
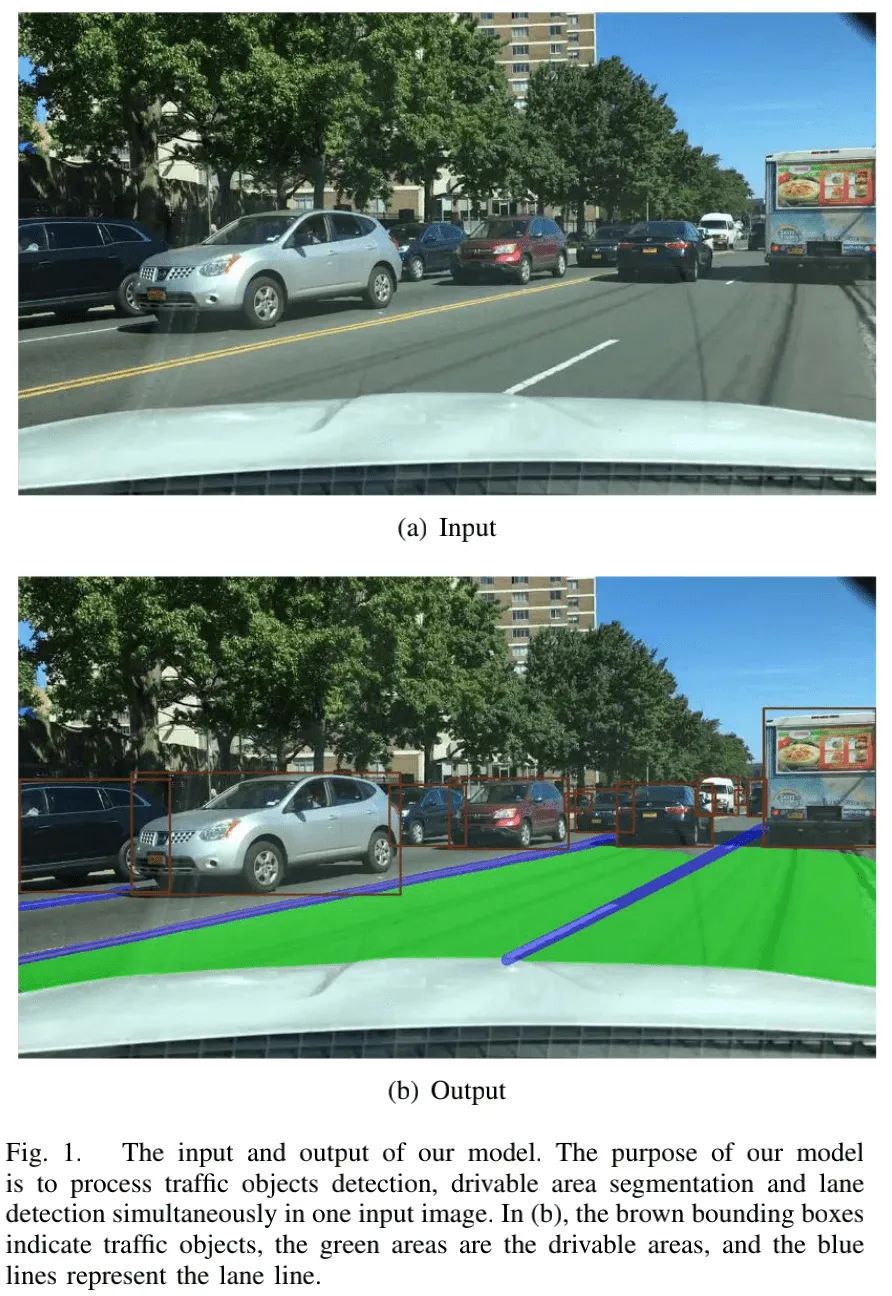
人类高质量视觉模型YOLOP开源:同时处理三大视觉任务,还能各种超越SOTA…

极市导读
华中科技大学王兴刚团队近日开源了一项在全景驾驶感知方面的工作,该工作能够同时进行交通目标检测、驾驶区域分割以及车道线检测,并且在三个任务上都取得了SOTA。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

