
“趣味运动会项目”教学思路

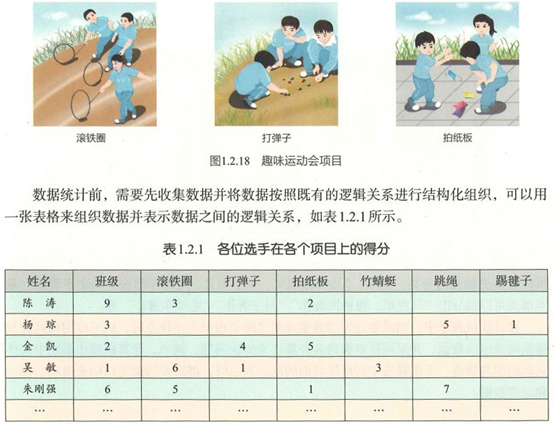





xm = ['陈涛', '杨琼', '金凯','吴敏', '朱刚强', '李海涛']a = [[1,3,0,2,0,0,0,0],[3,0,0,0,0,5,1,0],[2,0,4,5,0,0,0,0], # a[0][1]、a[1][0]和a[2]的值分别是多少?[1,6,1,0,3,0,0,0],[2,5,0,1,0,7,0,0],[3,0,3,0,5,0,6,0]] # 这样存储数据有什么缺陷?# 输出比赛得分信息print('姓名','班级','滚铁圈','打弹子','拍纸板','竹蜻蜓','跳绳','踢毽子',sep="\t")for i in range(0,len(xm)):pass # 请编写代码,输出如上图所示的比赛得分信息# 计算个人总分和班级团体总分bjdf = [0] * 4 # 3个班为什么要分配4个元素空间?for i in range(0,len(xm)):for j in range(1, 7):a[i][7] = 填空1 # a[i][7]的值是什么?bjdf[a[i][0]] = 填空2 # a[i][0]的值是什么?bjdf[a[i][0]]的值是什么?print(a[i][7], end=", ")print() # 本条语句的功能是什么?若删除它有何后果?print(bjdf)
xm = ['陈涛', '杨琼', '金凯', '吴敏', '朱刚强', '李海涛']bj = [1, 3, 2, 1, 2, 3]d1 = [3, 0, 0, 6, 5, 0]d2 = [0, 0, 4, 1, 0, 3]d3 = [2, 0, 5, 0, 1, 0]d4 = [0, 0, 0, 3, 0, 5]d5 = [0, 5, 0, 0, 7, 0]d6 = [0, 1, 0, 0, 0, 6]# 输出比赛信息print('姓名','班级','滚铁圈','打弹子','拍纸板','竹蜻蜓','跳绳','踢毽子',sep="\t")for i in range(0, len(xm)):print(xm[i],bj[i],d1[i],d2[i],d3[i],d4[i],d5[i],d6[i],sep="\t")
# 计算个人总分和班级团体总分tot = [0] * 6bjdf = [0] * 4 # 3个班为什么要分配4个元素空间?for i in range(0, len(xm)):tot[i] = d1[i]+d2[i]+d3[i]+d4[i]+d5[i]+d6[i] # tot[i]的值是什么?bjdf[bj[i]] += tot[i] # bj[i]的值是什么?bjdf[bj[i]]的值是什么?# 输出各选手总得分print('各选手总得分:')print('姓名','总分',sep="\t")for i in range(0, len(xm)):print(xm[i],tot[i],sep="\t")print('各班级总得分:')print('班级','总分',sep="\t")for i in range(1, max(bj)+1):print(i,bjdf[i],sep="\t")
xm = ['陈涛', '杨琼', '金凯','吴敏', '朱刚强', '李海涛']a =[[1,3,0,2,0,0,0,0],[3,0,0,0,0,5,1,0],[2,0,4,5,0,0,0,0],[],[2,5,0,1,0,7,0,0],[3,0,3,0,5,0,6,0]]
xm = ['陈涛', '杨琼', '金凯','吴敏', '朱刚强', '李海涛']a = [[1, 3, 2, 1, 2, 3],[3, 0, 0, 6, 5,0],[0, 0, 4, 1, 0, 3],[2, 0, 5, 0, 1, 0],[],[0, 5, 0, 0, 7, 0],[0, 1, 0, 0, 0, 6],[0] * len(xm)]
* 4为数组bjdf分配了4个元素空间,原因是bjdf以班级号为下标,最大班级号为3。为避免下标越界,需要为数组分配4个元素空间,这样虽然浪费了bjdf[0]的空间,但是可以直接使用bjdf[i]表示班级i的总分,给编程带来了方便。
xm = ['陈涛', '杨琼', '金凯','吴敏', '朱刚强', '李海涛']a =[[1,3,0,2,0,0,0,0],[3,0,0,0,0,5,1,0],[2,0,4,5,0,0,0,0],[1,6,1,0,3,0,0,0],[2,5,0,1,0,7,0,0],[3,0,3,0,5,0,6,0]] # 这样存储数据有什么缺陷?# 输出比赛信息print('姓名','班级','滚铁圈','打弹子','拍纸板','竹蜻蜓','跳绳','踢毽子',sep="\t")for i in range(0,len(xm)):print(xm[i],end="\t")for j in range(0, 7):print(a[i][j],end="\t")print()# 计算个人总分和班级团体总分bjdf = [0] * 4 # 3个班为什么要分配4个元素空间?for i in range(0,len(xm)):for j in range(1, 7):a[i][7] += a[i][j] # a[i][7]的值是什么?bjdf[a[i][0]] += a[i][7] # a[i][0]的值是什么?bjdf[a[i][0]]的值是什么?print(a[i][7], end=", ")print()print(bjdf)
需要本文word文档、源代码和课后思考答案的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
评论