、| : 或运算符。
②、>>> : 无符号右移运算符,移动时忽略符号位,空位以 0 补齐。
这个算法也比较有意思,原理就是每一次运算都是将现有的 0 的位转换成 1,直到所有的位都为 1 为止;最后返回结果的时候,如果比最大值小,则返回结果+1,正好将所有的 1 转换成 0,且进了一位,刚好是 2 。
1.3 为什么 HashMap 每次扩容是扩大一倍,也就是 2 ?
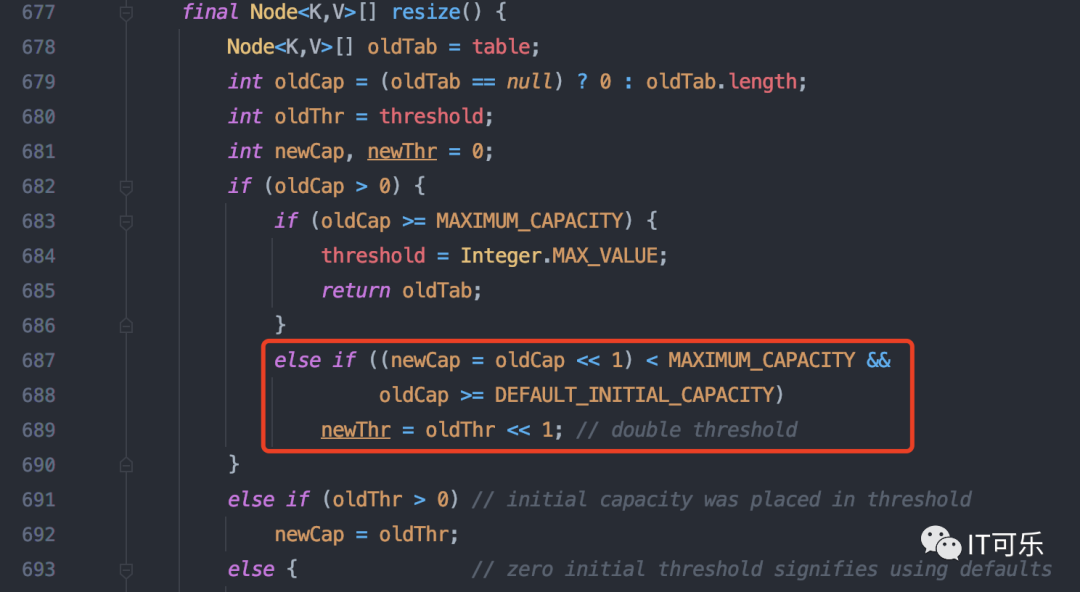
当存入HashMap的元素占比超过整个容量的75%(默认加载因子 DEFAULT_LOAD_FACTOR = 0.75)时,进行扩容,而且在不超过int类型的范围时,左移1位(长度扩为原来2倍)
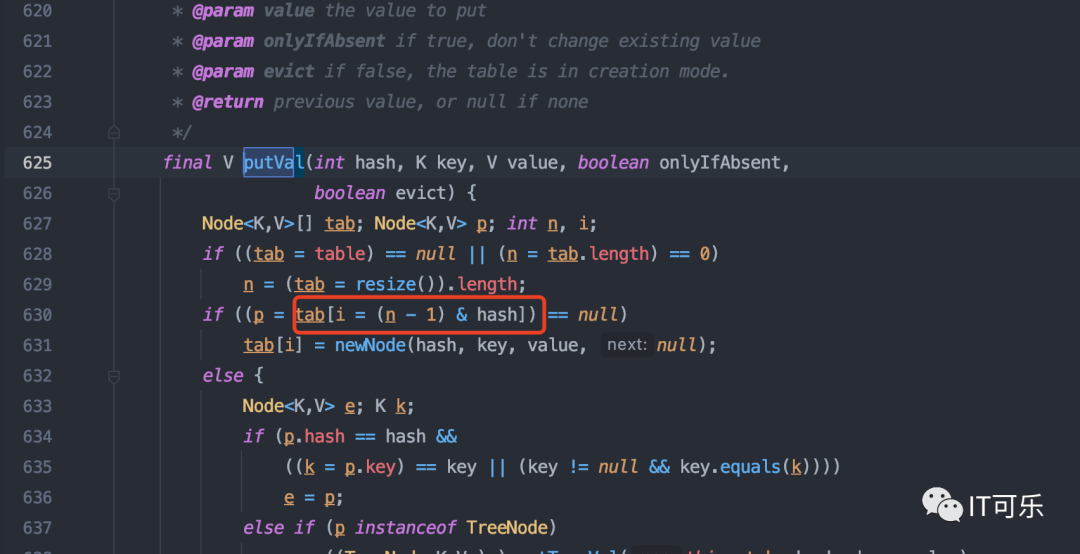
1.4 为什么 HashMap 的计算索引算法是 &,而不是 % ?
