
数据分析案例:网易云音乐用户微观洞察&精细化运营
面对云音乐1.8亿的用户体量,用户精细化运营是当下重点投入的业务领域。精细化运营的前提是对用户的听歌动机和喜好进行挖掘,本篇文章focus用户的微观音乐消费行为洞察,通过用户关键行为的数据分析,提炼出用户的偏好,最终应用在用户的促活召回、版权回归和新客留存等多个业务场景,提升了各业务精细化运营的能力。
背景介绍
“2021年云音乐月活用户数1.826亿”,网易云音乐拥有如此大体量的月活用户,但整个行业新用户增长见顶,拉新成本越来越高,因此新用户的承接、老用户促活和流失用户召回,用户精细化运营是当下重点投入的业务领域。本次分享对用户如何分层不做探讨,聚焦在老客中的低活用户促活和流失用户召回的数据化运营上面。
谈到用户精细化运营,可谓老生常谈的问题,比如电商、短视频都有非常多的方法论和实践沉淀;对电商行业,对用户分层之后,对不同分层的用户通过大促营销、日常发券,用合作的超低价商品等运营策略,都是有效的用户精细化运营策略;对短视频ugc内容平台,因其内容更新频率高,基于关注、浏览等多种方式做促活和召回也是行之有效的运营策略......
回到音乐平台,音乐平台既没有“优惠券”可以发放,内容的创作成本也较高,那么音乐平台如何做用户促活和召回呢?大部分用户的核心诉求是听歌和互动,歌曲的生命周期较其他类型内容会更长,比如有很大一部分用户仍喜欢听80、90年代的老歌,有些用户对最近的热门或流行歌曲比较感兴趣,有些用户只听一些音乐人的歌曲,因此丰富的曲库是音乐平台做用户促活和召回的最重要手段。
那么精细化运营的前提是对用户的听歌动机和喜好进行挖掘,本篇文章focus用户的微观音乐消费行为洞察,用户如何分层不做过多讨论,后续有专门的文章进行介绍。
用户微观音乐偏好洞察
基于上述背景,如何更加精准的识别用户的听歌动机和听歌偏好,在不同的运营场上,给用户提供更匹配的歌曲,是各大音乐平台的重点关注问题。用户平台中消费的内容多种多样,包括音乐、播客、动态、视频、直播等。其中,99%的月活用户都在听歌。因此,深入分析研究用户在音乐场景下的行为尤其重要。
2.1 先看两个典型用户
