
图解NumPy:常用函数的内在机制
来源:机器之心
支持大量多维数组和矩阵运算的 NumPy 软件库是许多机器学习开发者和研究者的必备工具,本文将通过直观易懂的图示解析常用的 NumPy 功能和函数,帮助你理解 NumPy 操作数组的内在机制。
NumPy 是一个基础软件库,很多常用的 Python 数据处理软件库都使用了它或受到了它的启发,包括 pandas、PyTorch、TensorFlow、Keras 等。理解 NumPy 的工作机制能够帮助你提升在这些软件库方面的技能。而且在 GPU 上使用 NumPy 时,无需修改或仅需少量修改代码。
NumPy 的核心概念是 n 维数组。n 维数组的美丽之处是大多数运算看起来都一样,不管数组有多少维。但一维和二维有点特殊。本文分为三部分:
1. 向量:一维数组
2. 矩阵:二维数组
3. 三维及更高维
本文参考了 Jay Alammar 的文章《A Visual Intro to NumPy》并将其作为起点,然后进行了扩充,并做了一些细微修改。
NumPy 数组和 Python 列表
乍一看,NumPy 数组与 Python 列表类似。它们都可作为容器,能够快速获取和设置元素,但插入和移除元素会稍慢一些。
NumPy 数组完胜列表的最简单例子是算术运算:

除此之外,NumPy 数组的优势和特点还包括:
更紧凑,尤其是当维度大于一维时;
当运算可以向量化时,速度比列表更快;
当在后面附加元素时,速度比列表慢;
通常是同质的:当元素都是一种类型时速度很快。
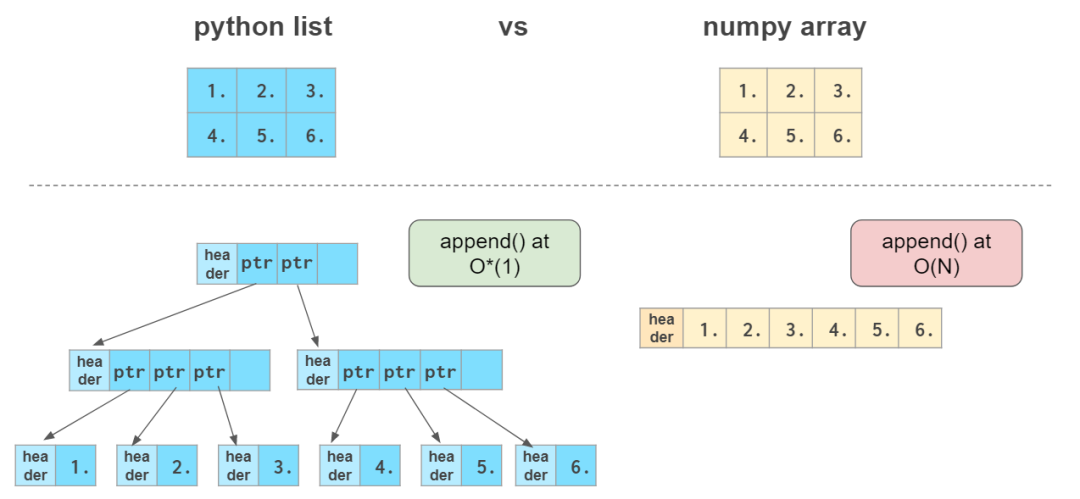
这里 O(N) 的意思是完成该运算所需的时间和数组的大小成正比,而 O*(1)(即所谓的「均摊 O(1)」)的意思是完成运算的时间通常与数组的大小无关。
向量:一维数组
向量初始化
为了创建 NumPy 数组,一种方法是转换 Python 列表。NumPy 数组类型可以直接从列表元素类型推导得到。

要确保向其输入的列表是同一种类型,否则你最终会得到 dtype=’object’,这会影响速度,最终只留下 NumPy 中含有的语法糖。
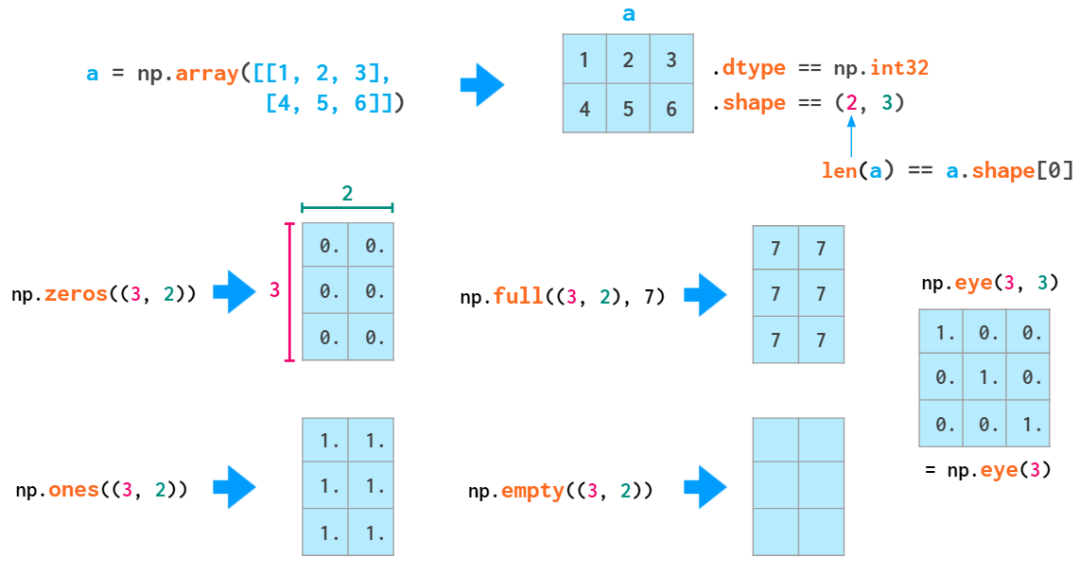
NumPy 数组不能像 Python 列表一样增长。数组的末端没有留下任何便于快速附加元素的空间。因此,常见的做法是要么先使用 Python 列表,准备好之后再将其转换为 NumPy 数组,要么是使用 np.zeros 或 np.empty 预先留下必要的空间:

通常我们有必要创建在形状和元素类型上与已有数组匹配的空数组。

事实上,所有用于创建填充了常量值的数组的函数都带有 _like 的形式:

NumPy 中有两个函数能用单调序列执行数组初始化:
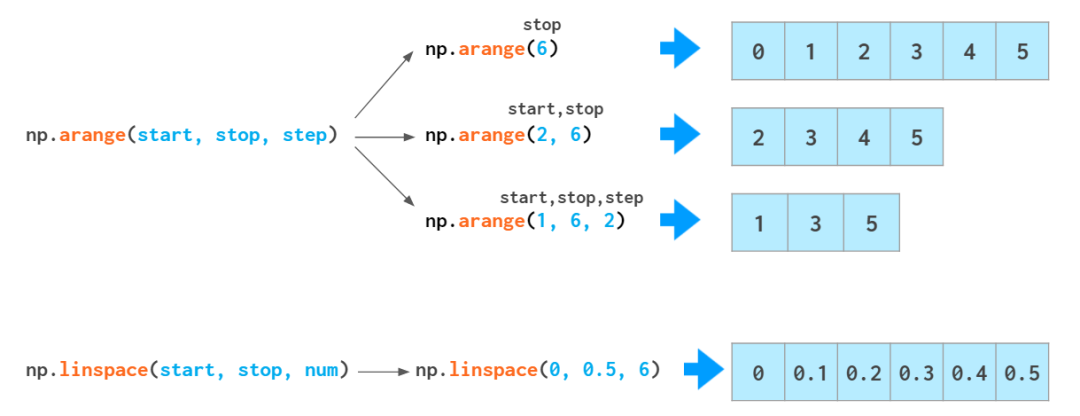
如果你需要类似 [0., 1., 2.] 这样的浮点数数组,你可以修改 arange 输出的类型:arange(3).astype(float),但还有一种更好的方法。arange 函数对类型很敏感:如果你以整型数作为参数输入,它会生成整型数;如果你输入浮点数(比如 arange(3.)),它会生成浮点数。
但 arange 并不非常擅长处理浮点数:

在我们眼里,这个 0.1 看起来像是一个有限的十进制数,但计算机不这么看。在二进制表示下,0.1 是一个无限分数,因此必须进行约分,也由此必然会产生误差。也因为这个原因,如果向 arange 函数输入带分数部分的 step,通常得不到什么好结果:你可能会遇到差一错误 (off-by-one error)。你可以使该区间的末端落在一个非整数的 step 数中(solution1),但这会降低代码的可读性和可维护性。这时候,linspace 就可以派上用场了。它不受舍入的影响,总能生成你要求的元素数值。不过,使用 linspace 时会遇到一个常见的陷阱:它统计的是数据点的数量,而不是区间,因此其最后一个参数 num 通常比你所想的数大 1。因此,上面最后一个例子中的数是 11,而不是 10。
在进行测试时,我们通常需要生成随机数组:

向量索引
一旦你的数组中有了数据,NumPy 就能以非常巧妙的方式轻松地提供它们:
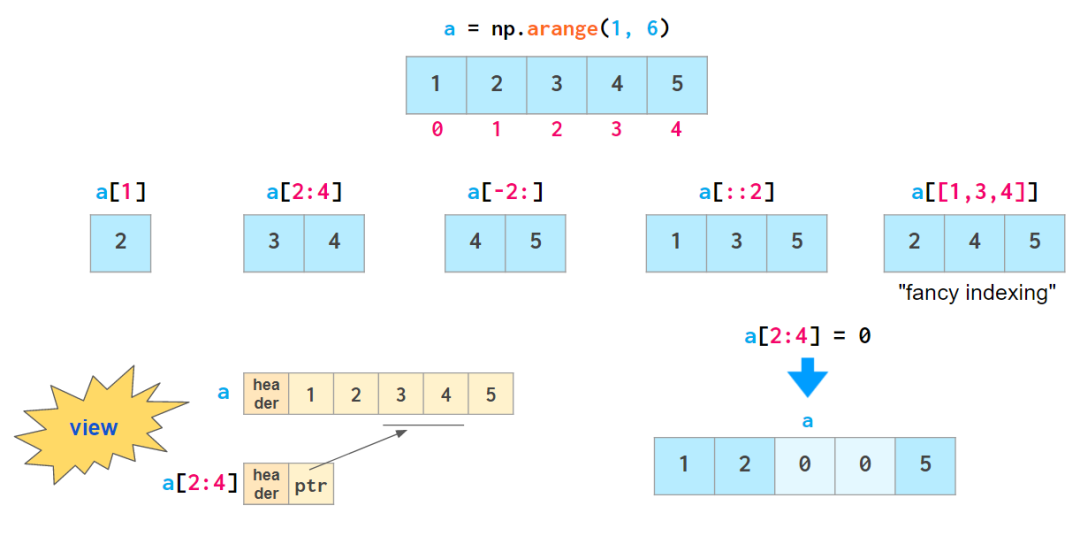
除了「花式索引(fancy indexing)」外,上面给出的所有索引方法都被称为「view」:它们并不存储数据,也不会在数据被索引后发生改变时反映原数组的变化情况。
所有包含花式索引的方法都是可变的:它们允许通过分配来修改原始数组的内容,如上所示。这一功能可通过将数组切分成不同部分来避免总是复制数组的习惯。

