
Python副业600元,爬取金融期货数据
任务简介
首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示:
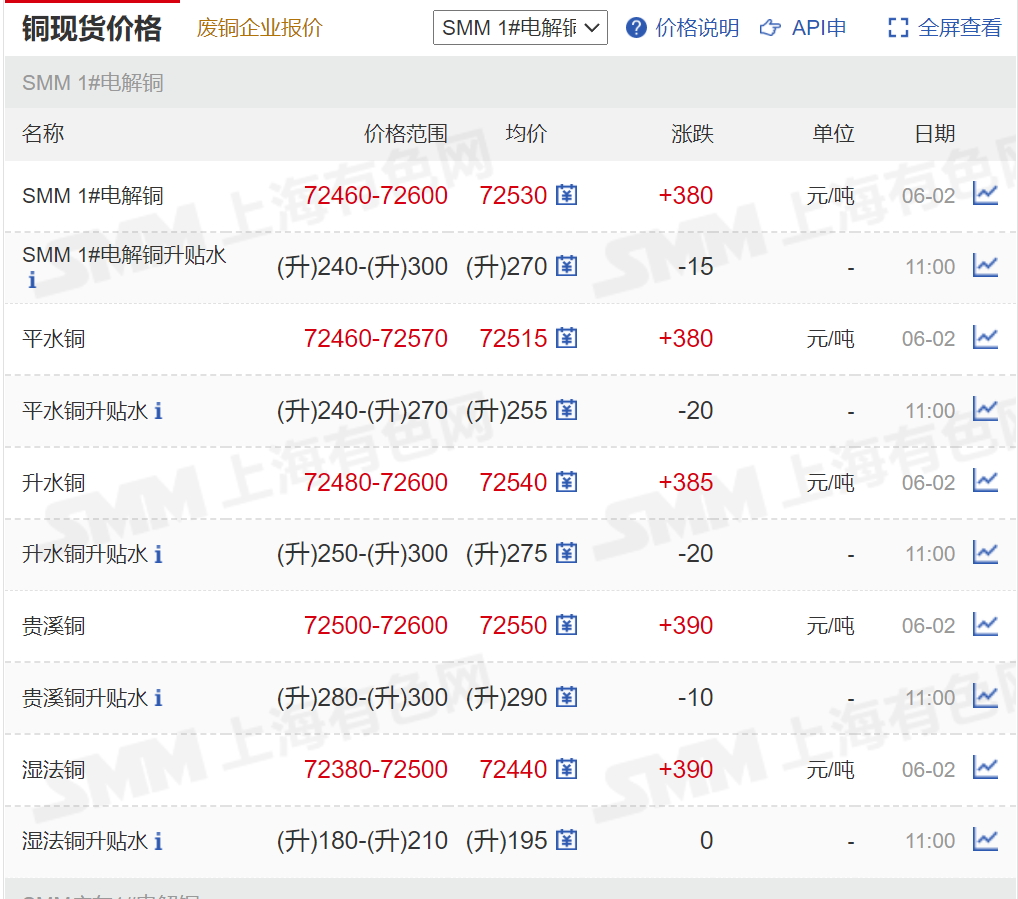
如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可。但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金......
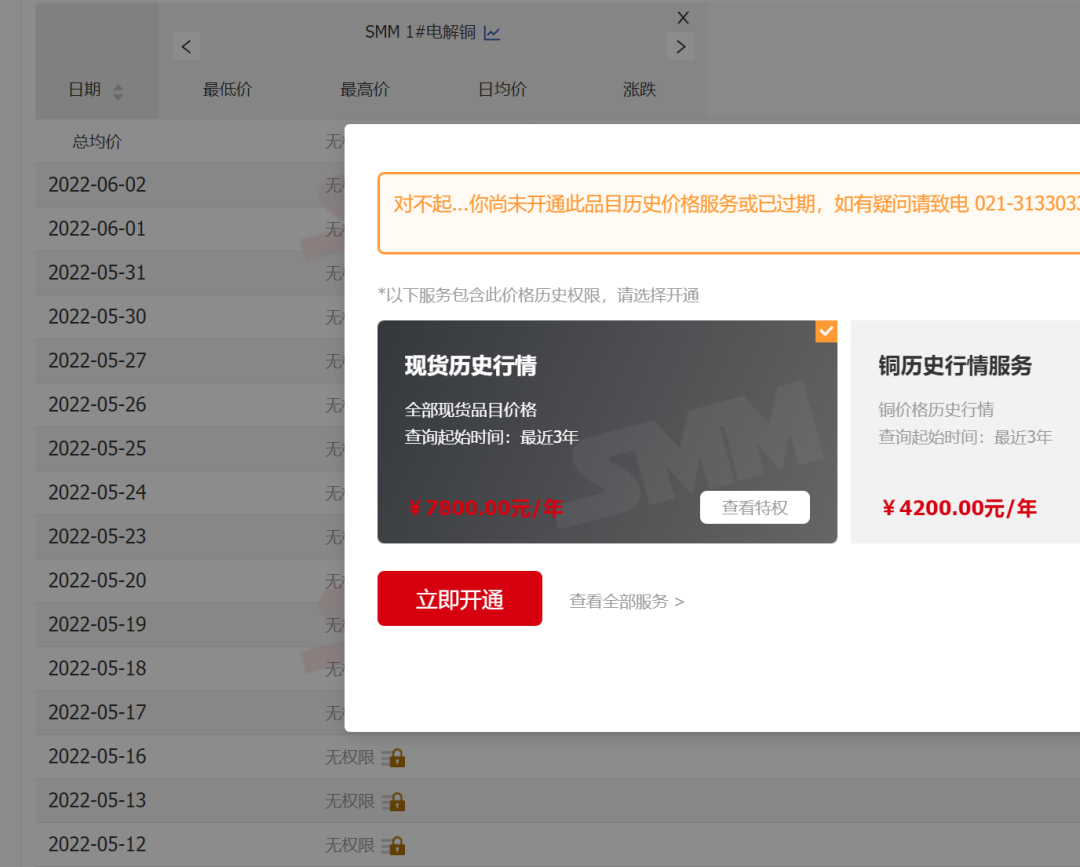
鉴于,客户需求仅仅是“沪铜CU2206”一项期货的历史价格,氪金会员性价比不高,因此,实际的任务目标变为如何获取的历史价格,目标变为全网有公开提供数据的网址。而最终解决该问题,是求助于万能的百度^_^。找到了合适的网站,且获取数据的难度也几乎降到了最低难度。
解决步骤
百度搜索资源:这个步骤是整个任务完整的最难点(实际不难),但这里卖个关子,全文不公布最终找到的网站,大家试试看能否搜索到,以及花费多少时间^_^。 解析网站的请求,最终找到的网站经解析后,发现获取数据是通过get的方式提交参数。而请求的参数如下: /price?starttime=1638545822&endtime=1654357022&classid=48,一看就知是开始时间、结束时间的时间戳,以及商品id。再解析headers,居然连cookie都不需要,说明没有反爬!没有反爬!没有反爬!不得不说运气爆棚!解析响应数据:由于响应数据是规整的json格式数据,使用pandas的read_json直接能够获取dataframe格式的数据,该步骤也并无难度。
代码实现
鉴于网站没有反爬,且参数简单,实际上的任务主要是规划一下如何设计增量更新数据信息的流程,具体代码如下:
# -*- coding: utf-8 -*-
# @author: Lin Wei
# @contact: 580813@qq.com
# @time: 2022/6/2 8:53
"""
1. 这是爬取沪铜的程序
2. 该网站沪铜当月的数据实际请求地址是:'(实际网址)/price?starttime={starttime}&endtime={endtime}&classid={classid}'
2.1. starttime为起始日期的时间戳
2.2. endtime为结束日期的时间戳
2.3. classid为查询商品的id
3. 该网址可以直接发起请求获取数据
"""
import time
from datetime import datetime
import pathlib as pl
import requests
import pandas as pd
class Spider:
"""
爬取网站数据的爬虫对象
"""
def __init__(self, starttime: str = None, endtime: str = None, classid: int = 48):
"""
初始化对象属性
:param starttime: 数据的起始日期,文本日期格式,示例 2022-1-1
:param endtime: 数据的结束日期,文本日期格式,示例 2022-1-1
:param classid: 商品id,默认48
"""
self.classid = classid # 商品id
self.data = pd.DataFrame() # 初始化空dataframe
self.data_file = pl.Path('./data/hutong.xlsx') # 爬取的数据存储文件
# 列名字典
self.cols_dict = {
'createtime': '日期',
'classid': '商品',
'start': '开盘',
'end': '收盘',
'min': '最低',
'max': '最高',
'move': '涨跌',
'move_percent': '涨跌百分比'
}
# 商品id字典
self.classid_dict = {
48: 'CU2206'
}
# 获取爬取的开始时间与结束时间
self.starttime, self.endtime = self.make_starttime_endtime(starttime=starttime, endtime=endtime)