在开展分析之前,我们先来看一些典型的音乐用户,通过用户的关键行为的数据分析,我们可以清晰构建出用户个人profile。
用户1:音乐发烧友
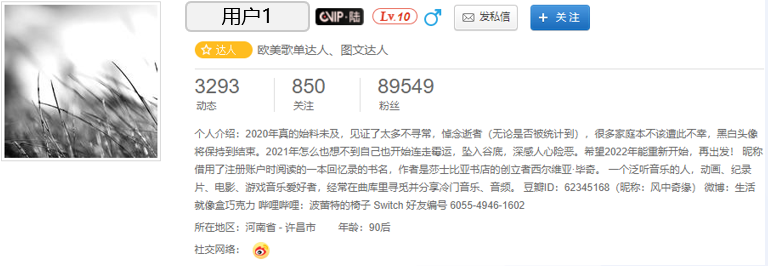
用户1是云音乐平台中的一个活跃用户,从官网的用户页面可以得知,该用户是一个欧美歌单达人和图文达人,来自河南的90后小哥哥。从个人简介中可以了解到这位用户的经历和爱好,用户也附上了自己的其他媒体社交账号。
听歌时长、次数和天数是刻画用户听歌多少的重要指标,两个听歌时长一样的用户,在听歌行为上差异可以很大,即单一维度的指标无法立体还原用户的真实听歌诉求;为了能够更好地对用户洞察,我们首次提出了音乐消费领域的“多广深”模型,目前该模型涉及的相关专利已经提交到国家专利局评审。
(1)多度刻画的是用户听歌的时间的投入程度,我们选取了用户的听歌时长、天数和有效播放次数,这三个核心指标数值越大,多度分数越高;
(2)广度刻画的是用户听歌的类型的广泛程度,我们选取了用户播放的语言和曲风的数量和占比,不同类型的语言和曲风越多,广度分数越高;
(3)深度刻画的是用户听歌的艺人的小众程度,我们选取了用户与艺人之间的几大核心交互行为,包括播放、收藏红心、点赞评等。首先我们需要基于艺人的热度、生产力和影响力等核心指标计算出艺人的“头腰尾”等级,然后基于艺人的等级计算出用户在不同类型的艺人的消费比例。最终体现到用户颗粒度的指标是,用户对腰尾部艺人的播放/收藏/评论等行为的数量越多,深度分越高;
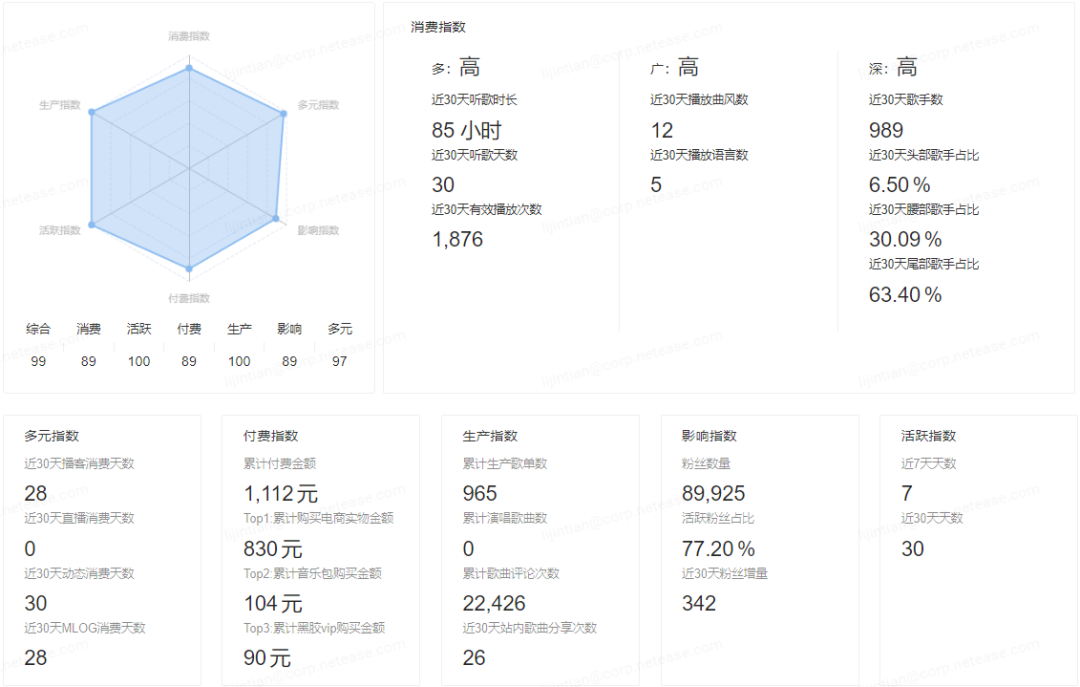
回到这个具体的用户例子上来,用户在音乐消费的多广深上全部是高,是一个十足的音乐发烧友,这类用户在大盘用户中的占比仅有1.5%。
多度上,近30天用户听歌30天,总共播放时长85小时,日均播放时长达到了2.8小时,日均有效播放次数达到了63次;
广度上,近30天用户总共涉猎曲风12种,语言5种,曲风上包括了流行、原声带、二次元、摇滚等:

深度上,近30天用户播放过的艺人有1000个,其中63%的艺人数据尾部艺人,头部艺人的占比仅有6.4%,消费top6的艺人中有5个艺人属于尾部艺人。