Python 列表与 NumPy 数组的对比
为了获取 NumPy 数组中的数据,另一种超级有用的方法是布尔索引(boolean indexing),它支持使用各类逻辑运算符:
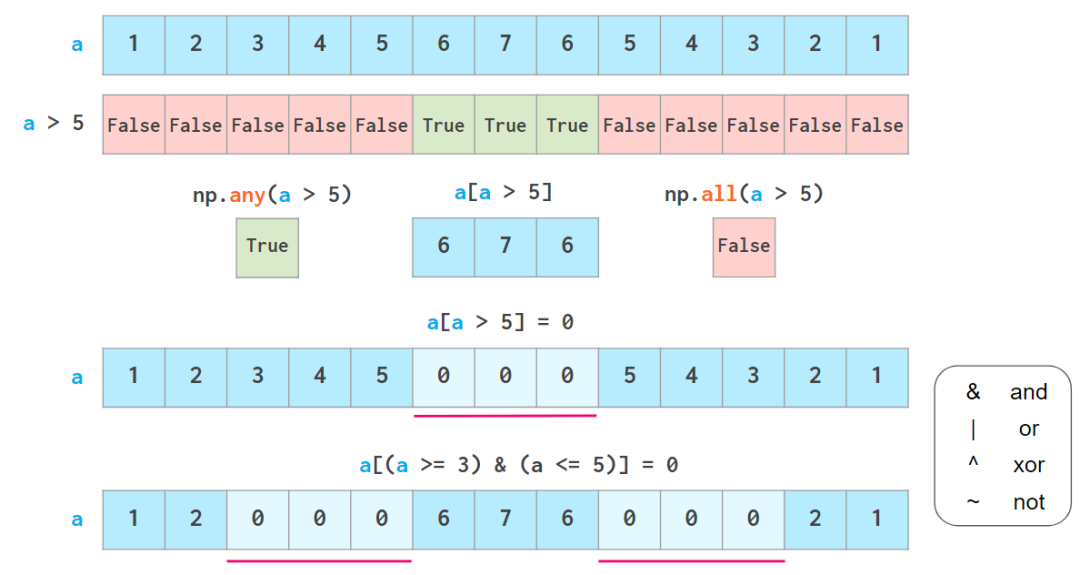
any 和 all 的作用与在 Python 中类似,但不会短路。
不过要注意,这里不支持 Python 的「三元比较」,比如 3<=a<=5。
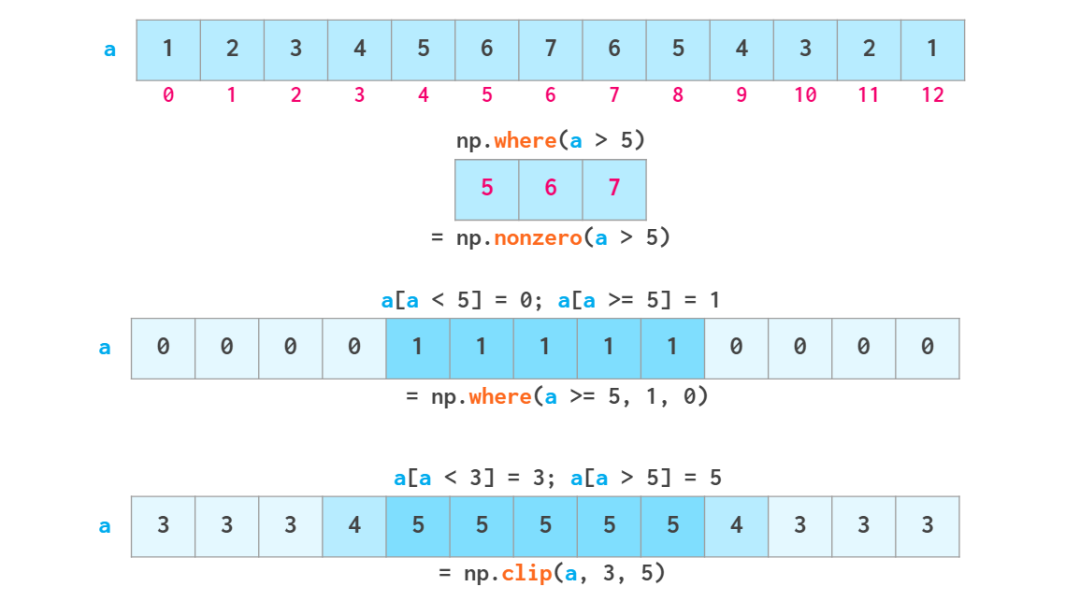
如上所示,布尔索引也是可写的。其两个常用功能都有各自的专用函数:过度重载的 np.where 函数和 np.clip 函数。它们的含义如下:
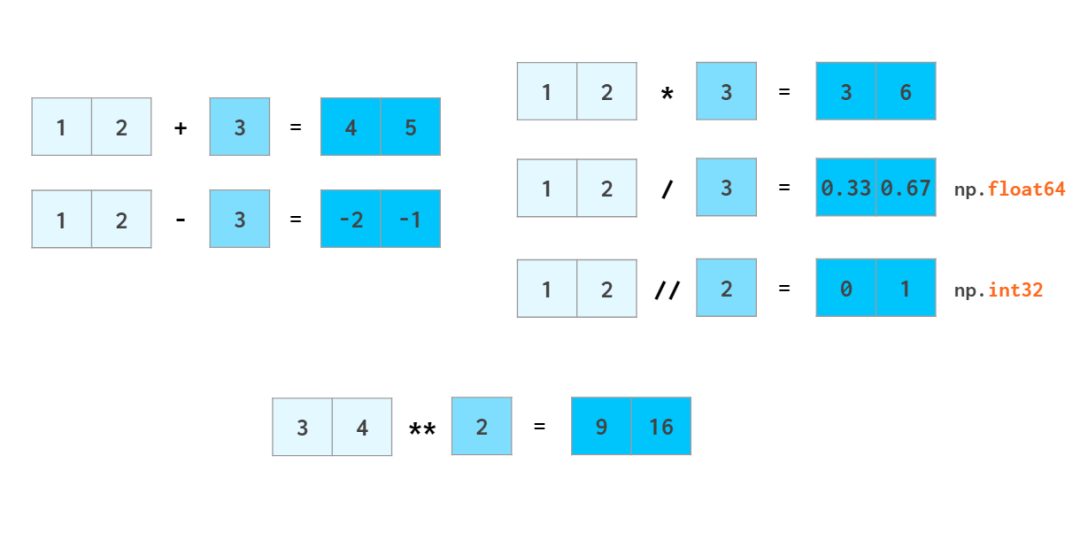
向量运算
NumPy 在速度上很出彩的一大应用领域是算术运算。向量运算符会被转换到 C++ 层面上执行,从而避免缓慢的 Python 循环的成本。NumPy 支持像操作普通的数那样操作整个数组。
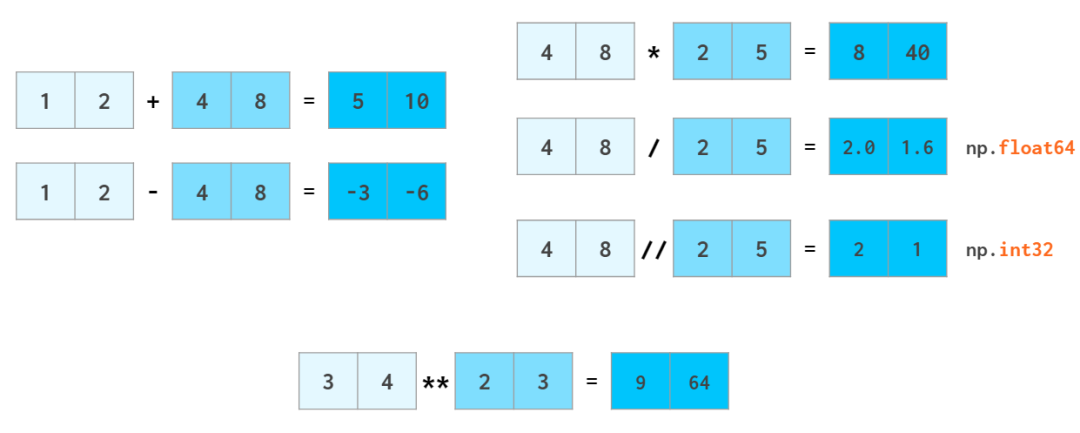
与 Python 句法一样,a//b 表示 a 除 b(除法的商),x**n 表示 xⁿ。
正如加减浮点数时整型数会被转换成浮点数一样,标量也会被转换成数组,这个过程在 NumPy 中被称为广播(broadcast)。
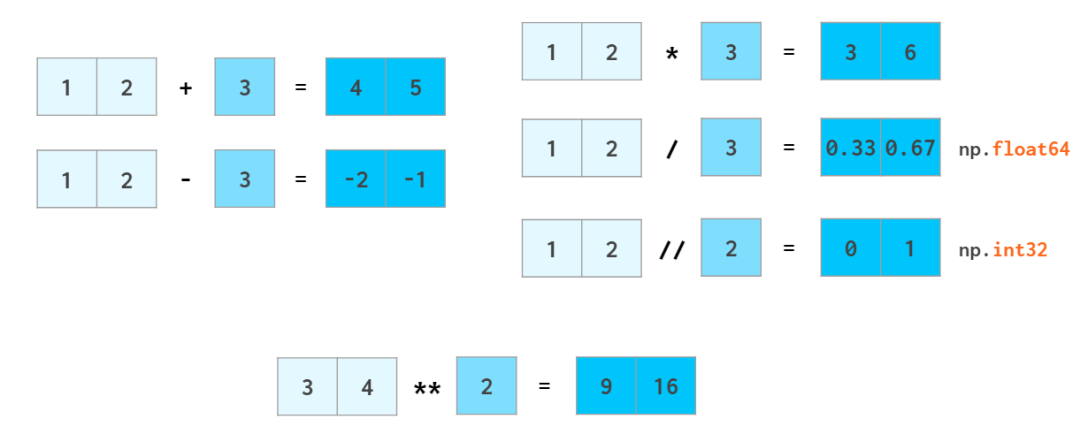
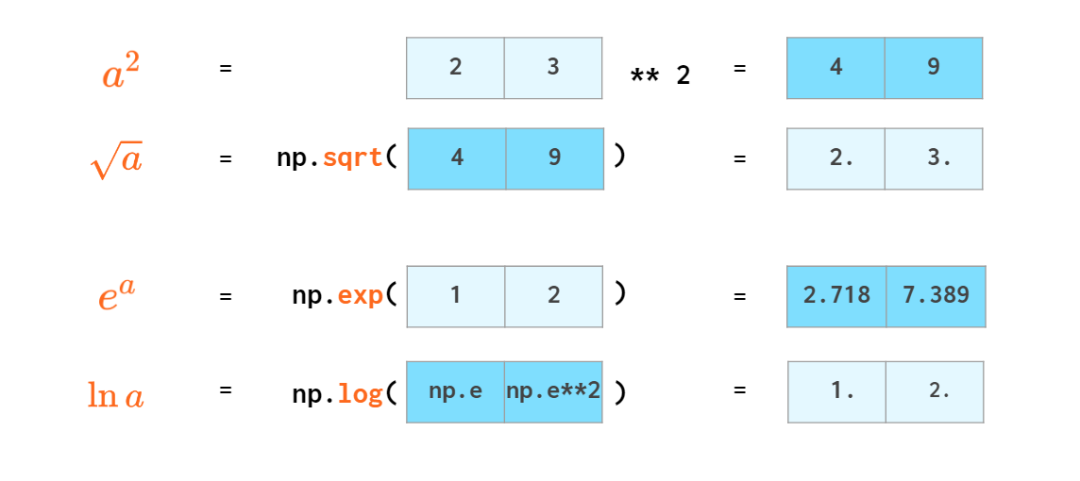
大多数数学函数都有用于处理向量的 NumPy 对应函数:
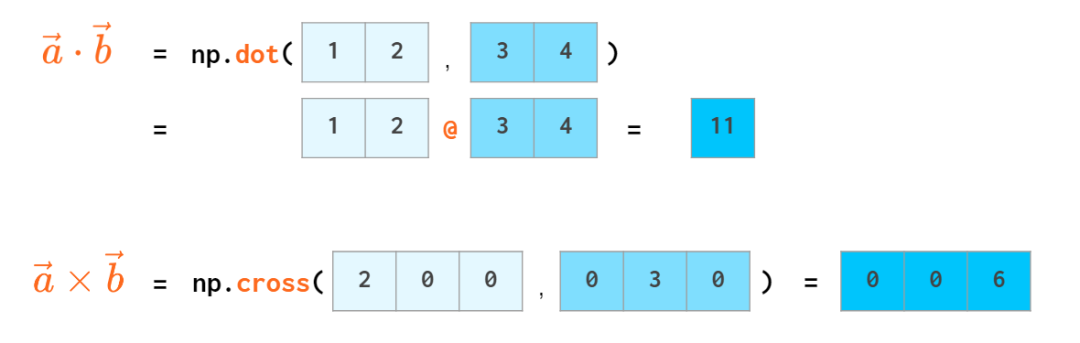
标量积有自己的运算符:
执行三角函数时也无需循环:

