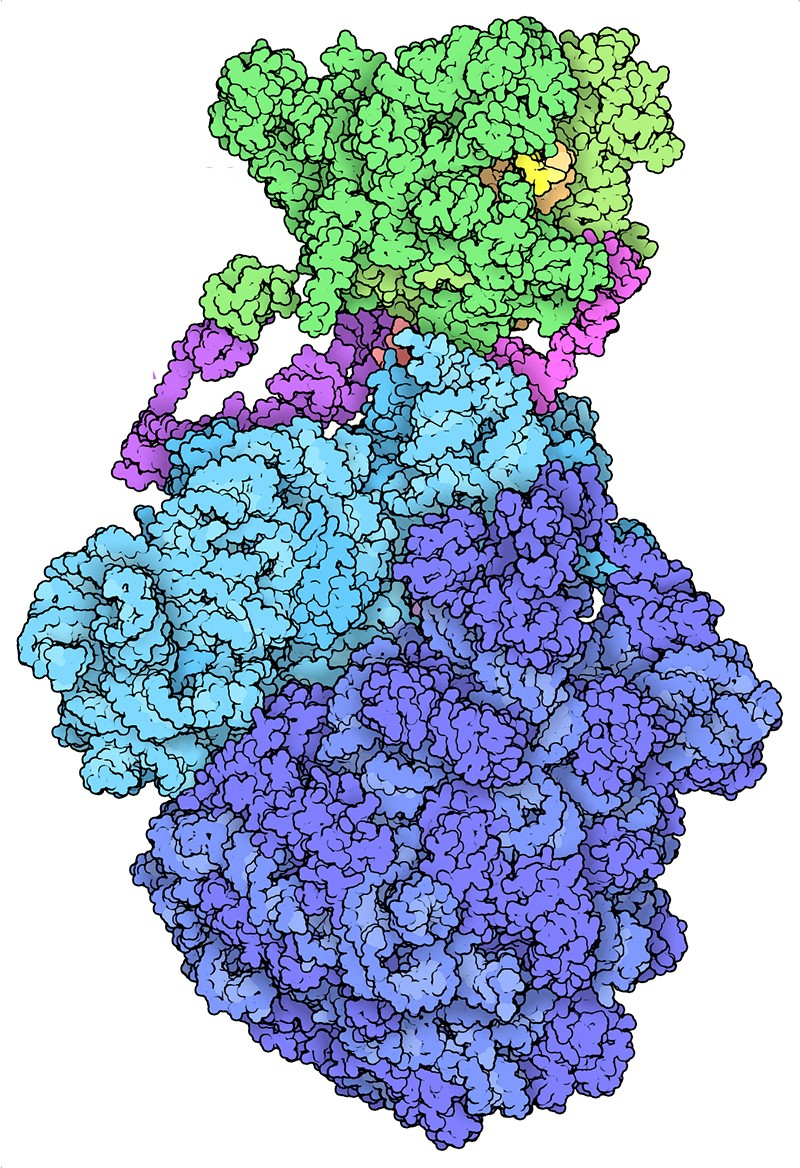
数据库在科学研究中非常重要,以至于人们很容易忽视它是由软件驱动的这一事实。在过去的几十年里,数据库资源的规模急剧膨胀,影响了许多领域,尤其生物学领域更加剧烈。今天庞大的基因组和蛋白质数据库源于玛格丽特·戴霍夫(Margaret Dayhoff)的工作,她是马里兰州银泉市国家生物医学研究基金会(National Biomedical Research Foundation)的生物信息学先驱。20世纪60年代初,当生物学家们致力于梳理蛋白质的氨基酸序列时,戴霍夫开始寻找不同物种之间进化关系的线索。这项工作首次于1965年与三位共同作者发表,描述了当时已知的65种蛋白质的序列、结构和相似性。历史学家布鲁诺·斯特拉瑟(Bruno Strasser)在2010年写道,这是第一个“与特定研究问题无关”的数据集。将数据编码在穿孔卡片中,这使得扩大数据库和搜索成为可能。其他计算机化的生物数据库紧随其后发布。加州大学圣地亚哥分校的进化生物学家Russell Doolittle在1981年创建了另一个名为Newat的蛋白质数据库。1982年数据库GenBank的发布,是美国国立卫生研究院(National Institutes of Health)维护的DNA档案。这些数据库资源的价值在1983年7月得到了证实。当时,由伦敦帝国癌症研究基金会蛋白质生物化学家迈克尔·沃特菲尔德领导的团队,与杜利特尔的团队各自独立报道了一个特殊的人类生长因子序列与一种导致猴子出现癌症的病毒蛋白质之间的相似性。观察结果显示了一种病毒诱发肿瘤机制——通过模仿一种生长因子,病毒会诱导细胞不受控制地生长。美国国家生物技术信息中心(NCBI)前主任詹姆斯·奥斯特尔说:“这一结果让一些对计算机和统计学不感兴趣的生物学家头脑里灵光一闪:我们可以通过比较序列来了解有关癌症的一些情况。”这一发现标志着“客观生物学的到来”。除了设计实验来测试特定的假设,研究人员还可以挖掘公共数据集,寻找那些实际收集数据的人可能从未想到过的联系。当不同的数据集连接在一起时,其威力就会得到急剧加强。