用户2:偏好英语摇滚的夜猫子

用户2是一位来自于天津的95后小哥哥,从官网的用户首页的听歌排行就可以明显感受到了满屏的英文歌曲和摇滚气息。
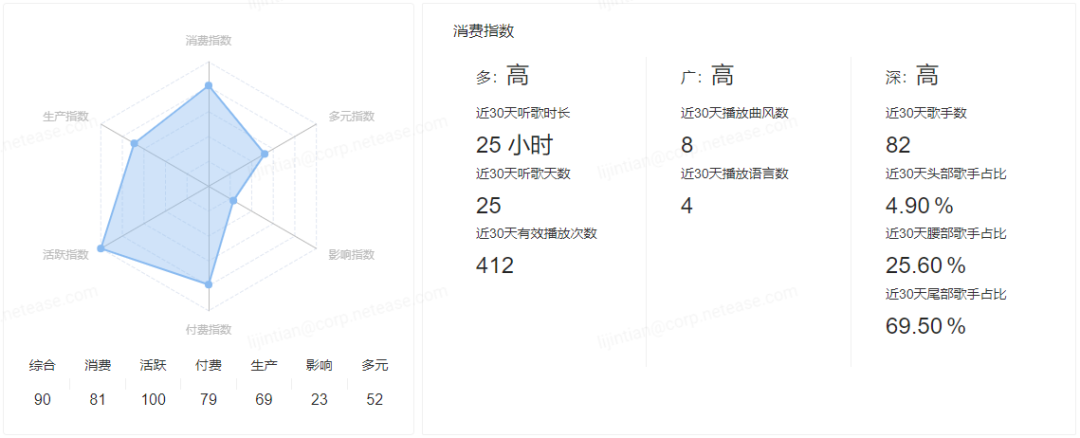
与用户1对比,用户2是一个完全的素人用户,主要消费行为都集中在音乐的消费上,日均听歌时长约1小时,属于平台中的活跃用户,同时听歌的广度和深度都是高,代表着用户也有着广泛的语言曲风偏好,偏好艺人也偏小众。

基于日常的作息时间,我们把一天24小时区分成了6个时间段,分别是早上(6点~8点)、上午(9点~12点)、中午(12点~13点)、下午(14点~17点)、晚上(18点~22点)、深夜(23点~次日5点)。
从用户的听歌时长的分布上看,用户最喜欢在深夜听歌,其次是早上,这两个时间段的累计时长占比达到了93%,是一位非常典型的夜猫子。

对用户的行为进行拆解后可以得到一个很好的验证,就是用户2确实最爱听英语摇滚乐,符合我们在分析用户首页时给出的判断。从语言的消费分布上看,用户2是一位外语歌曲的偏好者,华语类的歌曲的占比小于1%。从播放的来源渠道看,云盘占比达到了91%,其他来自于用户自己创建的歌单和艺人页播放,可见用户对音乐有着自己非常明确的执着。同时,该用户近一个月活跃了25天,可见用户2对于在深夜播放英语摇滚乐的这个兴趣爱好也逐渐塑造了自己的中长期爱好。
2.2 用户偏好挖掘
基于用户个体的简单分析后不难发现,就单指听歌这个事情上,不同用户的行为差异最终可能会导致用户的偏好完全不一样。为了能够更清晰地看清我们的用户,我们基于用户行为和歌曲属性搭建了一整套用户音乐偏好标签体系。根据偏好的行为类型的差异,分别为音乐偏好、行为偏好、垂类偏好三大类型。其中,音乐偏好主要来基于用户播放的音乐的属性计算得到,行为偏好主要基于用户播放音乐的方式来计算得到,垂类偏好主要基于用户对非音乐内容的播放计算得到。
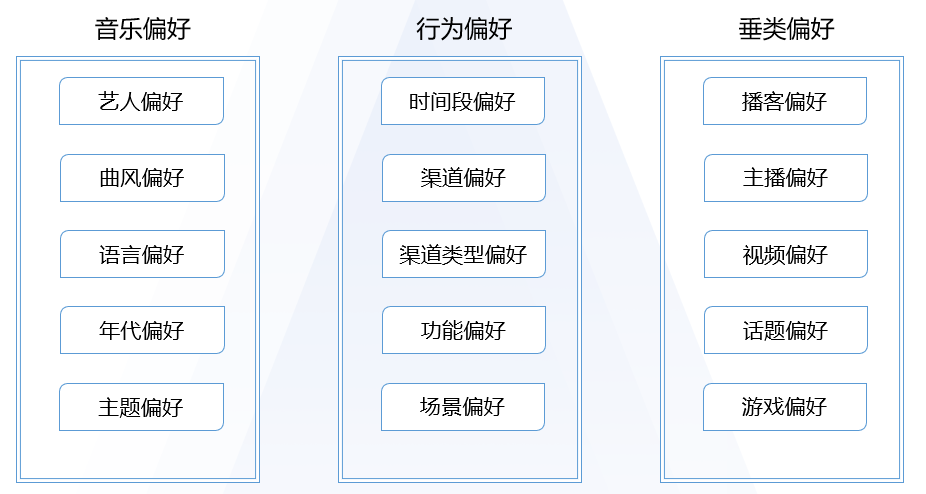