我们可以在整体上对数组进行舍入:

floor 为舍、ceil 为入,around 则是舍入到最近的整数(其中 .5 会被舍掉)
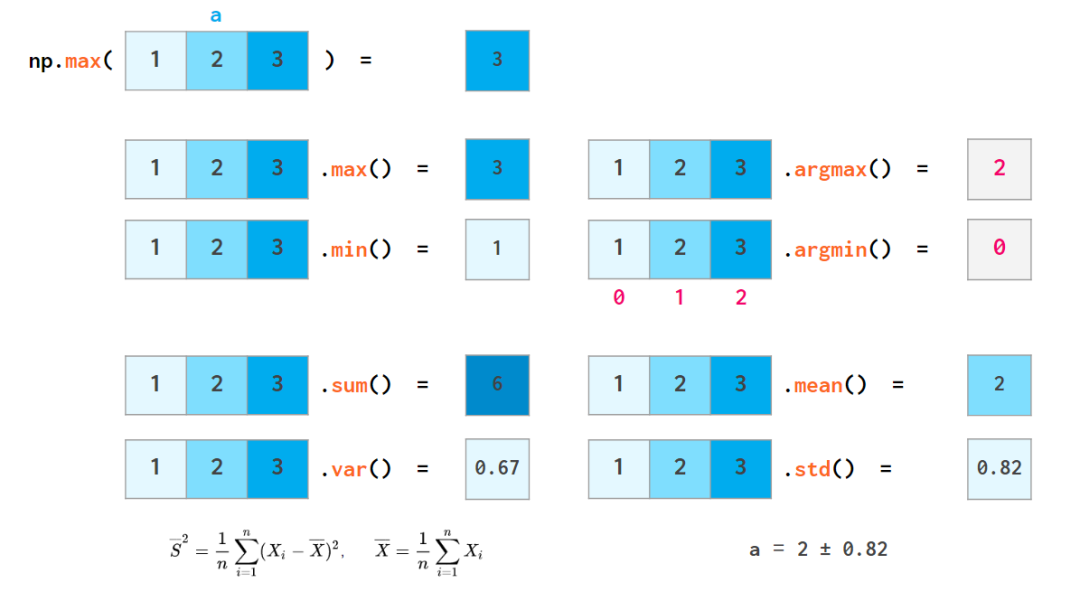
NumPy 也能执行基础的统计运算:
NumPy 的排序函数没有 Python 的排序函数那么强大:

Python 列表与 NumPy 数组的排序函数对比
在一维情况下,如果缺少 reversed 关键字,那么只需简单地对结果再执行反向,最终效果还是一样。二维的情况则会更困难一些(人们正在请求这一功能)。
搜索向量中的元素
与 Python 列表相反,NumPy 数组没有索引方法。人们很久之前就在请求这个功能,但一直还没实现。
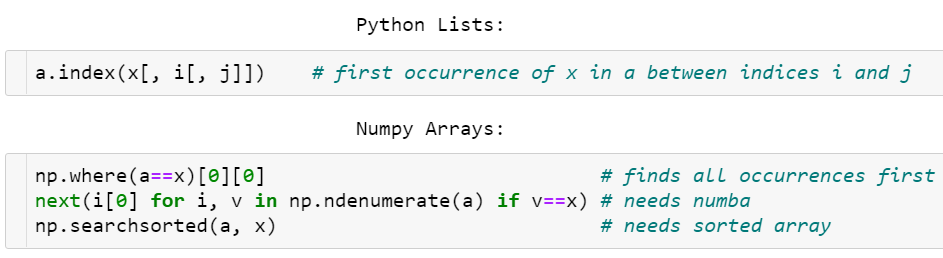
Python 列表与 NumPy 数组的对比,index() 中的方括号表示可以省略 j 或同时省略 i 和 j。
一种查找元素的方法是 np.where(a==x)[0][0],但这个方法既不优雅,速度也不快,因为它需要检查数组中的所有元素,即便所要找的目标就在数组起始位置也是如此。
另一种更快的方式是使用 Numba 来加速 next((i[0] for i, v in np.ndenumerate(a) if v==x), -1)。
一旦数组的排序完成,搜索就容易多了:v = np.searchsorted(a, x); return v if a[v]==x else -1 的速度很快,时间复杂度为 O(log N),但它需要 O(N log N) 时间先排好序。
事实上,用 C 来实现它进而加速搜索并不是问题。问题是浮点比较。这对任何数据来说都不是一种简单直接可用的任务。
比较浮点数
函数 np.allclose(a, b) 能在一定公差下比较浮点数数组。
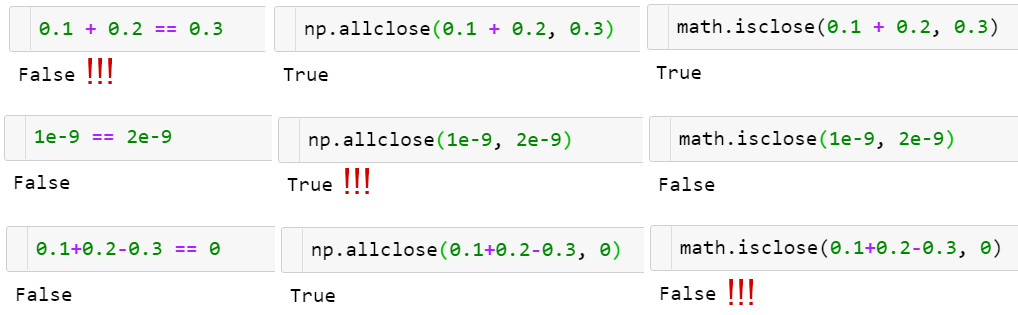
函数 np.allclose(a, b) 的工作过程示例。并没有万能方法!
np.allclose 假设所有被比较的数都在典型的 1 的范围内。举个例子,如果要在纳秒级的速度内完成计算,则需要用默认的 atol 参数值除以 1e9:np.allclose(1e-9, 2e-9, atol=1e-17) == False.
math.isclose 则不会对要比较的数进行任何假设,而是依赖用户给出合理的 abs_tol 值(对于典型的 1 的范围内的值,取默认的 np.allclose atol 值 1e-8 就足够好了):math.isclose(0.1+0.2–0.3, abs_tol=1e-8)==True.
除此之外,np.allclose 在绝对值和相对公差的公式方面还有一些小问题,举个例子,对于给定的 a 和 b,存在 allclose(a, b) != allclose(b, a)。这些问题已在(标量)函数 math.isclose 中得到了解决,我们将在后面介绍它。对于这方面的更多内容,请参阅 GitHub 上的浮点数指南和对应的 NumPy 问题(https://floating-point-gui.de/errors/comparison/)。
矩阵:二维数组
NumPy 曾有一个专门的 matrix 类,但现在已经弃用了,所以本文会交替使用「矩阵」和「二维数组」这两个术语。
矩阵的初始化句法与向量类似:
这里必须使用双括号,因为第二个位置参数是 dtype(可选,也接受整数)。
随机矩阵生成的句法也与向量的类似:

二维索引的句法比嵌套列表更方便:

view 符号的意思是当切分一个数组时实际上没有执行复制。当该数组被修改时,这些改变也会反映到切分得到的结果上。
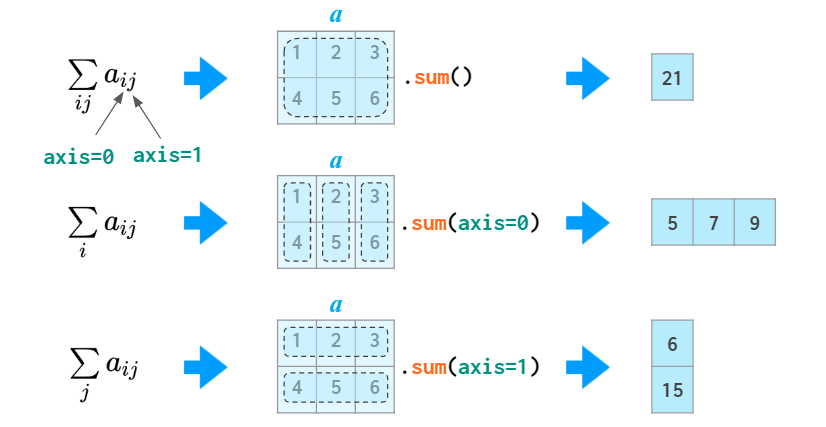
axis 参数
在很多运算中(比如 sum),你需要告诉 NumPy 是在列上还是行上执行运算。为了获取适用于任意维度的通用符号,NumPy 引入了 axis 的概念:事实上,axis 参数的值是相关问题中索引的数量:第一个索引为 axis=0,第二个索引为 axis=1,以此类推。因此在二维情况下,axis=0 是按列计算,axis=1 是按行计算。
矩阵算术运算
除了逐元素执行的常规运算符(比如 +、-、、/、//、*),这里还有一个计算矩阵乘积的 @ 运算符:
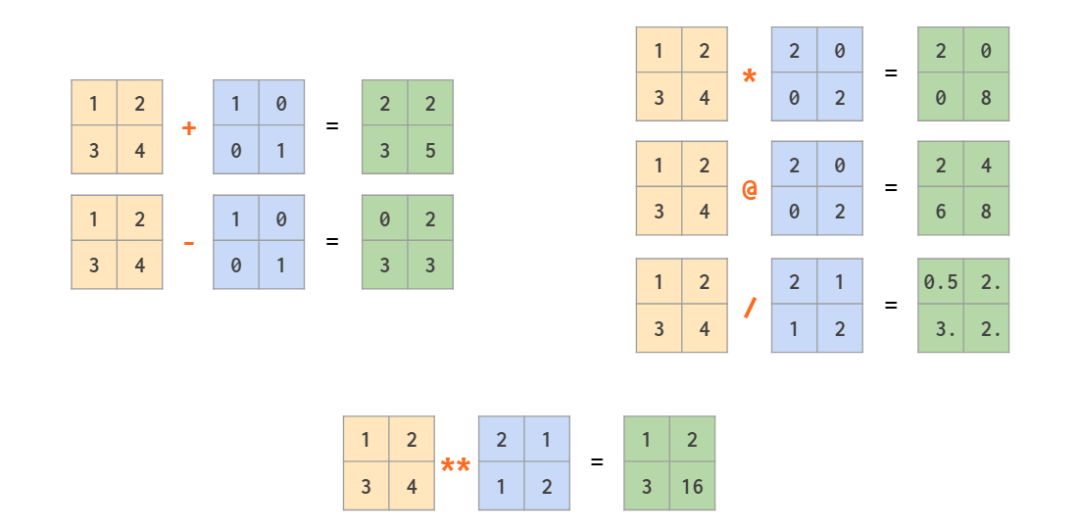
我们已在第一部分介绍过标量到数组的广播,在其基础上进行泛化后,NumPy 支持向量和矩阵的混合运算,甚至两个向量之间的运算:
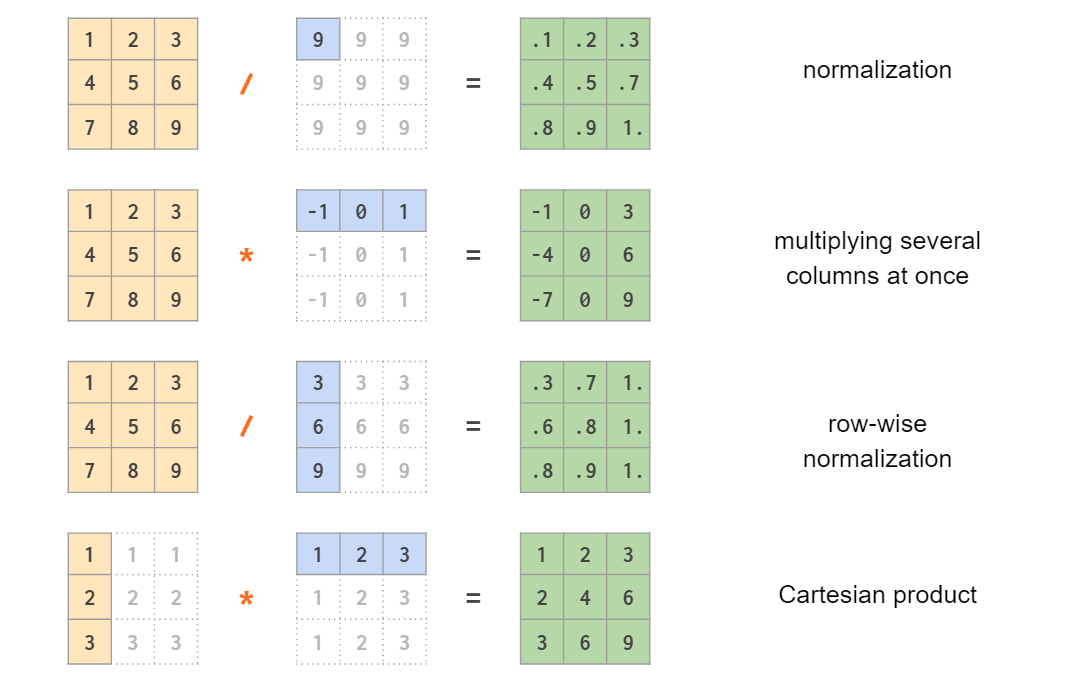
二维数组中的广播
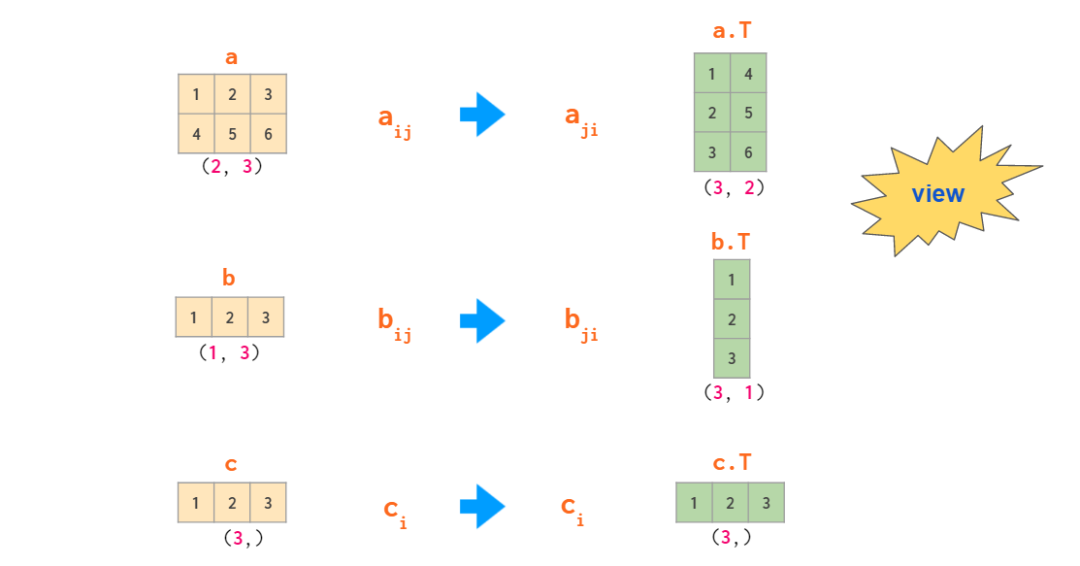
行向量和列向量
正如上面的例子所示,在二维情况下,行向量和列向量的处理方式有所不同。这与具备某类一维数组的 NumPy 实践不同(比如二维数组 a— 的第 j 列 a[:,j] 是一个一维数组)。默认情况下,一维数组会被视为二维运算中的行向量,因此当用一个矩阵乘以一个行向量时,你可以使用形状 (n,) 或 (1, n)——结果是一样的。如果你需要一个列向量,则有多种方法可以基于一维数组得到它,但出人意料的是「转置」不是其中之一。
基于一维数组得到二维数组的运算有两种:使用 reshape 调整形状和使用 newaxis 进行索引:
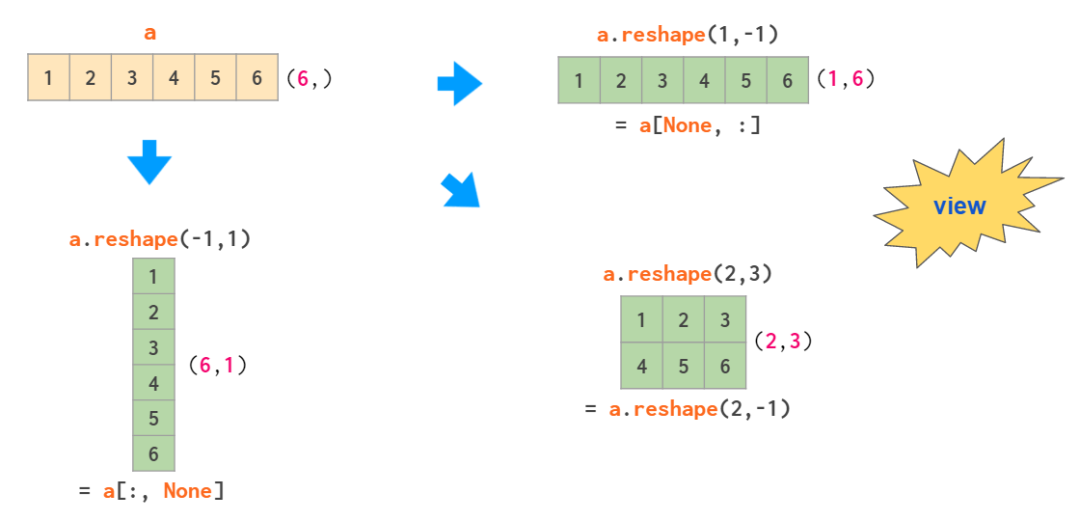
其中 -1 这个参数是告诉 reshape 自动计算其中一个维度大小,方括号中的 None 是用作 np.newaxis 的快捷方式,这会在指定位置添加一个空 axis。