arXiv:https://arxiv.org/abs/2108.11250
code:https://github.com/hustvl/YOLOP
code@opencv:https://github.com/hpc203/YOLOP-opencv-dnn
本文是华中科技大学王兴刚团队在全景驾驶感知方面的工作,提出了一种能够在嵌入式平台上实时处理三个感知任务(目标检测、可驾驶区域分割、车道线检测)的方案YOLOP。所提YOLOP不仅具有超高的推理速度,同时在极具挑战性的BDD100K三个任务上均取得了非常优异的性能。
Abstract
全景驾驶感知系统是自动驾驶非常重要的一部分,实时高精度感知系统可以帮助车辆作出合理的驾驶决策。
我们提出一种全景驾驶感知网络YOLOP同时进行交通目标检测、驾驶区域分割以及车道线检测。YOLOP包含一个用于特征提取的编码,三个用于处理特定任务的解码器。所提方案在极具挑战的BDD100K数据集上表现非常好,从精度与速度角度来看,所提方法在三个任务上取得了SOTA性能。此外,我们还通过消融实验验证了多任务学习模型的有效性。
据我们所知,该工作是首个可以在嵌入式设备(Jetson TX2)上实时处理三个视觉任务的方案,同时具有非常优异的精度。
Method
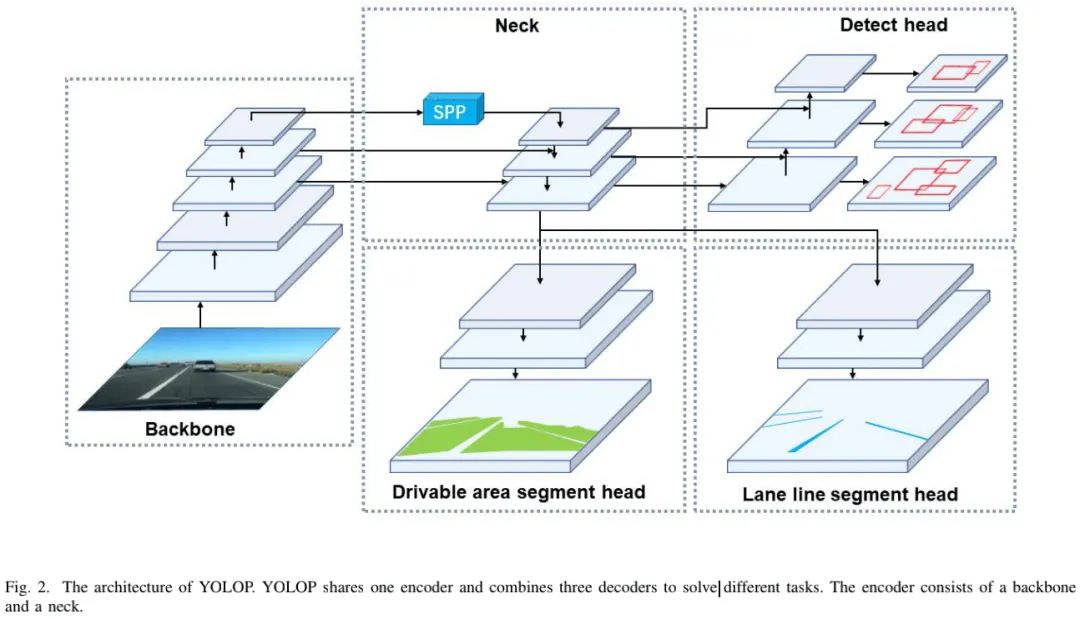
上图给出了本文所提方案YOLOP的网络架构示意图,它是一种单阶段网络,包含一个共享编码器,三个用于特定任务的解码器。不同解码器之间并没有复杂的、冗余共享模块,这可以极大降低计算量,同时使得该网络易于端到端训练。
Encoder
该网络中的编码器由骨干网络与Neck网络构成:
Backbone :骨干网络用于提取输入图像的特征,考虑到YOLOv4在目标检测中的优异性能,我们选择CSPDarkNet作为骨干网络。
Neck :Neck用于对骨干网络提取的特征进行融合,我们主要采用了SPP与FPN构建Neck模块。SPP用于生成融合不同尺度的特征;FPN则在不同语义层面融合特征,使得生成特征包含多尺度、多语义级信息。
Decoders
YOLOP包含三个用于三个任务的解码器:
Detect Head 类似YOLOv4,我们采用了基于Anchor的多尺度检测机制。首先,我们采用PAN进行更优特征融合,然后采用融合后特征进行检测:多尺度特征的每个grid被赋予三个先验anchor(包含不同纵横比),检测头将预测位置偏移、高宽、类别概率以及预测置信度。
Driable Area Segment Head & Lane Line Segment Head 驾驶区域分割头与车道线分割头采用了相同结构。我们将FPN的输出特征(分辨率为)送入到分割分支。我们设计的分割分支非常简单,通过三次上采样处理输出特征尺寸为,代表每个像素是驾驶区域/车道线还是背景的概率。由于Neck中已包含SPP模块,我们并未像PSPNet添加额外的SPP模块。此外,我们采用了最近邻上采样层以降低计算量。因此,分割解码器不仅具有高精度输出,同时推理速度非常快。
Loss Function
由于该网络包含三个解码器,故多任务损失包含三部分:
Detection Loss :它是分类损失、目标检测以及目标框损失的加权和,描述如下:
其中:为用于降低类别不平衡的Focal Loss,则采用了CIoU损失。
分割:采用带Logits的交叉熵损失。必须要提到的是:中添加了IoU损失。因此,这两个损失的定义如下:
总而言之,最终的损失是由上述三个损失加权得到:
Training Paradigm
我们尝试了不同范式训练上述模型。最简单的是端到端训练,然后三个任务可以进行联合学习。当所有任务相当时,这种训练范式非常有用。此外,我们也尝试了交替优化算法:即每一步聚焦于一个或多个相关任务,而忽视不相关任务。下图给出了本文所用到的step-by-step训练方案。

