Nature盘点:从Fortran、arXiv到AlexNet,这些代码改变了科学界

来源:机器之心 本文约3800字,建议阅读10分钟
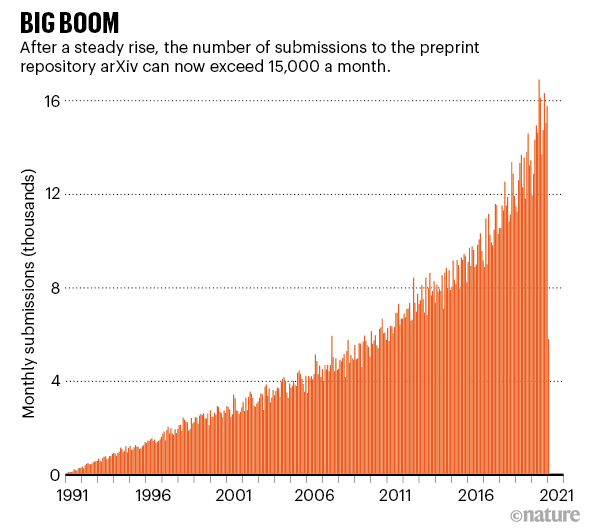
从 Fortran 编译器到 arXiv 预印本库、AlexNet,这些计算机代码和平台改变了科学界。



默奇森天文望远镜,使用快速傅里叶变换来收集数据

评论
 下载APP
下载APP来源:机器之心 本文约3800字,建议阅读10分钟
从 Fortran 编译器到 arXiv 预印本库、AlexNet,这些计算机代码和平台改变了科学界。
默奇森天文望远镜,使用快速傅里叶变换来收集数据