因此,NumPy 共有三类向量:一维向量、二维行向量和二维列向量。下图展示了这三种向量之间的转换方式:
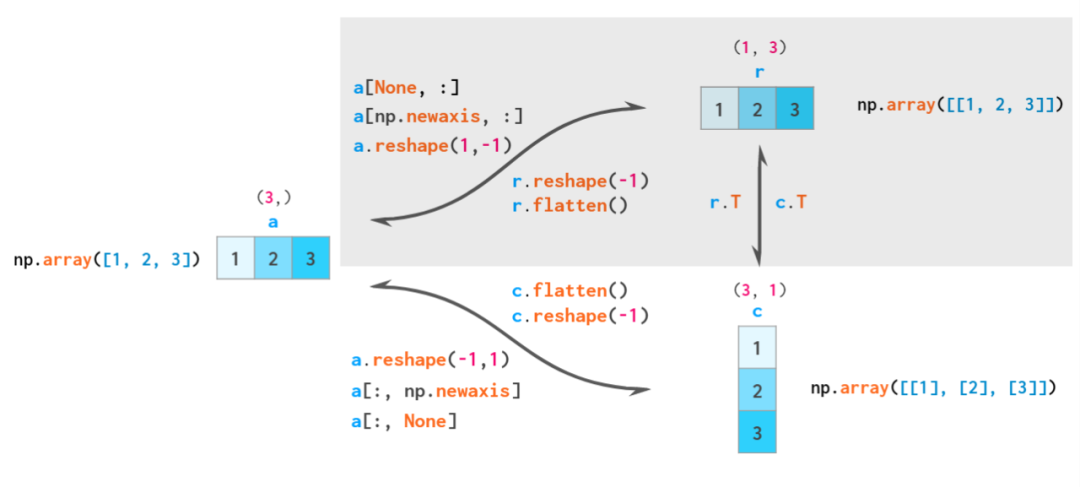
一维向量、二维行向量和二维列向量之间的转换方式。根据广播的原则,一维数组可被隐含地视为二维行向量,因此通常没必要在这两者之间执行转换——因此相应的区域被阴影化处理。
矩阵操作
合并数组的函数主要有两个:
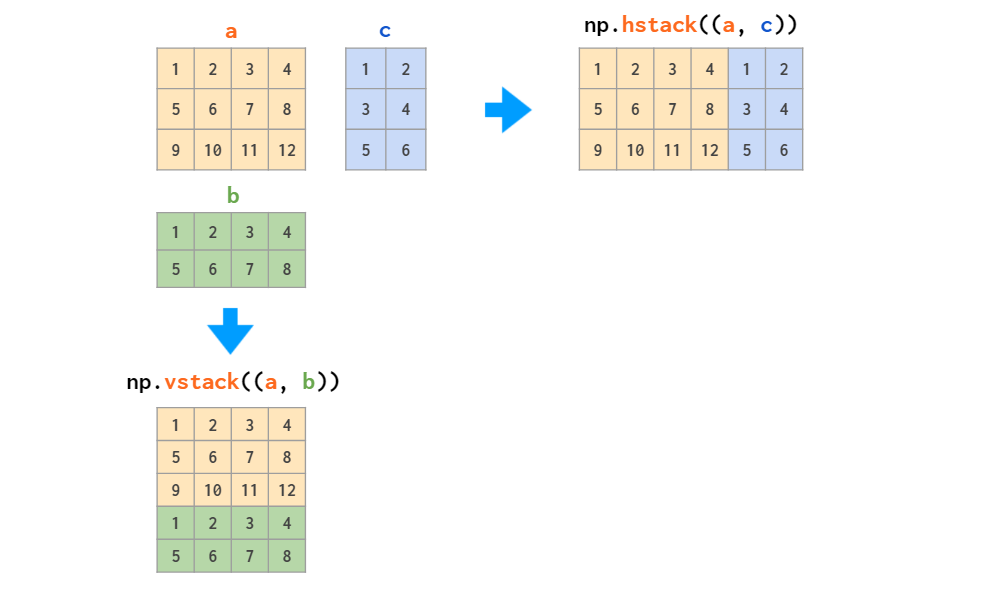
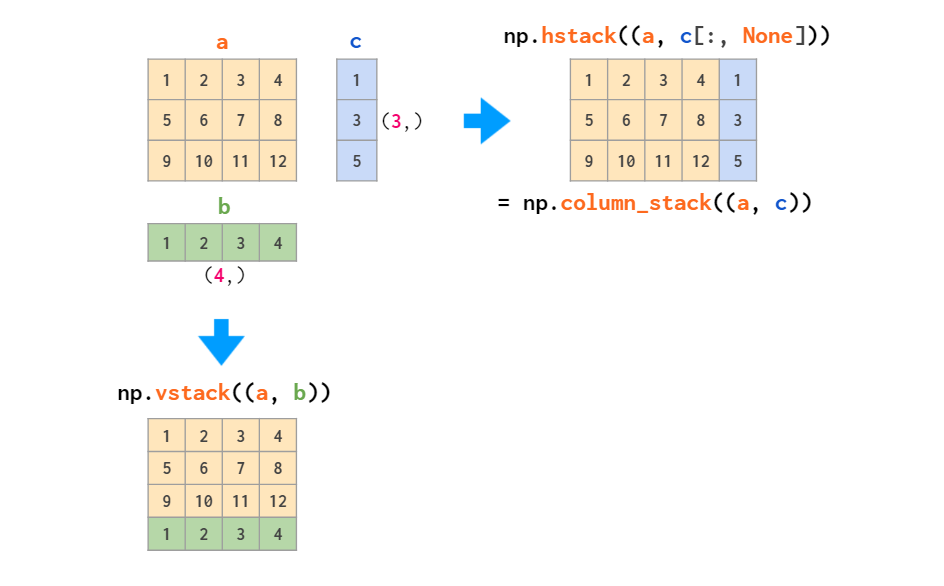
这两个函数适用于只堆叠矩阵或只堆叠向量,但当需要堆叠一维数组和矩阵时,只有 vstack 可以奏效:hstack 会出现维度不匹配的错误,原因如前所述,一维数组会被视为行向量,而不是列向量。针对这个问题,解决方法要么是将其转换为行向量,要么是使用能自动完成这一操作的 column_stack 函数:
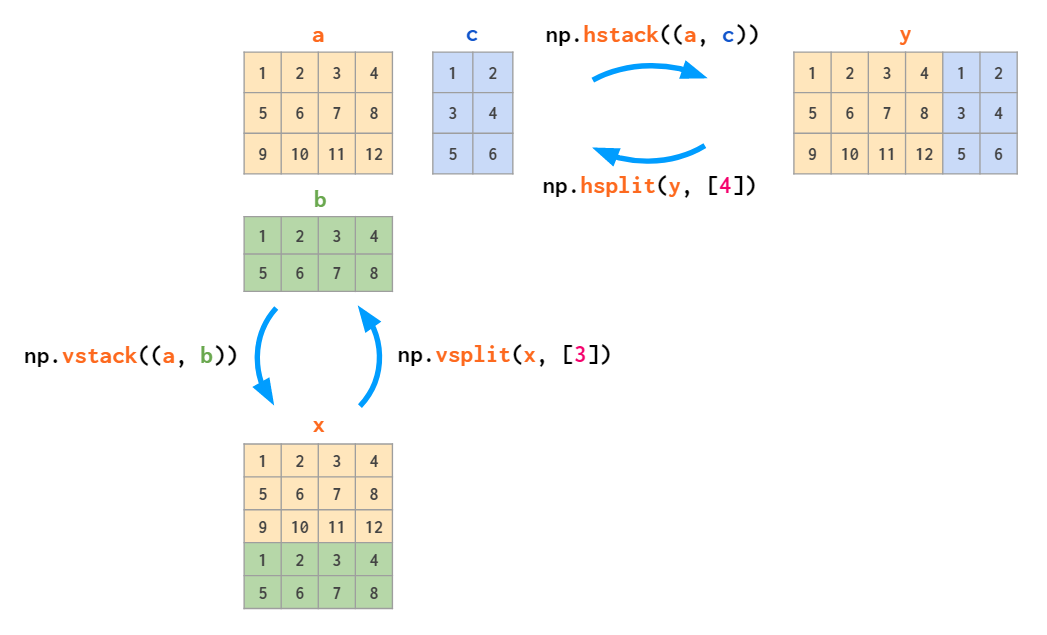
堆叠的逆操作是拆分:
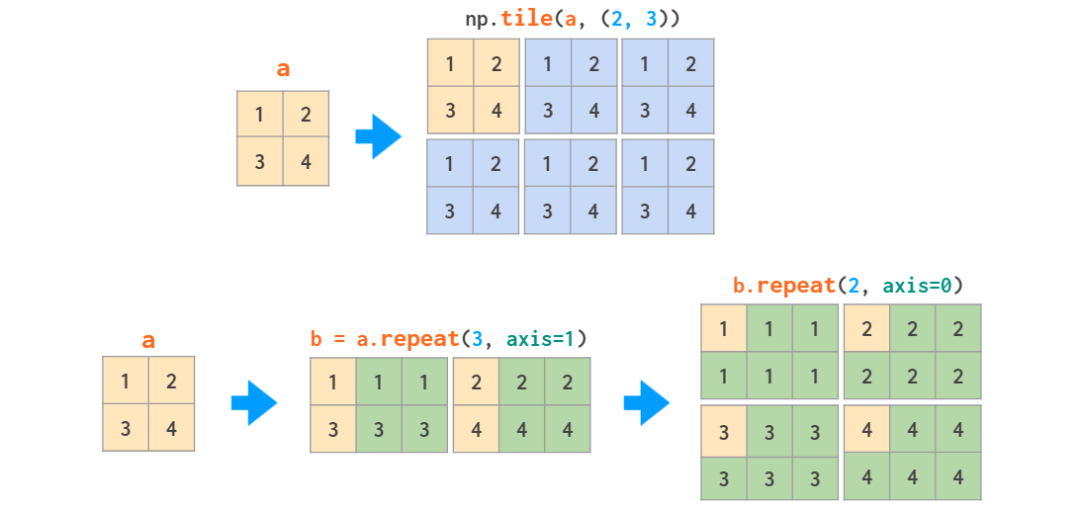
复制矩阵的方法有两种:复制 - 粘贴式的 tile 和分页打印式的 repeat:
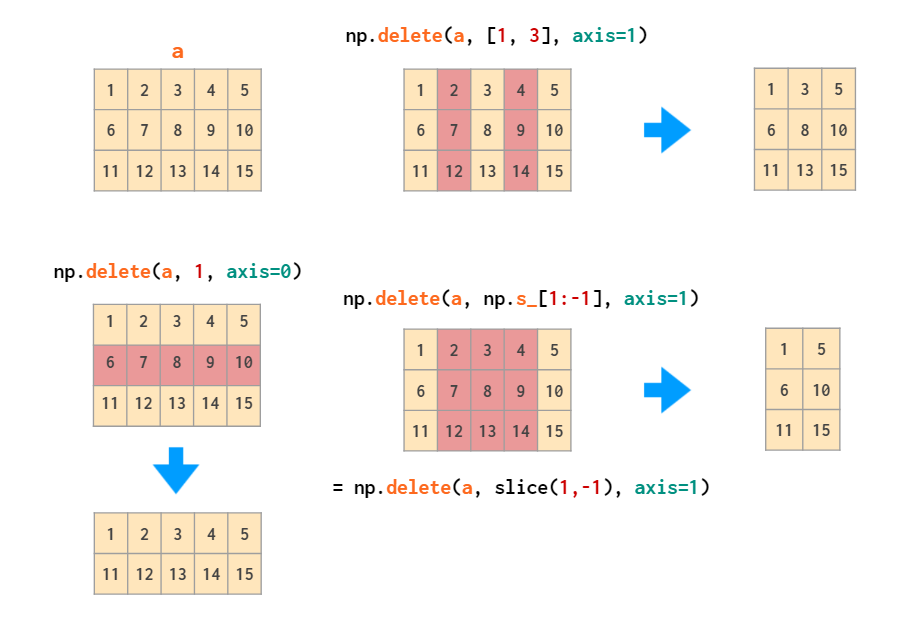
delete 可以删除特定的行和列:
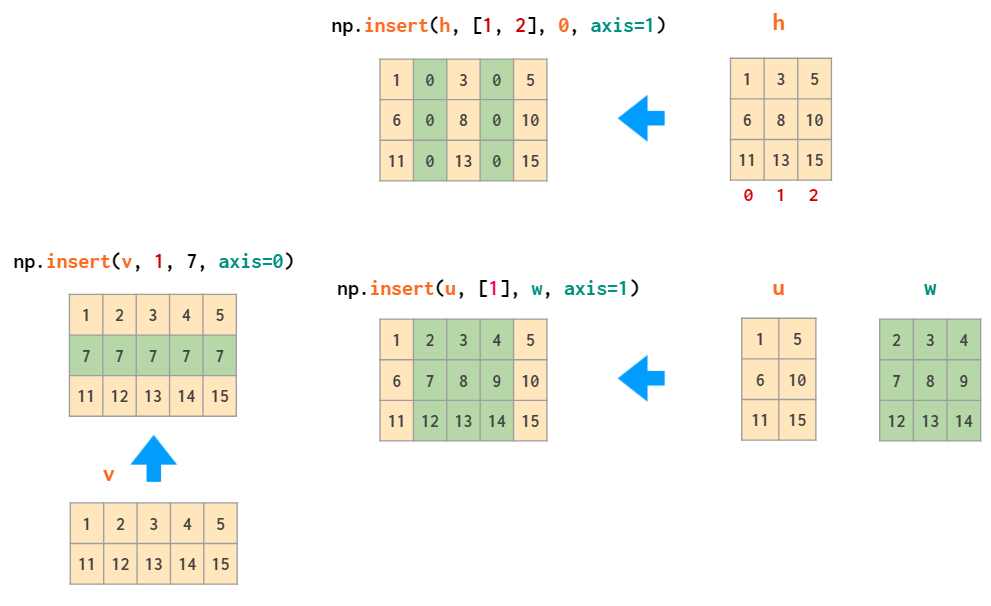
删除的逆操作为插入,即 insert:
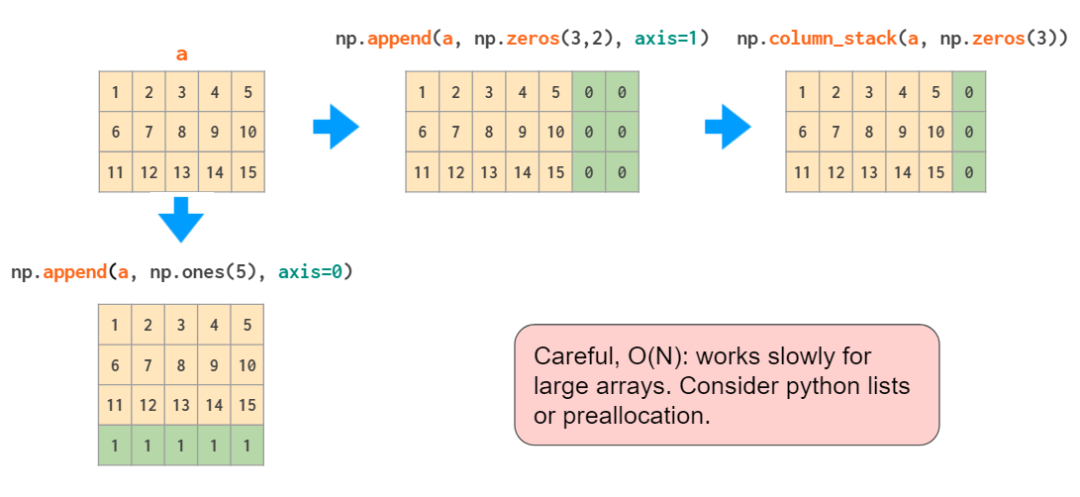
append 函数就像 hstack 一样,不能自动对一维数组执行转置,因此同样地,要么需要改变该向量的形状,要么就需要增加一个维度,或者使用 column_stack:
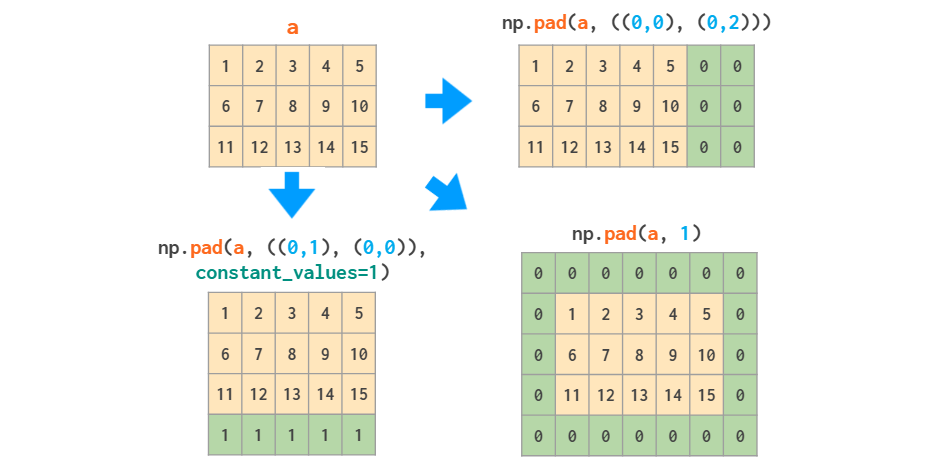
事实上,如果你只需要向数组的边缘添加常量值,那么(稍微复杂的)pad 函数应该就足够了:
网格
广播规则使得我们能更简单地操作网格。假设你有如下矩阵(但非常大):