科学计算通常涉及到使用向量和矩阵的相对简单的数学运算,但这样的向量和矩阵实在太多了。但在20世纪70年代,并没有一套普遍认可的计算工具来执行这些操作。因此,从事科学工作的程序员并未专注于科学问题,而是把大量的时间花在了设计代码进行基本的数学运算上。编程世界需要的是一个标准。1979年,它有了一个:基本线性代数子程序,简称BLAS6。这个标准一直发展到1990年,定义了几十个向量和后来的矩阵数学的基本程序。美国田纳西大学计算机科学家、BLAS开发团队成员杰克·唐加拉表示,事实上,BLAS把矩阵和向量数学简化成了和加法和减法一样基本的计算单元。美国德克萨斯大学奥斯汀分校的计算机科学家Robert van de Geijn指出,BLAS“可能是为科学计算定义的最重要的接口”。除了为常用函数提供标准化的名称之外,研究人员可以确定基于BLAS 的代码在任何计算机上都可以以相同的方式工作。该标准还使计算机制造商能够优化BLAS实现,以实现在其硬件上的快速操作。40多年来,BLAS代表了科学计算堆栈的核心,也就是使科学软件运转的代码。华盛顿大学的机械和航空航天工程师Lorena Barba称其为“五层代码中的机械”。而杰克·唐加拉说:“它为我们进行计算提供了基础。”
6 显微镜必备:NIH图像(1987)
上世纪80年代初,程序员韦恩·拉斯班德(Wayne Rasband)在马里兰州贝塞斯达的美国国立卫生研究院(National Institutes of Health)的一个脑成像实验室工作。该团队有一台扫描仪来数字化x光片,但无法在电脑上显示或分析它们。所以Rasband写了一个程序来完成这项任务。该程序是专门为一台价值15万美元的PDP-11小型计算机设计的。随后,在1987年,苹果公司发布了麦金塔II,这是一个更友好、更实惠的选择。拉斯班德说:“在我看来,这显然是一种更好的实验室图像分析系统。”他将自己的软件移植到新平台上,并建立了一个图像分析生态系统。国家卫生研究院的图像和它的后代授权研究人员在任何计算机上查看和量化任何图像。软件家族包括ImageJ,这是为Windows和Linux用户编写的基于java的版本,以及由Pavel Tomancak在德国德累斯顿的马克斯普朗克分子细胞生物学和遗传学研究所的团队开发的ImageJ的一个发行版,它包含了关键的插件。麻省剑桥Broad研究所成像平台的计算生物学家评价到:“ImageJ是最基础的工具,几乎没有生物学家没有使用过它。”Eliceiri说:“这个程序的目的不是成为一切,而是服务于用户。不像Photoshop和其他程序,ImageJ可以是任何你想要的。