基于这套用户偏好的标签体系,我们可以快速定位一个用户的典型特征,并且圈选出类似的人群,生成人群包之后即可发送到用户触达平台使用。为了方便理解,下面我们以艺人偏好的挖掘作为例子展示如何通过用户的原始行为,挖掘出用户的偏好标签。
步骤一:寻找偏好数据特征
我们知道,用户在平台中活跃和听歌,就会跟歌曲产生各种各样的交互,沉淀了海量的行为数据。在数据分析和建模面前,数据量越多越好,但是对于海量的零散的数据,却无法直接使用。针对这个痛点,我们重申了用户偏好挖掘的重要性,用户偏好标签将直接影响着数据分析、挖掘建模、算法推荐、运营触达和广告投放等所有跟用户相关的全链路流程。
为了能够更好地还原用户的真实偏好,我们基于数据分布和常态认知提炼出用户跟音乐内容的核心互动行为,不同行为由于发生的难易程度不同,体现到数据层面就是行为发生占播放的比例的大小差异。如下图所示,从左到右,从下到上,行为发生的难易程度依次递增,在还原用户真实偏好这个场景的重要性也随之增大。
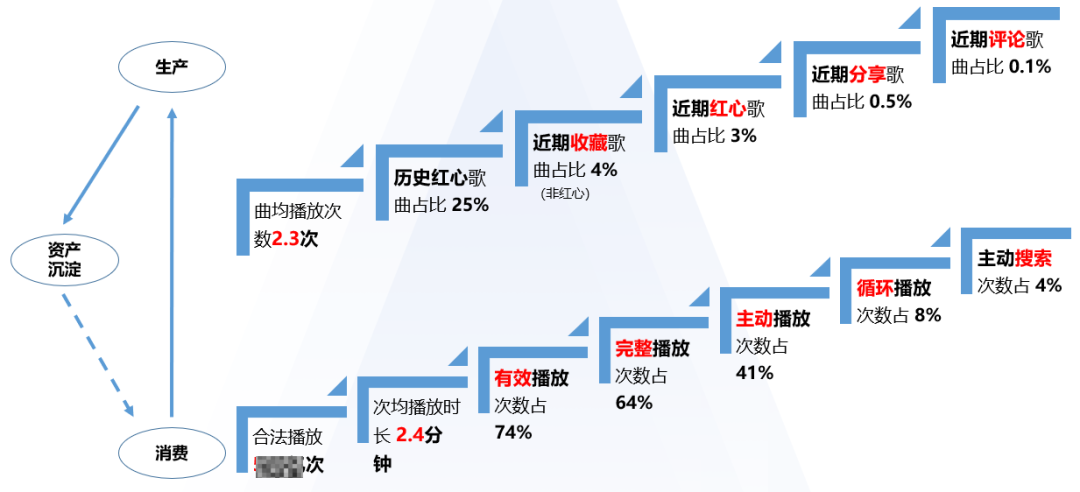
(1)针对云音乐对于绝大多数的用户来说,听歌就是刚需,也就是上图中的音乐消费行为。其中,音乐消费行为又可以基于不同的播放方式,分成了有效播放、完整播放、主动播放、循环播放、搜索播放等。
(2)在听歌的过程中,用户会对自己感兴趣的内容进行更深层次的交互行为,如红心、收藏、分享、评论等,这些行为本质上是用户基于平台的内容生产属于自己偏好的组合内容,也就是上图中的生产行为。
(3)随着用户进行不断的内容生产,用户的资产沉淀也会越来越多,部分优质的UGC歌单就会逐渐被分发,从而影响着更多平台上的其他用户对其进行消费,形成一个良性循环。
步骤二:计算用户偏好
在完成用户行为的提炼后,结合内容的属性或者行为的渠道,即可开始用户偏好的计算。下面,我们以偏好艺人的挖掘作为例子,展开描述我们是如何还原用户的艺人偏好。
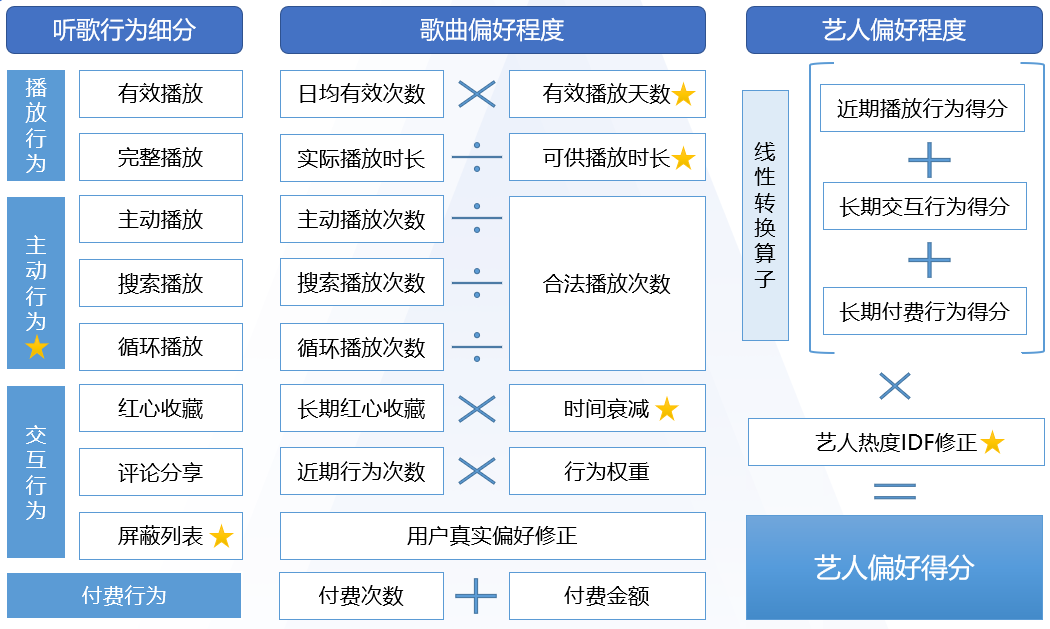
(1)数据清洗
听歌行为可以细分成四大类,每一类的发生难度递增:播放行为 → 主动行为 → 交互行为 → 付费行为。
针对播放行为相关的数据,鉴于数据量过于庞大,所以选择统计近30天的行为,在后续的验证工作中发现,用户的近30天行为最能体现用户的近期偏好。