使用 C 和使用 Python 创建矩阵的对比
这两种方法较慢,因为它们会使用 Python 循环。为了解决这样的问题,MATLAB 的方式是创建一个网格:
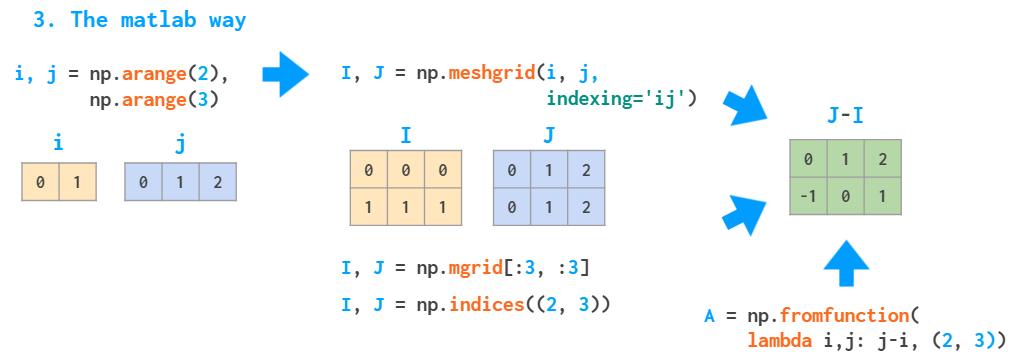
使用 MATLAB 创建网格的示意图
使用如上提供的参数 I 和 J,meshgrid 函数接受任意的索引集合作为输入,mgrid 只是切分,indices 只能生成完整的索引范围,fromfunction 只会调用所提供的函数一次。
但实际上,NumPy 中还有一种更好的方法。我们没必要将内存耗在整个 I 和 J 矩阵上。存储形状合适的向量就足够了,广播规则可以完成其余工作。

