
20 个短小精悍的 Numpy 函数
np.full_like
array = np.array([[1, 4, 6, 8], [9, 4, 4, 4], [2, 7, 2, 3]])
array_w_inf = np.full_like(array, fill_value=np.pi, dtype=np.float32)
array_w_inf
array([[3.1415927, 3.1415927, 3.1415927, 3.1415927],
[3.1415927, 3.1415927, 3.1415927, 3.1415927],
[3.1415927, 3.1415927, 3.1415927, 3.1415927]], dtype=float32)
np.logspace
log_array = np.logspace(start=1, stop=100, num=15, base=np.e)
log_array
array([2.71828183e+00, 3.20167238e+03, 3.77102401e+06, 4.44162312e+09,
5.23147450e+12, 6.16178472e+15, 7.25753148e+18, 8.54813429e+21,
1.00682443e+25, 1.18586746e+28, 1.39674961e+31, 1.64513282e+34,
1.93768588e+37, 2.28226349e+40, 2.68811714e+43])np.meshgrid
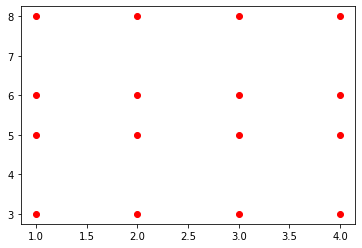
x = [1, 2, 3, 4]
y = [3, 5, 6, 8]
xx, yy = np.meshgrid(x, y)
xx
array([[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]])
yy
array([[3, 3, 3, 3],
[5, 5, 5, 5],
[6, 6, 6, 6],
[8, 8, 8, 8]])
plt.plot(xx, yy, linestyle="none",
marker="o", color="red");
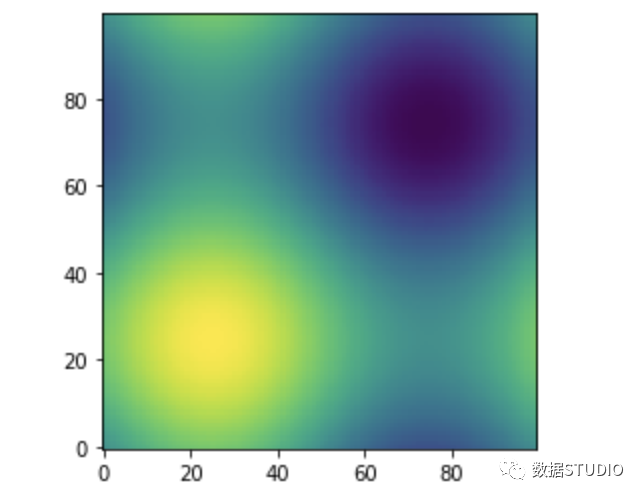
def sinus2d(x, y):
return np.sin(x) + np.sin(y)
xx, yy = np.meshgrid(np.linspace(0, 2 * np.pi, 100), np.linspace(0, 2 * np.pi, 100))
z = sinus2d(xx, yy) # Create the image on this grid
import matplotlib.pyplot as plt
plt.imshow(z, origin="lower",
interpolation="none")
plt.show()
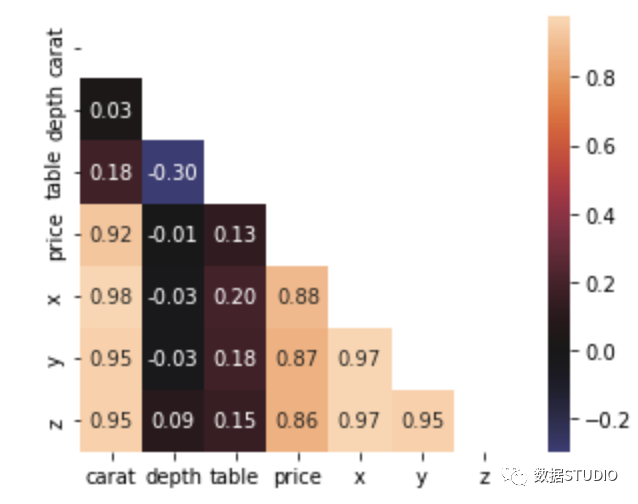
np.triu / np.tril
import seaborn as sns
diamonds = sns.load_dataset("diamonds")
matrix = diamonds.corr()
mask = np.triu(np.ones_like(matrix, dtype=bool))
sns.heatmap(matrix, square=True,
mask=mask, annot=True,
fmt=".2f", center=0);
np.ravel / np.flatten
array = np.random.randint(0, 10, size=(4, 5))
array
array([[6, 4, 8, 9, 6],
[5, 0, 4, 8, 5],
[1, 3, 1, 0, 3],
[2, 3, 3, 6, 5]])
array.ravel()
array([6, 4, 8, 9, 6, 5, 0, 4, 8, 5,
1, 3, 1, 0, 3, 2, 3, 3, 6, 5])
array.flatten()
array([6, 4, 8, 9, 6, 5, 0, 4, 8, 5,
1, 3, 1, 0, 3, 2, 3, 3, 6, 5])
np.vstack / np.hstack
array1 = np.arange(1, 11).reshape(-1, 1)
array2 = np.random.randint(1, 10, size=10).reshape(-1, 1)
hstacked = np.hstack((array1, array2))
hstacked
array([[ 1, 2],
[ 2, 6],
[ 3, 6],
[ 4, 7],
[ 5, 4],
[ 6, 6],
[ 7, 6],
[ 8, 8],
[ 9, 2],
[10, 8]])