针对交互行为和付费行为的数据,我们采用的是历史全量数据,数据颗粒度统计到用户、行为类型和行为时间,这样方便后续的特征处理。
(2)特征工程
首先,针对不同行为的数据特性,加工成可用的数据指标,具体有以下几步:
通过对数转换把播放类的数据分布转化成对数分布,好处在于降低数据极值对模型的影响;
通过计算不同行为的占比,来消除由于个体行为过多或者过少导致的计算偏差;
通过引入时间衰减权重,来处理不同发生时间的行为的对用户真实偏好的影响的合理性;
通过平滑计算不同行为的占比,来确定不同行为的权重,并对同类型行为进行线性组合;
通过分别对付费次数和金额进行算分并相加,来实现强调次数的同时也强调了金额。
(3)计算偏好
基于已经加工好的特征,进行标准化和加权汇总。其中,标准化使用max_min的方式进行,这种计算方式的好处是不影响原始数据的单调性和个体间差异,能够等比例缩放原始数据。
在完成基础数据的汇总后即可以得到用户偏好的原始得分,基于原始得分的倒序即可大致了解用户对不同艺人的偏好程度。但是此时会比较容易发现大部分用户的top 10偏好艺人中会经常出现林俊杰、薛之谦等热门大艺人,所以我们还需要引入IDF因子,以实现对大艺人的降权处理。
对最终得到的艺人偏好得分进行排序后,即可以得到用户对不同艺人偏好的排名。对得分进行标准化处理后,就可以得到用户对不同艺人偏好程度的差异。
步骤三:解决疑难问题
我们在做艺人挖掘的时候,会遇到很多棘手的问题需要处理,下面几点是我们在处理相关问题的时候提出的创新点:

问题一:用户真实偏好被大数据淹没
针对这个问题,我们主张仅仅使用用户的主动行为进行计算,这个方案可以完美解决数据不聚焦的问题,也能更好地还原用户的真实偏好。
问题二:完播率差异比较小
目前平台中完播率的计算默认为完播的次数除以总的播放次数,由于用户对歌曲的复播行为比较少,直接导致用户对大部分歌曲的完播率偏高或者偏低。为了增加特征的信息增益,我们通过计算用户的实际播放时长和歌曲的可供播放时长的比值计算一个线性的完播比例,解决原有完播率过于粗糙的问题。