使用 NumPy 创建网格的示意图
没有 indexing=’ij’ 参数,meshgrid 会改变这些参数的顺序:J, I= np.meshgrid(j, i)——这是一种 xy 模式,对可视化 3D 图表很有用。
除了在二维或三维网格上初始化函数,网格也可用于索引数组:

使用 meshgrid 索引数组,也适用于稀疏网格。
获取矩阵统计数据
和 sum 一样,min、max、argmin、argmax、mean、std、var 等所有其它统计函数都支持 axis 参数并能据此完成统计计算:
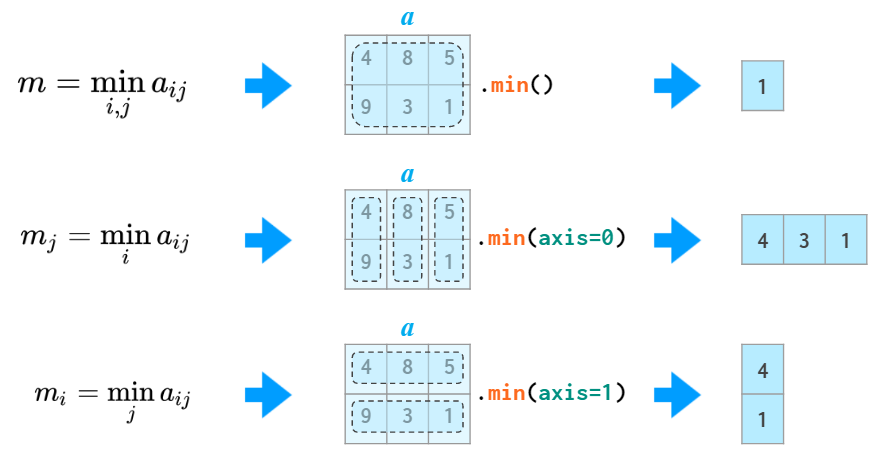
三个统计函数示例,为了避免与 Python 的 min 冲突,NumPy 中对应的函数名为 np.amin。
用于二维及更高维的 argmin 和 argmax 函数会返回最小和最大值的第一个实例,在返回展开的索引上有点麻烦。为了将其转换成两个坐标,需要使用 unravel_index 函数:
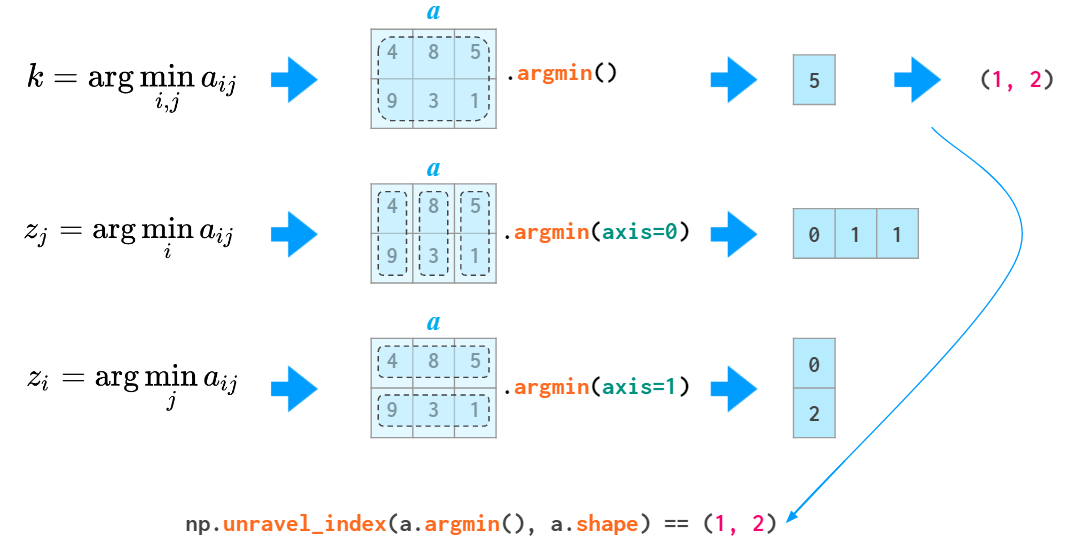
使用 unravel_index 函数的示例
all 和 any 函数也支持 axis 参数:
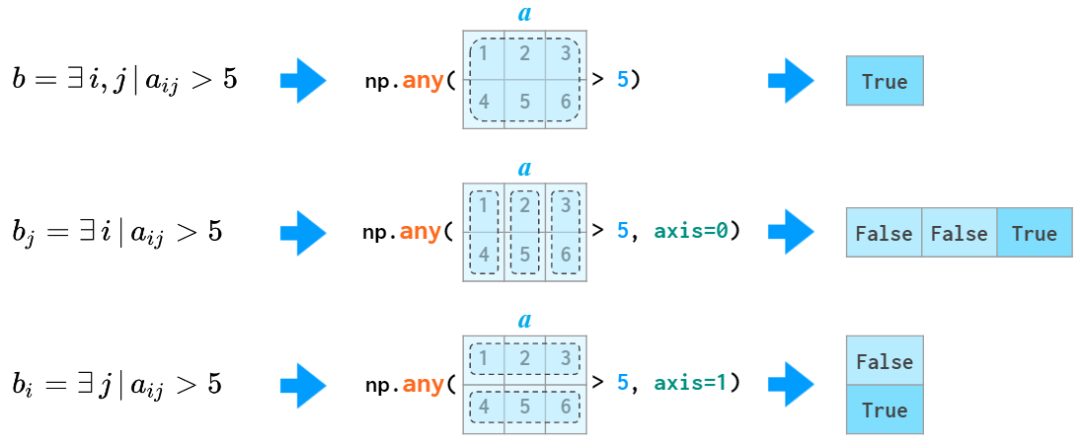
使用 all 和 any 函数的示例
矩阵排序
axis 参数虽然对上面列出的函数很有用,但对排序毫无用处:

使用 Python 列表和 NumPy 数组执行排序的比较
这通常不是你在排序矩阵或电子表格时希望看到的结果:axis 根本不能替代 key 参数。但幸运的是,NumPy 提供了一些支持按列排序的辅助函数——或有需要的话可按多列排序:
1. a[a[:,0].argsort()] 可按第一列对数组排序:
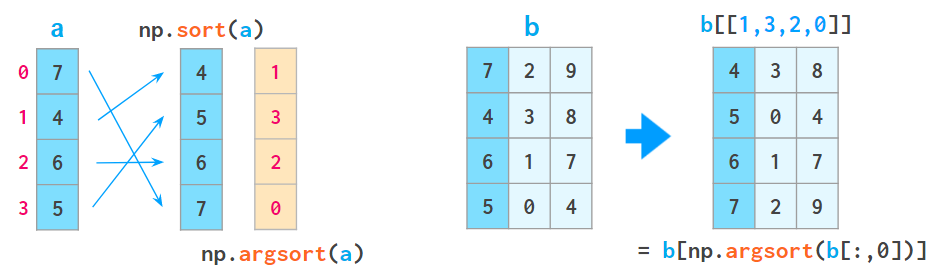
这里 argsort 会返回原数组排序后的索引的数组。
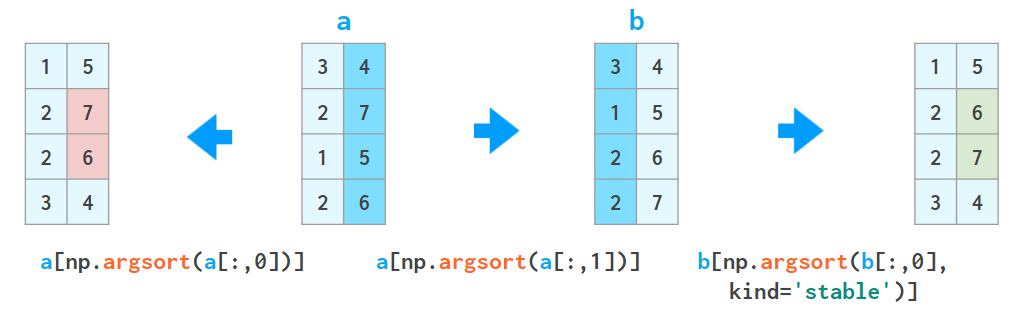
这个技巧可以重复,但必须谨慎,别让下一次排序扰乱上一次排序的结果:
a = a[a[:,2].argsort()]
a = a[a[:,1].argsort(kind='stable')]
a = a[a[:,0].argsort(kind='stable')]
2. lexsort 函数能使用上述方式根据所有列进行排序,但它总是按行执行,而且所要排序的行的顺序是反向的(即自下而上),因此使用它时会有些不自然,比如
- a[np.lexsort(np.flipud(a[2,5].T))] 会首先根据第 2 列排序,然后(当第 2 列的值相等时)再根据第 5 列排序。
– a[np.lexsort(np.flipud(a.T))] 会从左向右根据所有列排序。
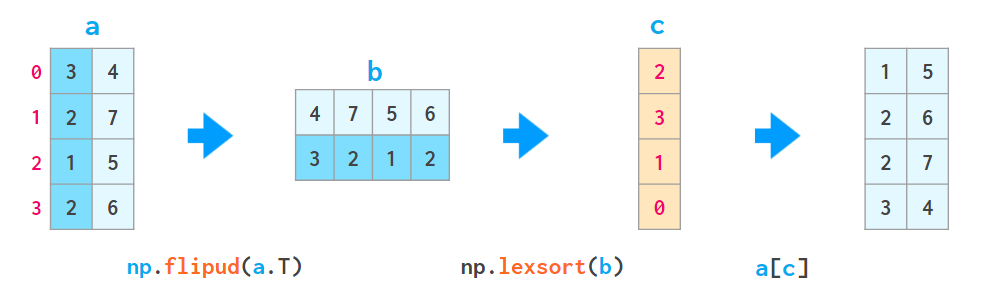
这里,flipud 会沿上下方向翻转该矩阵(准确地说是 axis=0 方向,与 a[::-1,...] 一样,其中三个点表示「所有其它维度」,因此翻转这个一维数组的是突然的 flipud,而不是 fliplr。
3. sort 还有一个 order 参数,但如果一开始是普通的(非结构化)数组,它执行起来既不快,也不容易使用。
4. 在 pandas 中执行它可能是更好的选择,因为在 pandas 中,该特定运算的可读性要高得多,也不那么容易出错:
– pd.DataFrame(a).sort_values(by=[2,5]).to_numpy() 会先根据第 2 列排序,然后根据第 5 列排序。
– pd.DataFrame(a).sort_values().to_numpy() 会从左向右根据所有列排序。
三维及更高维
当你通过调整一维向量的形状或转换嵌套的 Python 列表来创建 3D 数组时,索引的含义是 (z,y,x)。第一个索引是平面的数量,然后是在该平面上的坐标:
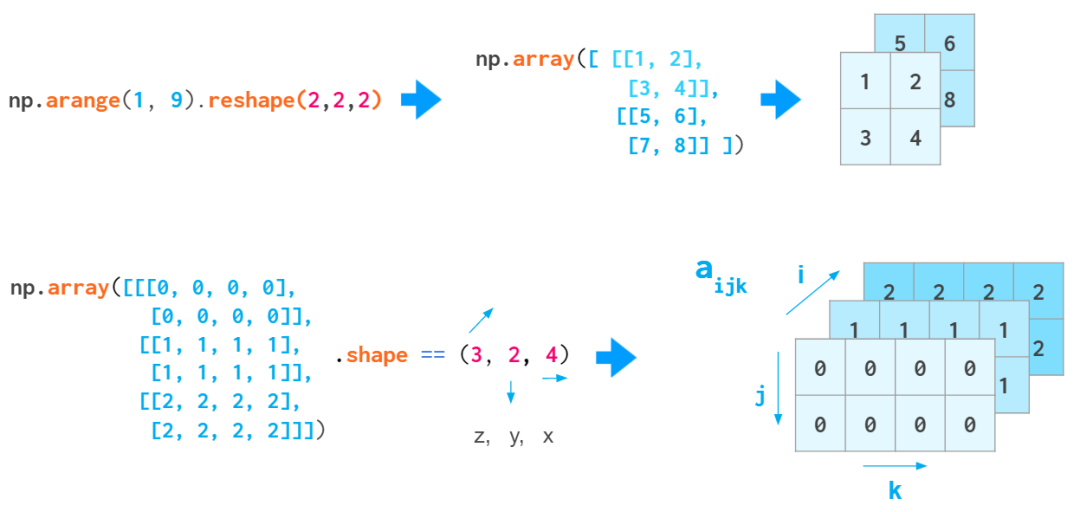
展示 (z,y,x) 顺序的示意图
这个索引顺序很方便,举个例子,它可用于保存一些灰度图像:a[i] 是索引第 i 张图像的快捷方式。
但这个索引顺序不是通用的。当操作 RGB 图像时,通常会使用 (y,x,z) 顺序:首先是两个像素坐标,最后一个是颜色坐标(Matplotlib 中是 RGB,OpenCV 中是 BGR):
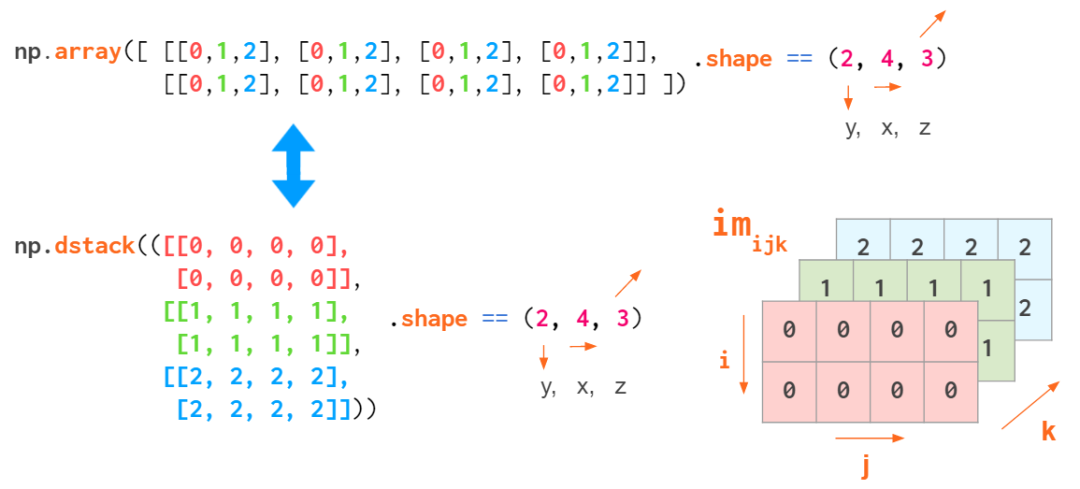
展示 (y,x,z) 顺序的示意图
这样,我们就能很方便地索引特定的像素:a[i,j] 能提供 (i,j) 位置的 RGB 元组。
因此,创建几何形状的实际命令取决于你所在领域的惯例:
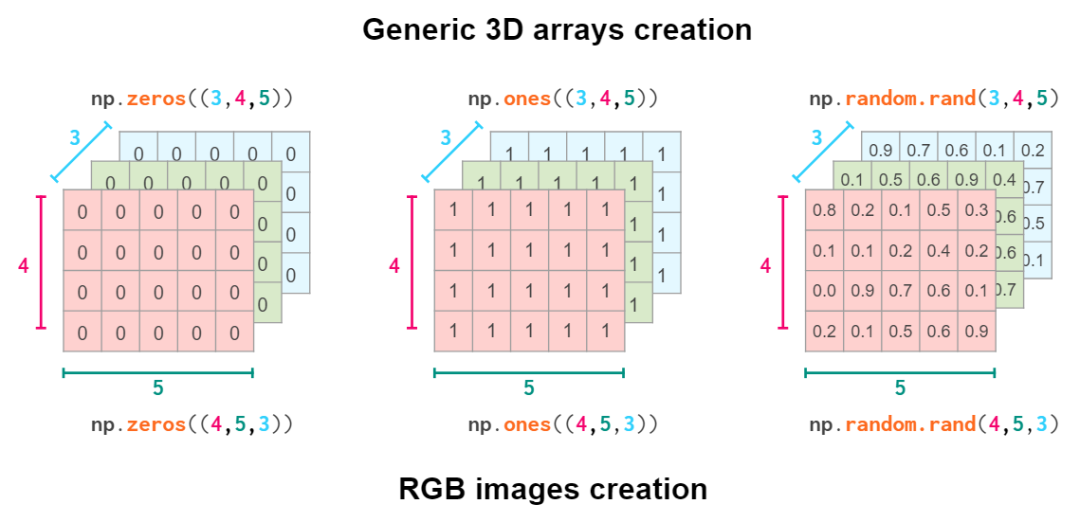
创建一般的三维数组和 RGB 图像
很显然,hstack、vstack、dstack 这些函数不支持这些惯例。它们硬编码了 (y,x,z) 的索引顺序,即 RGB 图像的顺序:
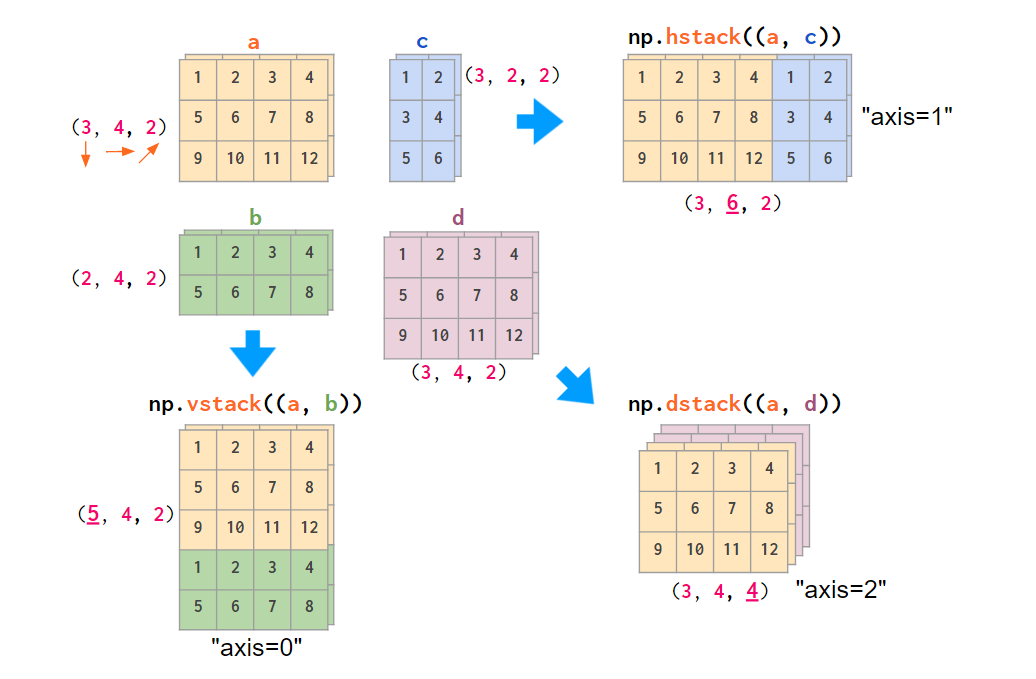
NumPy 使用 (y,x,z) 顺序的示意图,堆叠 RGB 图像(这里仅有两种颜色)
如果你的数据布局不同,使用 concatenate 命令来堆叠图像会更方便一些,向一个 axis 参数输入明确的索引数值:
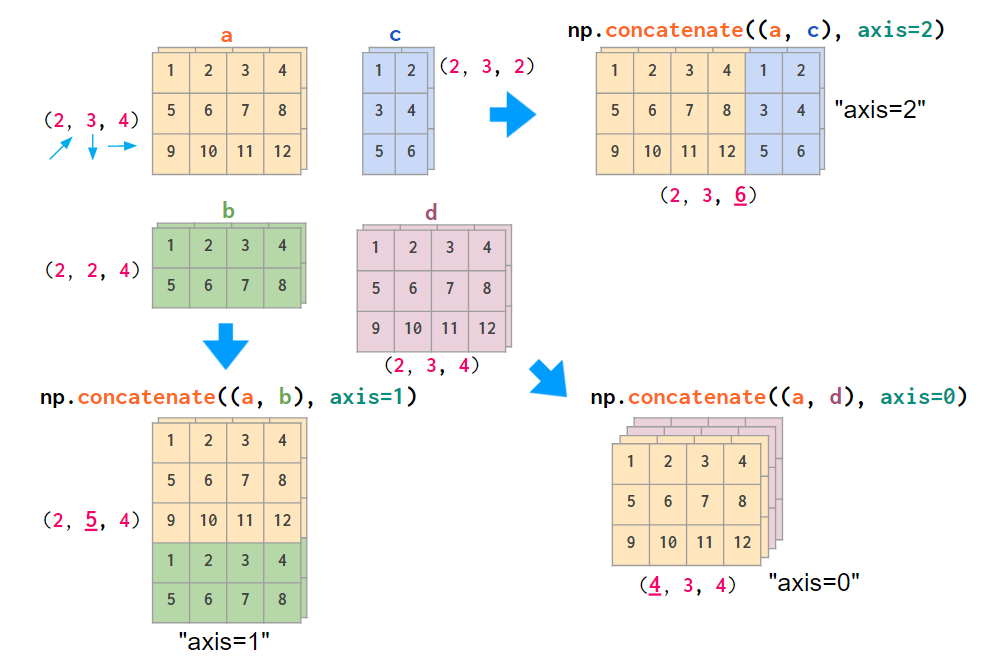
堆叠一般三维数组
如果你不习惯思考 axis 数,你可以将该数组转换成 hstack 等函数中硬编码的形式:
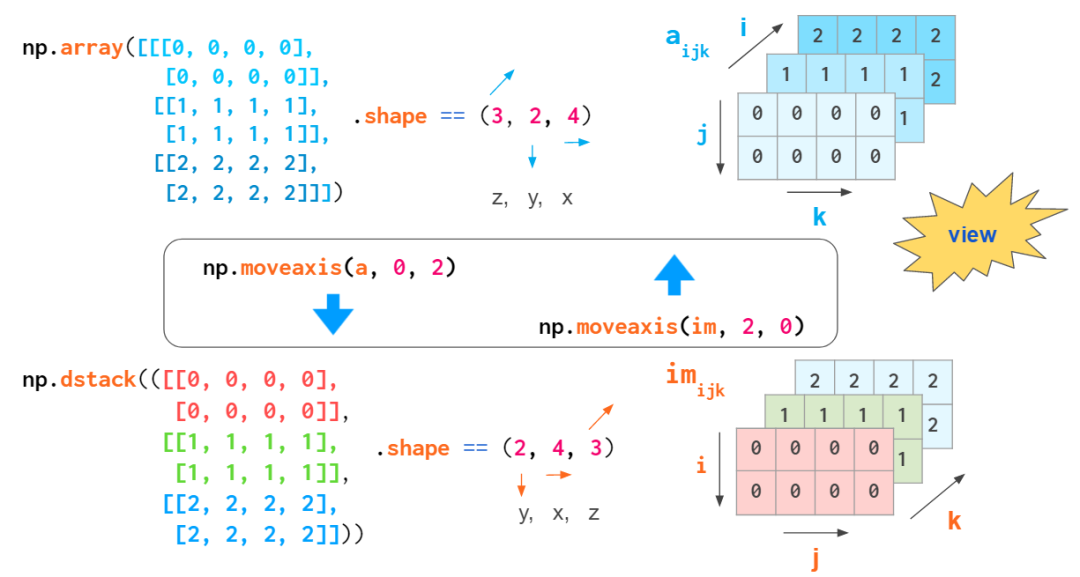
将数组转换为 hstack 中硬编码的形式的示意图
这种转换的成本很低:不会执行实际的复制,只是执行过程中混合索引的顺序。
另一种可以混合索引顺序的运算是数组转置。了解它可能会让你更加熟悉三维数组。根据你决定使用的 axis 顺序的不同,转置数组所有平面的实际命令会有所不同:对于一般数组,它会交换索引 1 和 2,对 RGB 图像而言是 0 和 1:
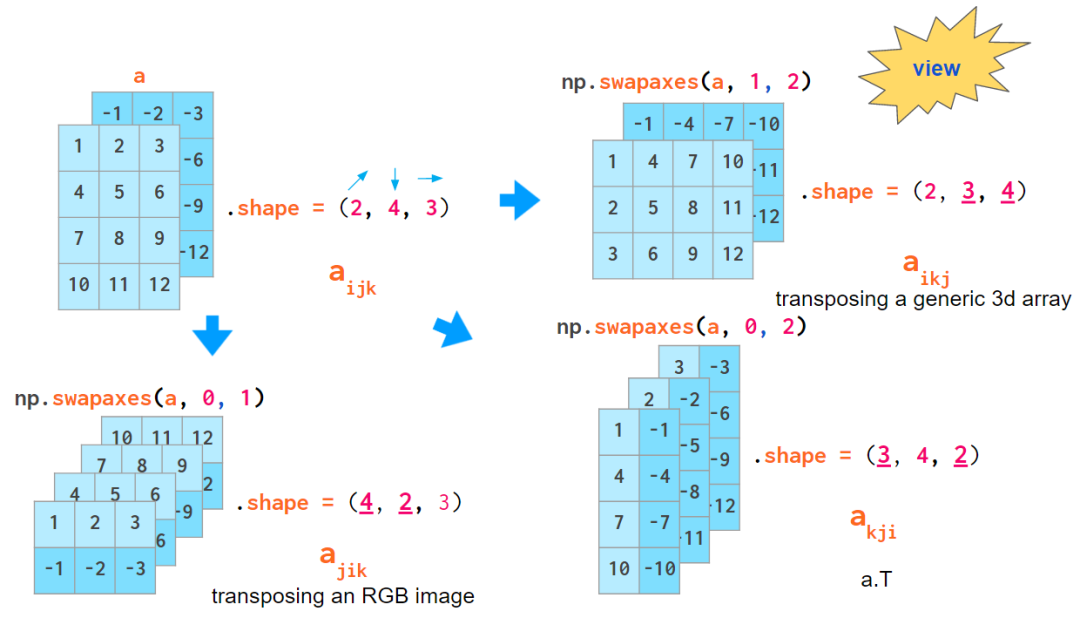
转置一个三维数据的所有平面的命令
不过有趣的是,transpose 的默认 axes 参数(以及仅有的 a.T 运算模式)会调转索引顺序的方向,这与上述两个索引顺序惯例都不相符。
最后,还有一个函数能避免你在处理多维数组时使用太多训练,还能让你的代码更简洁——einsum(爱因斯坦求和):
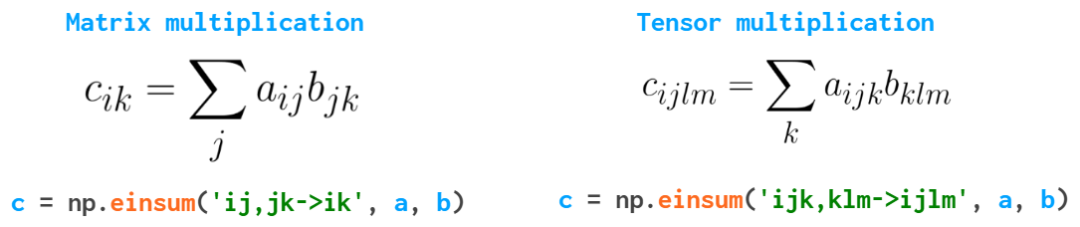
它会沿重复的索引对数组求和。在这个特定的例子中,np.tensordot(a, b, axis=1) 足以应对这两种情况,但在更复杂的情况中,einsum 的速度可能更快,而且通常也更容易读写——只要你理解其背后的逻辑。
如果你希望测试你的 NumPy 技能,GitHub 有 100 道相当困难的练习题:https://github.com/rougier/numpy-100。
你最喜欢的 NumPy 功能是什么?可以在留言区分享!
原文链接:https://medium.com/better-programming/numpy-illustrated-the-visual-guide-to-numpy-3b1d4976de1d
· 推荐阅读 ·