array1 = np.arange(20, 31).reshape(1, -1)
array2 = np.random.randint(20, 31, size=11).reshape(1, -1)
vstacked = np.vstack((array1, array2))
vstacked
array([[20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30],
[21, 23, 23, 26, 29, 26, 27, 27, 28, 25, 25]])
np.r_ / np.c_
preds1 = np.random.rand(100)
preds2 = np.random.rand(100)
as_rows = np.r_[preds1, preds2]
as_cols = np.c_[preds1, preds2]
as_rows.shape
(200,)
as_cols.shape
(100, 2)
np.info(np.info)
info(object=None, maxwidth=76,
output=<ipykernel.iostream.OutStream object at 0x0000021B875A8820>,
toplevel='numpy')
Get help information for a function, class, or module.
Parameters
----------
object : object or str, optional
Input object or name to get information about. If `object` is a
numpy object, its docstring is given. If it is a string, available
modules are searched for matching objects. If None, information
about `info` itself is returned.
maxwidth : int, optional
Printing width.
np.where
probs = np.random.rand(100)
idx = np.where(probs > 0.8)
probs[idx]
array([0.80444302, 0.80623093, 0.98833642, 0.96856382, 0.89329919,
0.88664223, 0.90515148, 0.96363973, 0.81847588, 0.88250337,
0.98737432, 0.92104315])
np.all / np.any
array1 = np.random.rand(100)
array2 = np.random.rand(100)
>>> np.all(array1 == array2)
False
a1 = np.random.randint(1, 100, size=100)
a2 = np.random.randint(1, 100, size=100)
>>> np.any(a1 == a2)
True
np.allclose
a1 = np.arange(1, 10, step=0.5)
a2 = np.arange(0.8, 9.8, step=0.5)
np.all(a1 == a2)
False
a1
array([1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. ,
5.5, 6. , 6.5, 7. , 7.5, 8. , 8.5, 9. , 9.5])
a2
array([0.8, 1.3, 1.8, 2.3, 2.8, 3.3, 3.8, 4.3, 4.8,
5.3, 5.8, 6.3, 6.8, 7.3, 7.8, 8.3, 8.8, 9.3])
np.allclose(a1, a2, rtol=0.2)
False
np.allclose(a1, a2, rtol=0.3)
True
np.argsort
random_ints = np.random.randint(1, 100, size=20)
idx = np.argsort(random_ints)
random_ints[idx]
array([ 6, 19, 22, 23, 35, 36, 37, 45, 46, 57,
61, 62, 64, 66, 66, 68, 72, 74, 87, 89])
np.isneginf / np.isposinf
type(np.inf) # type of the infinity
float
type(-np.inf)
float
a = np.array([-9999, 99999, 97897, -79897, -np.inf])
np.all(a.dtype == "float64")