问题三:如何合理计算不同时间行为的权重
我们假设用户每一次行为都有一个原始温度值(这里假设每次行为将增加1摄氏度),随着时间的推移,行为也会随之降温。
因此,我们引用了牛顿冷却定律的原理:
当前温度=上一期温度 x exp(-冷却系数 x 间隔的小时数)
类比的,
时间衰减得分=1 x exp(-冷却系数 x 用户发生行为的时间距离当前的天数)
其中冷却系数一般选择0.002~0.01之间,差异在于半衰期(衰减一半所需的时间)的长短。0.002代表的半衰期大概是一年,冷却系数越大,半衰期越短。
问题四:用户的top5偏好经常被大艺人霸榜
由于用户的行为信息对用户偏好的信息增益最大,所以我们在计算用户偏好是最重要的信息就是近一个月的用户行为。因此,我们在做艺人偏好的时候就无法避免一个事实,绝大部分用户都与头部艺人进行行为的交集,导致了头部艺人经常出现在用户偏好艺人top列表中。
我们的解决方案是,引入艺人IDF权重因子,该思路主要受益于NLP中的TF-IDF算法,IDF的全称翻译是反文档频次,如果某个词在所有文档中出现的次数越多,那么IDF值就越小,IDF主要用过倒数和对数的处理方式降低了热词在文本分析中的权重。相应的,艺人的IDF的公式如下:
艺人IDF=ln(近一个月有发生播放行为的用户数 / 近一个月有播放该艺人的用户数)
这里我们使用的是用户数量,主要是基于不同用户对不同艺人的播放是随机的假设上的,可以基于业务场景的需求,把该计算公式中的用户数改成有效播放次数、播放时长或者红心用户数等核心指标。
用户洞察在精细化运营上的应用
基于对用户在微观层面的偏好洞察,最终我们挖掘出用户在音乐、行为及垂类等方面的偏好。这些偏好的建设为用户的精细化运营提供了强有力的抓手。回应到背景介绍上谈到的对低活用户促活和流失用户召回命题,我们将上面的用户微观音乐洞察结果,结合人x内容匹配后,在push通道上实验不同的策略对用户促活和召回的效果。
我们将用户偏好应用在push促活和召回场景上,给用户推送其偏好的内容,实现千人千面的个性化push推送。比如,用户偏好的艺人最近发布了新歌,就可以推送 [你喜欢的艺人XX发新歌了];如果用户是偏好深夜听歌的用户,就可以为在深夜为其推送睡眠相关主题的push。