新添加一个元素时,会计算这个元素在 HashMap 中的位置,算法分为两步:
①、得到 hash 值
PS:其实这里的算法可以研究下,hashcode() 是一个 native 修饰的方法,返回一个 int 类型的值(根据内存地址换算出来的一个值),然后将这个值无符号右移16位,高位补0,并与前面第一步获得的hash码进行按位异或^ 运算。
这样做有什么用呢?这其实是一个扰动函数,为了降低哈希码的冲突。右位移16位,正好是32bit的一半,高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。
这样混合后的低位掺杂了高位的部分特征,高位的信息也被变相保留下来。
也就是保证考虑到高低Bit位都参与到Hash的计算中。

②、索引值 i = (n-1) & hash
这里的 n 是 HashMap 的长度,hash 是上一步得到的值。
注意:这里是用的按位与 & ,而不是用的取模 %。
1.5 问题总结
大家发现没,通过我上面提出的四个问题,前三个问题 HashMap 的长度始终保持在 2 。
①、默认初始长度是 2;
②、即使给定初始长度,其值依旧是大于给定值的第一个偶数;
③、每次扩容都是扩大一倍,2
然后第四个问题,计算 HashMap 的元素索引时,我们得到了一个 hash 值,居然是对 HashMap 的长度做 & 运算,而不是做 % 运算,这到底是是为什么呢?
2、给出结论
我们先直接给出结论:

当 lenth = 2 且X>0 时,X % length = X & (length - 1)
也就是说,长度为2的n次幂时,模运算 % 可以变换为按位与 & 运算。
比如:9 % 4 = 1,9的二进制是 1001 ,4-1 = 3,3的二进制是 0011。9 & 3 = 1001 & 0011 = 0001 = 1
再比如:12 % 8 = 4,12的二进制是 1100,8-1 = 7,7的二进制是 0111。12 & 7 = 1100 & 0111 = 0100 = 4
上面两个例子4和8都是2的n次幂,结论是成立的,那么当长度不为2的n次幂呢?
比如:9 % 5 = 4,9的二进制是 1001,5-1 = 4,4的二进制是0100。9 & 4 = 1001 & 0100 = 0000 = 0。显然是不成立的。
为什么是这样?下面我们来详细分析。
3、论证结论
首先我们要知道如下规则:
①、"<<" 左移:按二进制形式把所有的数字向左移动对应的位数,高位移出(舍弃),低位的空位补零。左移一位其值相当于乘2。
②、">>"右移:按二进制形式把所有的数字向右移动对应的位数。对于左边移出的空位,如果是正数则空位补0,若为负数,可能补0或补1,这取决于所用的计算机系统。右移一位其值相当于除以2。
③、">>>"无符号右移:右边的位被挤掉,对于左边移出的空位一概补上0。
根据二进制数的特点,相信大家很好理解。
现在对于给定一个任意的十进制数XXX....XX,我们将其用二进制的表示方法分解:
公式1:
XXX....XX = X*2+X*2+......+X*2+X*2
回到上面的结论:当 lenth = 2 且X>0 时,X % length = X & (length - 1)
以及对于除法,除以一个数能用除法分配律,除以几个数的和或差不能用除法分配律:
公式2:
成立:(a+b)÷c=a÷c+b÷c