# 初始化需要爬取的url
self.url = '(实际地址)/price?starttime={starttime}&endtime={endtime}&classid={classid}'
# 初始化headers
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
def make_starttime_endtime(self, starttime: str, endtime: str):
"""
制作起始日期,逻辑如下;
1.如果有传入日期,则根据传入的日期,定义起始日期与结束日期
2.如果未传入参数,则根据读取到的历史数据文件中的最大日期作为起始日期、以当前日期为结束日期
3.如果未读取到历史数据文件,或文件中的最大日期为空,则以2021-1-1作为起始日期,以当前日期作为结束日期
:param starttime: 数据的起始日期,文本日期格式,示例 2022-1-1
:param endtime: 数据的结束日期,文本日期格式,示例 2022-1-1
:return:
"""
self.read_data() # 读取历史爬取数据
now = datetime.now() # 获取当前时间的时间戳整数部分
if endtime: # 如果非空
year, month, day = endtime.split('-')
endtime = int(now.replace(year=int(year), month=int(month), day=int(day)).timestamp())
else:
endtime = int(now.timestamp())
if starttime:
year, month, day = starttime.split('-')
starttime = int(now.replace(year=int(year), month=int(month), day=int(day)).timestamp())
else:
starttime = self.data['日期'].max()
if pd.isnull(starttime): # 如果开始日期是空值
starttime = int(now.replace(year=2021, month=1, day=1).timestamp())
else:
starttime = int(
now.replace(year=starttime.year, month=starttime.month, day=starttime.day).timestamp())
return starttime, endtime
def read_data(self):
"""
读取历史数据
:return:
"""
if self.data_file.is_file(): # 如果历史数据文件存在
self.data = pd.read_excel(self.data_file)
self.data['日期'] = self.data['日期'].map(lambda x: x.date())
else: # 如果历史数据文件不存在,那么初始化一个只有列名的dataframe,
self.data = pd.DataFrame(self.cols_dict.values()).set_index(0).T
def crawl_data(self):
"""
爬取数据
:return:
"""
retry_times = 0
while retry_times < 10: # 重试10次
try:
res = requests.get(
self.url.format(starttime=self.starttime, endtime=self.endtime, classid=self.classid),
headers=self.headers, timeout=30)
if res.status_code == 200: # 如果返回状态至为200,进行后续数据加工
data = pd.read_json(res.text) # json格式转换为dataframe
data['createtime'] = data['createtime'].map(lambda x: datetime.fromtimestamp(x).date()) # 时间戳日期转换为日期
data.rename(columns=self.cols_dict, inplace=True) # 重命名列