经过几个月的实验,对于促活流失用户,基于偏好推送的个性化push的召回点击率,相较千人一面push提升了50%。其中[偏好艺人发新歌]的push召回效率非常好,点击率相较全量提升了118%。

基于偏好推送个性化push,对于云音乐回归版权的用户召回也起到了助力作用。以英皇为例,英皇版权回归,需要告知用户,这个场景需要解决的问题就是给哪些用户推送push,推送具体什么内容。
选择哪些用户,有两个角度,一是选择与回归歌曲发生互动行为的用户,比如歌曲的红心、分享、收藏、评论用户;第二个维度,就是选择关注或者偏好回归艺人的用户,来圈出更多对英皇版权感兴趣的用户。在这个场景下,通过偏好艺人push的推送,促活人群的召回效率提升了23%,召回人群的效率提升了33%。
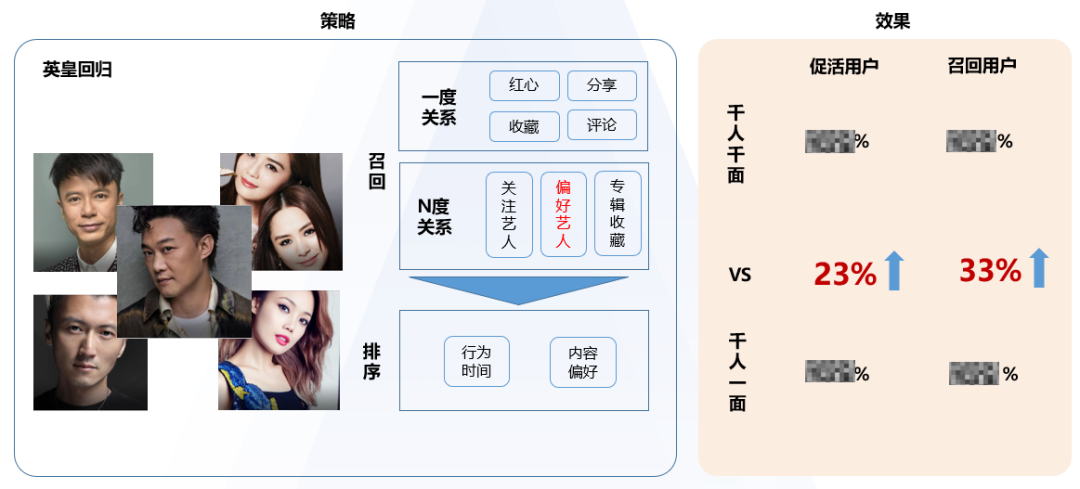
用户偏好除了应用在促活流失用户召回外,还已经应用到新客留存、音乐交友等多个业务场景,提升了各业务精细化运营的能力。
未来展望
一方面需要在用户的音乐消费偏好洞察上进一步深挖,丰富用户个人profile,比如用户的听歌场景诉求,用户是仅早晚高峰的公共交通工具上听歌,还是边学习边听歌,还是深夜下班后用歌曲拂去一天的劳累?再比如用户的听歌情感诉求,是动感的、伤感的、亦或是emo的?
另一方面持续拓展用户的偏好洞察结果在精细化运营中的应用,比如个性化banner、气泡提示等多个场景,提高其对业务的效率。
以上两部分已经在陆续开展中,后续阶段性的成果产出会持续分享,也希望和有兴趣的同学一起讨论,一起构建音乐领域的用户微观洞察和精细化运营的有效实践!
相关专利:

宇嬛,云音乐用户策略数据产品,负责用户标签、用户圈选、定向投放等用户精细化运营相关的数据产品;
栗子流,云音乐资深数据产品经理,负责用户触达及内容投放策略平台的数据产品等工作;
Timzon,云音乐资深数据挖掘工程师,负责用户侧、内容侧数据资产沉淀,搭建用户画像产品;
杨斐,云音乐高级数据挖掘工程师,负责用户侧数据建设和特征挖掘、诺伦push数据体系搭建、效果监控等