不成立:a÷(b+c)≠a÷c+a÷c
通过 公式1以及 公式2,我们可以得出当任意一个十进制除以一个**2**的数时,我们可以将这个十进制转换成公式1的表示形式:
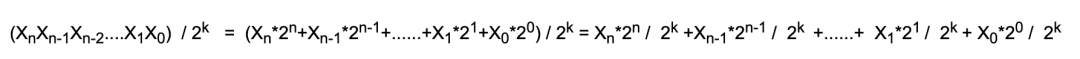
如果我们想求上面公式的余数,相信大家一眼就能看出来:
①、当 0<= k <= n 时,余数为 X2+X2+......+X2+X2 ,也就是说 比 k 大的 n次幂,我们都舍掉了(大的都能整除 2),比k小的我们都留下来了(小的不能整除2)。那么留来下来即为余数。
②、当 k > n 时,余数即为整个十进制数。
看到这里,我们离证明结论已经很近了。
再回到上面说的二进制的移位操作,向右移 n 位,表示除以 2
一个十进制数对一个2 的数取余,我们可以将这个十进制转换为二进制数,将这个二进制数右移n位,移掉的这 n 位数即是余数。
知道怎么算余数了,那么我们怎么去获取这移掉的 n 为数呢?
我们再看2,2,2....2 用二进制表示如下:
0001,0010,0100,1000,10000......
我们把上面的数字减一:
0000,0001,0011,0111,01111......
根据与运算符&的规律,当位上都是 1 时,结果才是 1,否则为 0。所以任意一个二进制数对 2 取余时,我们可以将这个二进制数与(2-1)进行按位与运算,保留的即是余数。
这就完美的证明了前面给出的结论:
当 lenth = 2 且X>0 时,X % length = X & (length - 1)

4、& 和 % 运算效率
为什么要将 % 运算改为 & 运算,很显然是因为 & 运算在计算机底层只需要一个简单的 与逻辑门就可以实现,但是实现除法确实一个很复杂的电路,大家感兴趣的可以下去研究下。
我这里在代码层面,给大家做个测试,直观的比较下速度:
public class HashMapTest {
public static void main(String[] args) {
long num = 100000*100000;
long startTimeMillis1 = System.currentTimeMillis();
long result = 1;
for (long i = 1; i < num; i++) {
result %= i;
}
long endTimeMillis1 = System.currentTimeMillis();
System.out.println("%: "+ (endTimeMillis1 - startTimeMillis1));
long startTimeMillis2 = System.currentTimeMillis();
result = 1;
for (long i = 1; i < num; i++) {
result &= i;
}
long endTimeMillis2 = System.currentTimeMillis();
System.out.println("&: "+ (endTimeMillis2 - startTimeMillis2));
}
}
打印结果如下:
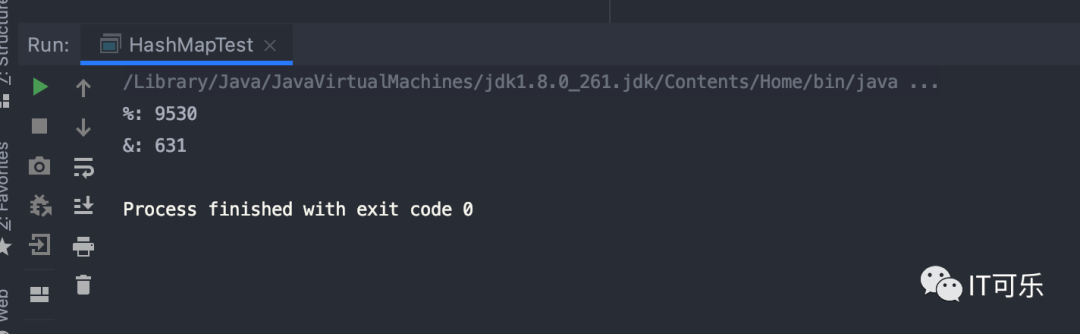
差距还是很明显的,而且这个结果还会随着测试次数的增多而越拉越开。
关于我
Java程序猿,公众号「IT可乐」定期分享有趣有料的精品原创文章!