
可微硬件:AI将如何重振摩尔定律的良性循环

来源:人工智能AI技术 本文约6000字,建议阅读9分钟
本文阐述了当今AI硬件渊源,跳脱过去芯片设计窠臼,以可微分GPU及可微分ISP为例,提倡以AI为本的可微分硬件理念。

据报道,正值全球芯片短缺之际,台积电提高了芯片价格并推迟了3nm制程的生产进程。无论这类新闻是否准确或预示着一种长期趋势,这都在提醒我们,摩尔定律的衰退将带来越来越严重的影响,并迫使我们重新思考人工智能硬件——它会受到这种衰退的影响,还是会帮助扭转这种趋势?
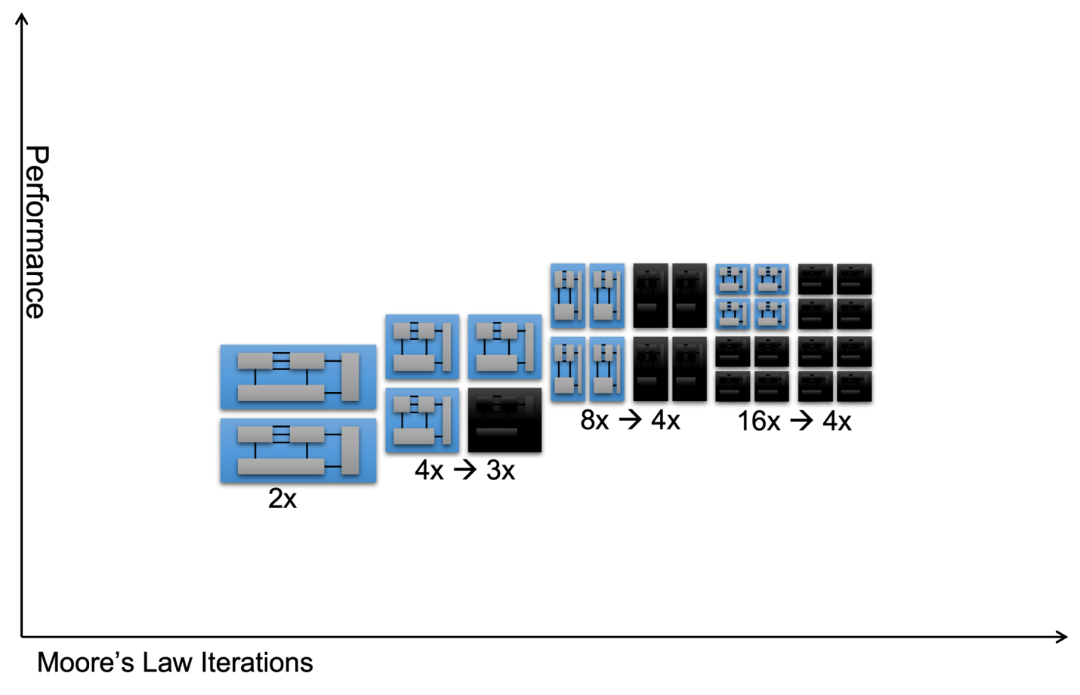
如果我们希望恢复摩尔定律的良性循环,这其中,软件和硬件曾经相互加持,使一部现代智能手机比过去10年占据整个仓库的超级计算机功能更强大。人们普遍接受后摩尔时代的良性循环是基于更大的数据迸发更大的模型并需要更强大的机器。但事实上,这样的循环是不可持续的。
