
基于自动编码器的赛车视角转换与分割

来源:Deephub Imba 本文约1800字,建议阅读5分钟
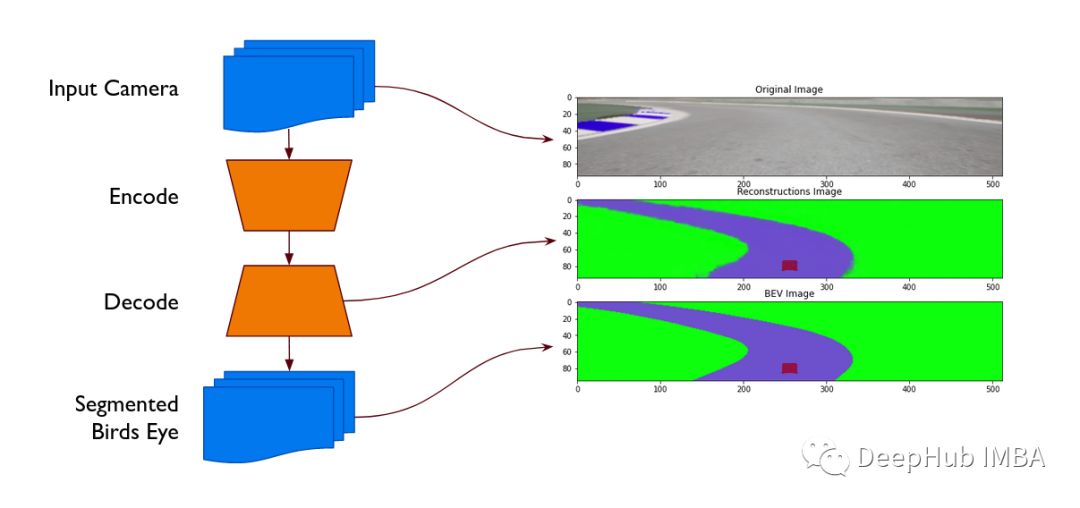
本篇文章将介绍如何将赛道的图像转换为语义分割后鸟瞰图的轨迹。



import cv2
import tqdm
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class BEVVAE(nn.Module):
"""Input should be (bsz, C, H, W) where C=3, H=42, W=144"""
def __init__(self, im_c=3, im_h=95, im_w=512, z_dim=32):
super().__init__()
self.im_c = im_c
self.im_h = im_h
self.im_w = im_w
encoder_list = [
nn.Conv2d(im_c, 32, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(128, 256, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(256, 512, kernel_size=4, stride=2, padding=1),
nn.ReLU(),
nn.Flatten(),
]
self.encoder = nn.Sequential(*encoder_list)
self.encoder_list = encoder_list
sample_img = torch.zeros([1, im_c, im_h, im_w])
em_shape = nn.Sequential(*encoder_list[:-1])(sample_img).shape[1:]
h_dim = np.prod(em_shape)
self.fc1 = nn.Linear(h_dim, z_dim)
self.fc2 = nn.Linear(h_dim, z_dim)
self.fc3 = nn.Linear(z_dim, h_dim)
self.decoder = nn.Sequential(
nn.Unflatten(1, em_shape),
nn.ConvTranspose2d(
em_shape[0],
256,
kernel_size=4,
stride=2,
padding=1,
output_padding=(1, 0),
),
nn.ReLU(),
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, output_padding=(1, 0)),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, output_padding=(1, 0)),
nn.ReLU(),
nn.ConvTranspose2d(
64, 32, kernel_size=4, stride=2, padding=1, output_padding=(1, 0)
),
nn.ReLU(),
nn.ConvTranspose2d(32, im_c, kernel_size=4, stride=2, padding=1, output_padding=(1, 0)),
nn.Sigmoid(),
)
def reparameterize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
esp = torch.randn(*mu.size(), device=mu.device)
z = mu + std * esp
return z
def bottleneck(self, h):
mu, logvar = self.fc1(h), self.fc2(h)
z = self.reparameterize(mu, logvar)
return z, mu, logvar
def representation(self, x):
return self.bottleneck(self.encoder(x))[0]
def encode_raw(self, x: np.ndarray, device):
# assume x is RGB image with shape (bsz, H, W, 3)
p = np.zeros([x.shape[0], 95, 512, 3], np.float)
for i in range(x.shape[0]):
p[i] = x[i][190:285] / 255
x = p.transpose(0, 3, 1, 2)
x = torch.as_tensor(x, device=device, dtype=torch.float)
v = self.representation(x)
return v, v.detach().cpu().numpy()
def squish_targets(self, x: np.ndarray) -> np.ndarray:
# Take in target images and resize them
p = np.zeros([x.shape[0], 95, 512, 3], np.float)
for i in range(x.shape[0]):
p[i] = cv2.resize(x[i], (512, 95)) / 255
x = p.transpose(0, 3, 1, 2)
return x
def encode(self, x):
h = self.encoder(x)
z, mu, logvar = self.bottleneck(h)
return z, mu, logvar
def decode(self, z):
z = self.fc3(z)
return self.decoder(z)
def forward(self, x):
# expects (N, C, H, W)
z, mu, logvar = self.encode(x)
z = self.decode(z)
return z, mu, logvar
def loss(self, bev, recon, mu, logvar, kld_weight=1.0):
bce = F.binary_cross_entropy(recon, bev, reduction="sum")
kld = -0.5 * torch.sum(1 + logvar - mu ** 2 - logvar.exp())
return bce + kld * kld_weight
以上代码修是从L2R示例代码进行了进一步修改,https://github.com/learn-to-race/l2r
https://github.com/sksq96/pytorch-vae
编辑:王菁
校对:林亦霖
评论