Experiments
Setting
Dataset Setting 训练数据采用了BDD100K,其中70K用于训练,10K用作验证,20K用于测试。由于测试数据无标签,故我们在验证数据集上进行评估。
Implementation Details 为提升模型性能,我们采用了一些实用技术与数据增广策略。比如,采用K-means聚类生成anchor先验信息;warm-up与cosine学习率衰减机制;Photometric distortion与Geometric distortion数据增广策略。
Result
在这里,我们采用简单的端到端训练方式,将所得结果与其他方案进行对比。
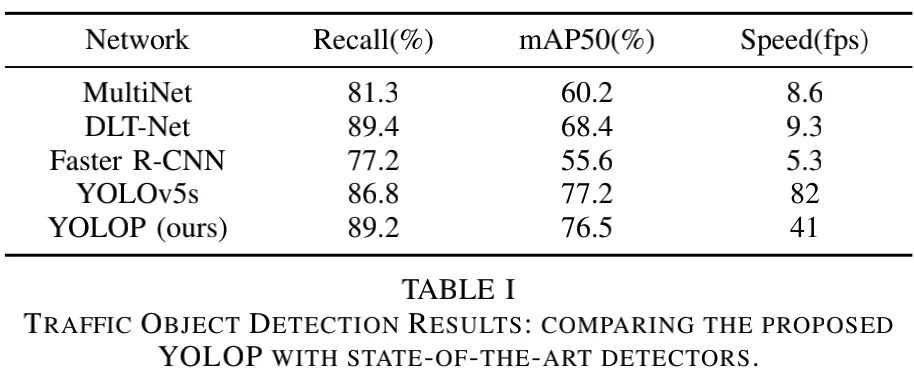
Traffic Object Detection Result 上表给出了所提方案与其他方案的检测性能对比,从中可以看到:
从检测精度来看,YOLOP优于Faster R-CNN、MultiNet以及DLTNet,并与使用大量训练trick的YOLOv5s相当;
从推理耗时来看,YOLOv5s更快,因为YOLOP不仅要进行检测还要进行分割,而YOLOv5s仅需进行检测。交通目标检测结果见下图。

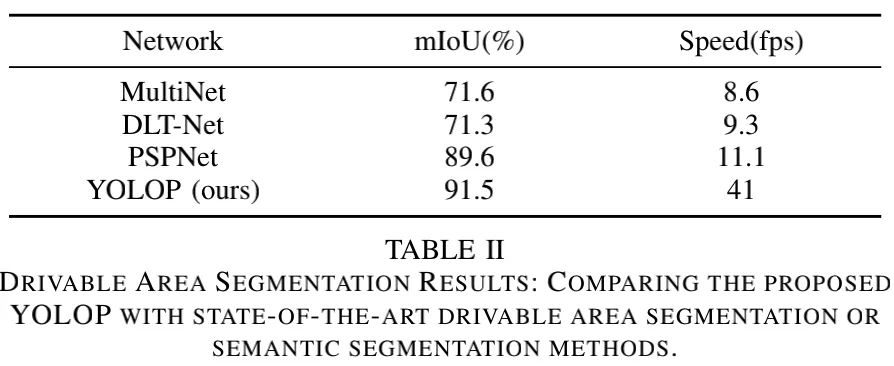
Drivable Area Segmentation Result 上表给出了驾驶区域分割性能对比,从中可以看到:
从推理速度来看,所提方法要比其他方案快4-5倍。
从性能角度来看,所提方案以19.9%、20.2%以及1.9%优于MultiNet、DLTNet以及PSPNet。分割结果可参考下图。


Lane Detection Result 上表给出了车道线检测性能对比,可以看到:所提方案性能远超其他三个方案,下图给出了车道线检测结果示意图。

Ablation Studies
我们设计了两个消融实验进一步说明所提方案的有效性。

End-to-End vs Step-by-Step 上表给出了不同训练机制的性能对比,从中可以看到:
通过端到端训练,所提YOLOP已经表现的非常好,没有必要再进行交替训练优化;
然而,我们发现:先训练检测任务可以取得更高精度。

Multi-task vs Single-task 上表对比了多任务与单任务机制的性能,从中可以看到:多任务机制可以取得与聚焦单一任务训练相当的性能 ;重要的是,相比独立执行每个任务,多任务训练可以节省大量的时间。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“86”获取CVPR 2021:针对域自适应目标检测的域特异性特征直播分享PPT下载~

# 极市平台签约作者#

happy
知乎:AIWalker
AIWalker运营、CV领域八年深耕码农
研究领域:专注low-level领域,同时对CNN、Transformer、MLP等前沿网络架构保持学习心态,对detection的落地应用甚感兴趣。
公众号:AIWalker
作品精选