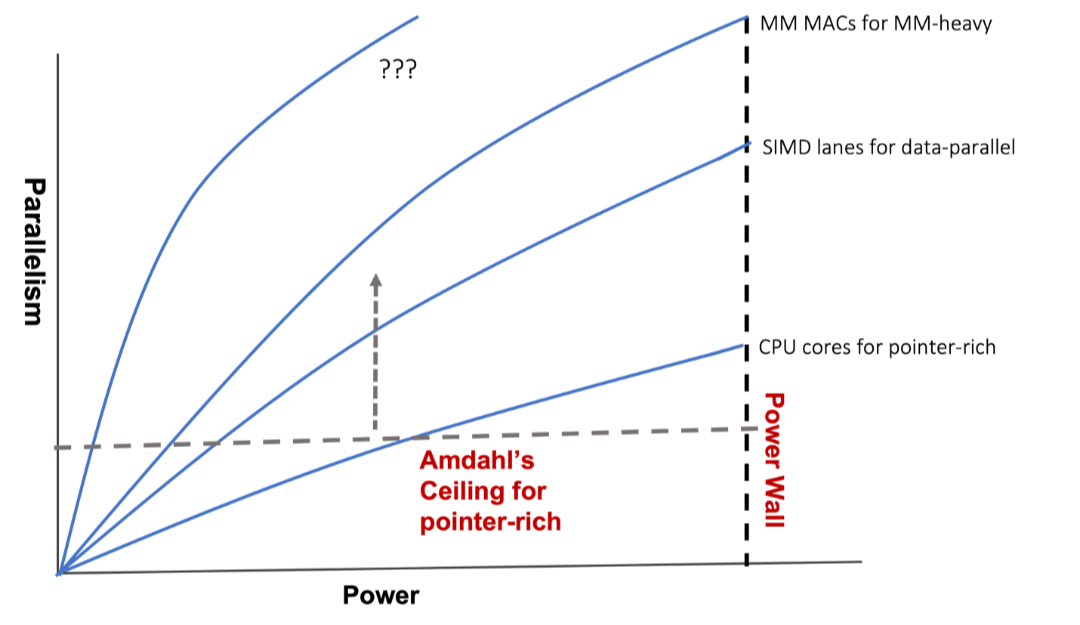
除非我们重新定义并行性,我们不能再指望缩小晶体管来制造越来越宽的并行处理器。我们也不能依赖于它,除非特定领域架构(DSA)有助于促进及适应软件的发展。
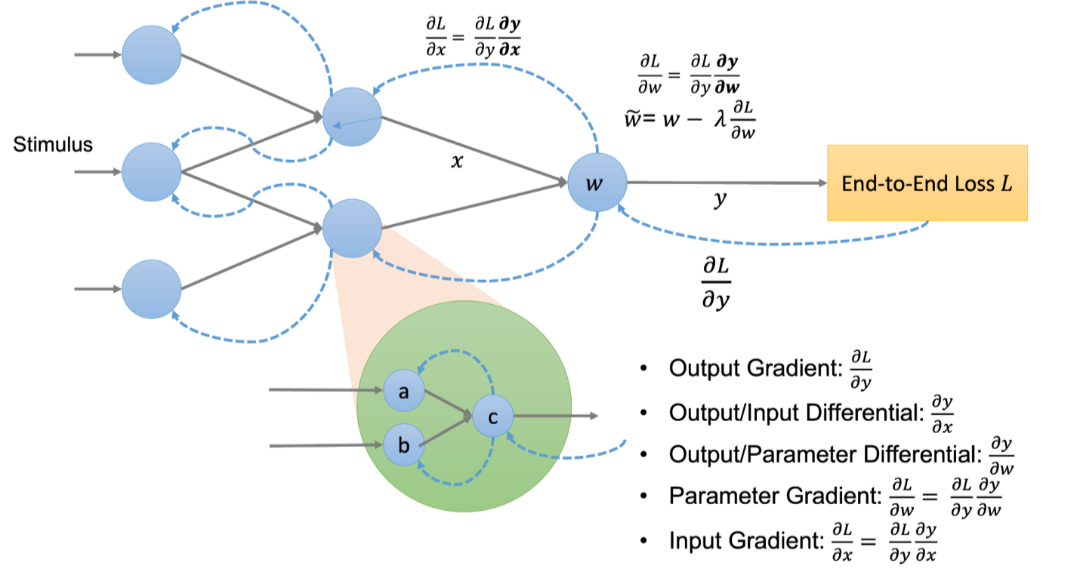
与其搞清楚哪类硬件是用于 AI 这个不断发展的移动目标,我们不如从AI以可微分编程为核心的角度来看待AI 硬件。这样说,人工智能软件程序是一个计算图,由一组通过训练来实现端到端目标的计算节点组成。只要一个深度流水线起来的DSA硬件是可微的,它就可以作为一个计算节点。软件程序员可以自由地将可微硬件插入计算图中,以实现高性能和以创意解决问题,就像预构建的可定制软件组件一样。AI 硬件不应再有"血统纯正度"审查,毕竟它现在可以包括各样可微硬件。