data = data[self.cols_dict.values()] # 截取需要的列
data['商品'] = self.classid_dict.get(self.classid, '未知商品,请维护classid_dict字典') # 转换商品名
data.sort_values(by=['商品', '日期'], ascending=True, inplace=True) # 按日期升序排序
return data
else:
retry_times += 1
print(f'返回状态码是 {res.status_code},等待5秒后重新发起请求')
time.sleep(5)
except Exception as e:
retry_times += 1
print(f'请求发生错误,等待5秒后重新发起请求, 错误信息: {e}')
time.sleep(5)
print('发起10次请求均未能获得数据')
return pd.DataFrame()
def concat_and_write_data(self, data: pd.DataFrame):
"""
合并数据,并将数据写入文件
:param data: 传入需要合并的数据
:return:
"""
self.data = pd.concat([self.data, data]) # 合并数据
self.data = self.data.drop_duplicates(['日期', '商品'], keep='last') # 数据根据商品名称与日期进行去重,每次保留最新的记录
if not self.data_file.parent.is_dir(): # 检查数据文件的目录是否存在,如不存在则创建新目录
self.data_file.parent.mkdir()
self.data.to_excel(self.data_file, index=False, encoding='utf-8') # 输出数据为excel格式
def run(self):
"""
运行程序
:return:
"""
data = spider.crawl_data() # 运行爬取
if len(data) > 0: # 如果爬取到的数据不为空
self.concat_and_write_data(data)
start = str(datetime.fromtimestamp(self.starttime))[:10]
end = str(datetime.fromtimestamp(self.endtime))[:10]
print(f'{start}至{end}数据爬取任务完成')
def pivot_data(self):
"""
将数据转换为透视表式的格式
:return:
"""
data = self.data.copy()
data['年月'] = data['日期'].map(lambda x: f'{str(x)[:7]}')
data['日'] = data['日期'].map(lambda x: x.day)
data = data.pivot_table(values='收盘', index='日', columns='年月', aggfunc='sum')
data_mean = data.mean().to_frame().T
data_mean.index = ['平均值']
data = pd.concat([data, data_mean])
data.to_excel(self.data_file.parent.parent / 'data.xlsx', encoding='utf-8')
if __name__ == '__main__':
spider = Spider()
spider.run()
spider.pivot_data()
print(spider.data)
总结
从技术角度来看,经过一步步解析,任务是简单的,入门requests爬虫以及入门pandas数据分析就可以完成(唯一的难度在找到合适的目标)。但是换个角度,从经济价值来看,又是很有价值的,即节约了某网站高昂的年费(注:并不是说年费不值得,只是局限在需求仅仅是CU2206一项数据上时,性价比太低),同时又避免了人工操作的繁琐,以及可能产生的错误。用很小的学习成本就能解决大大的问题,所以,还等什么呢?开启Python之路吧!
关注我的抖音账号:Python导师-蚂蚁
每晚21点直播,给你讲解副业、Python学习路线;
评论