True
np.any(np.isneginf(a))
True np.polyfit
X = diamonds["carat"].values.flatten()
y = diamonds["price"].values.flatten()
slope, intercept = np.polyfit(X, y, deg=1)
slope, intercept
(7756.425617968436, -2256.3605800454034)
from sklearn.linear_model import LinearRegression
lr = LinearRegression().fit(X.reshape(-1, 1), y)
lr.coef_, lr.intercept_
(array([7756.42561797]), -2256.360580045441)
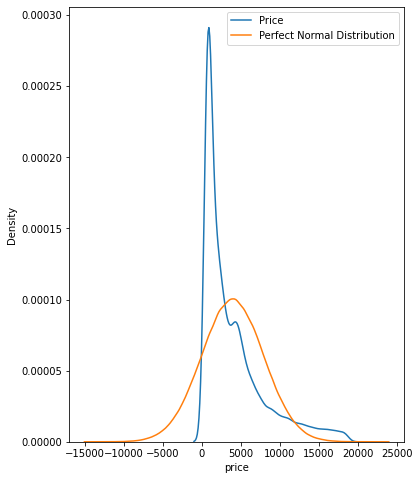
概率分布
fig, ax = plt.subplots(figsize=(6, 8))
price_mean = diamonds["price"].mean()
price_std = diamonds["price"].std()
# Draw from a perfect normal distribution
perfect_norm = np.random.normal(price_mean, price_std, size=1000000)
sns.kdeplot(diamonds["price"], ax=ax)
sns.kdeplot(perfect_norm, ax=ax)
plt.legend(["Price", "Perfect Normal Distribution"]);
np.rint
preds = np.random.rand(100)
np.rint(preds[:50])
array([1., 1., 0., 1., 0., 1., 1., 0., 0., 0., 0., 1., 0., 1., 0., 1., 0.,
1., 0., 1., 1., 1., 1., 1., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 1., 1., 0., 0., 1., 0.])
np.nanmean / np.nan*
a = np.array([12, 45, np.nan, 9, np.nan, 22])
np.mean(a)
nan
np.nanmean(a)
22.0
[func for func in dir(np) if func.startswith("nan")]
['nan',
'nan_to_num',
'nanargmax',
'nanargmin',
'nancumprod',
'nancumsum',
'nanmax',
'nanmean',
'nanmedian',
'nanmin',
'nanpercentile',
'nanprod',
'nanquantile',
'nanstd',
'nansum',
'nanvar']
np.clip
ages = np.random.randint(1, 110, size=100)
limited_ages = np.clip(ages, 10, 70)
limited_ages
array([13, 70, 10, 70, 70, 10, 63, 70, 70, 69, 45, 70, 70, 56, 60, 70, 70,
10, 52, 70, 32, 62, 21, 70, 13, 13, 10, 50, 38, 32, 70, 20, 27, 64,
34, 10, 70, 70, 53, 70, 53, 54, 26, 70, 57, 70, 46, 70, 17, 48, 70,
15, 49, 70, 10, 70, 19, 23, 70, 70, 70, 45, 47, 70, 70, 34, 25, 70,
10, 70, 42, 62, 70, 10, 70, 23, 25, 49, 70, 70, 62, 70, 70, 11, 10,
70, 30, 44, 70, 49, 10, 35, 52, 21, 70, 70, 25, 10, 55, 59])
np.count_nonzero
a = np.random.randint(-50, 50, size=100000)
np.count_nonzero(a)
98993
np.array_split
import datatable as dt
df = dt.fread("data/train.csv").to_pandas()
splitted_dfs = np.array_split(df, 100)
len(splitted_dfs)
100
作者:Bex.T 来源:https://medium.com/
评论