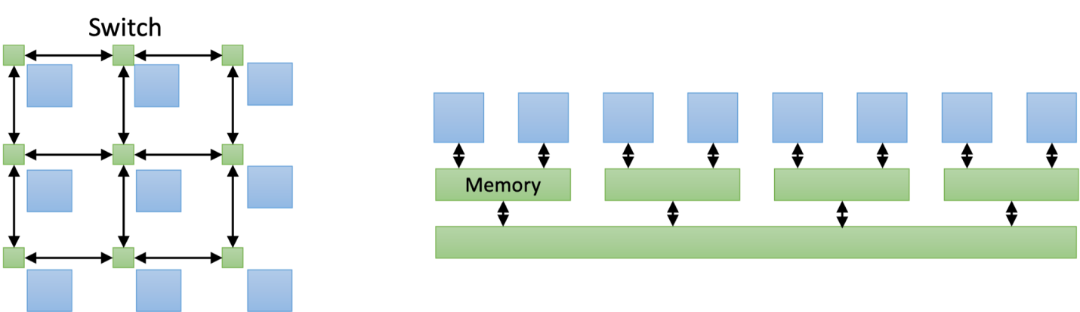

分布式优先机将矢量优先机从HPC市场踢出局 Many-Core是分布式优先“集于一芯” GPU是将高性能计算的矢量优先“集于一芯”
AI和HPC因为使用大量MM而命运交汇 Many-Core 和 Many-MAC基本上不比GPU更适配AI
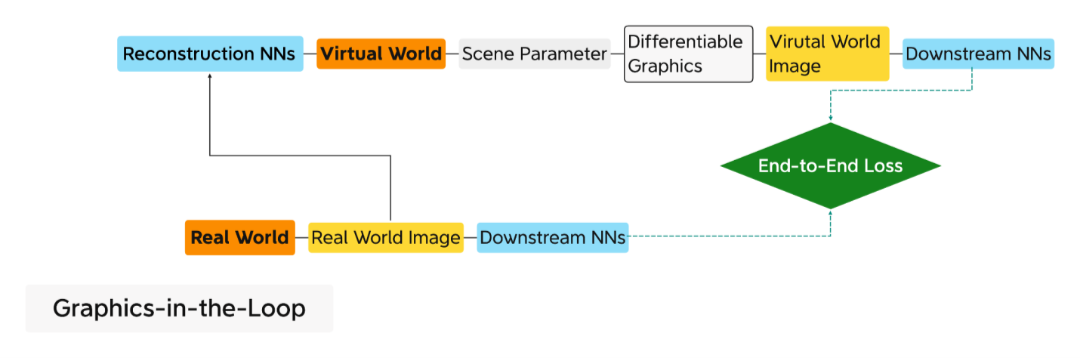
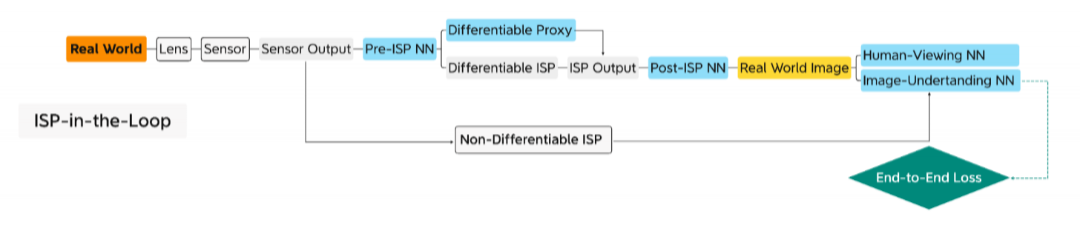
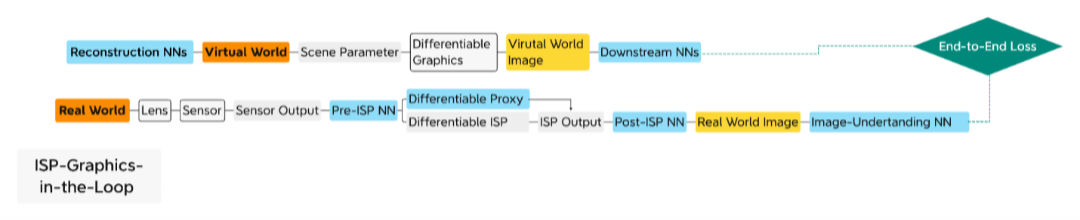
环路中的不可微ISP硬件,用于非ML优化的参数自动调整。 经过训练的 NN 模型模仿 ISP的可微代理, 用 于基于ML 的参数自动调整。

编辑:王菁
评论