
详解卷积中的Winograd加速算法
❝1. 为什么会引入WinoGrad?「GiantPandaCV导语」:这篇文章为大家介绍一下用来加速卷积运算的WinoGrad算法的原理,工程实现以及相关优化思路,如果你对卷积加速算法感兴趣可以看看这篇文章。算法的完整实现请到MsnhNet的github仓库查看,地址为:https://github.com/msnh2012/Msnhnet
❞
做过ACM/OI的朋友大家应该对FFT并不陌生,我们知道对于两个序列的乘法通过FFT可以从原始O(n^2)复杂度变成O(nlogn),所以我们就会想着FFT这个算法是否可以应用到我们计算卷积中来呢?当然是可以的,但是FFT的计算有个问题哦,会引入复数。而移动端是不好处理复数的,对于小卷积核可能减少的计算量和复数运算带来的降速效果是不好说谁会主导的。所以在这种情况下,针对卷积的WinoGrad算法出现了,它不仅可以类似FFT一样降低计算量,它还不会引入复数,使得卷积的运算加速成为了可能。因此,本文尝试从工程实现的角度来看一下WinoGrad,希望对从事算法加速的小伙伴有一些帮助。
2. 为什么会有这篇文章?最近尝试给MsnhNet做卷积的WinoGrad实现,然后开始了解这个算法,并尝试参考着NCNN来理解和动手写一下。参考了多篇优秀的讲解文章和NCNN源码,感觉算是对这个算法有了较为清楚的认识,这篇文章就记录一下我在实现并且步长为的WinoGrad卷积时的一些理解。这篇文章的重点是WinoGrad卷积的实现,关于WinoGrad卷积里面的变化矩阵如何推导可以看梁德澎作者的文章:详解Winograd变换矩阵生成原理 (听说后续他会做个视频来仔细讲讲QAQ),现在就假设我们知道了WinoGrad的几个变换矩阵。如果你不知道也没关系,因为有一个Python工具包可以直接帮我们计算,地址为:https://github.com/andravin/wincnn 。然后现在我们就要用拿到的这几个矩阵来实现WinoGrad算法,听起来比较简单,但我们还是得一步步理清楚是不。
WinoGrad算法起源于1980年,是Shmuel Winograd提出用来减少FIR滤波器计算量的一个算法。它指出,对于输出个数为,参数个数为的FIR滤波器,不需要次乘法计算,而只需要次乘法计算即可。
下面是一个经典例子,以1维卷积为例,输入信号,卷积核,则卷积可以写成如下矩阵乘法形式:
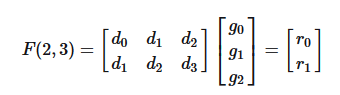 式子1
式子1如果这个计算过程使用普通的矩阵乘法,则一共需要「6次乘法和4次加法」 。
但是,我们仔细观察一下,卷积运算中输入信号转换得到的矩阵不是任意矩阵,其有规律的分布着大量的重复元素,例如第一行的和,卷积转换成的矩阵乘法比一般乘法的问题域更小,所以这就让优化存为了可能。
然后WinoGrad的做法就是:
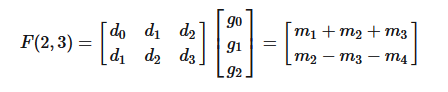 式子2
式子2其中,
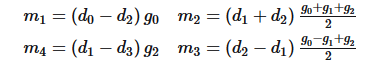 等式3
等式3我们知道,在CNN的推理阶段,卷积核上的元素是固定的,所以上式中和相关的式子可以提前算好,在预测阶段只用计算一次,可以忽略。所以这里一共需要「4次乘法加4次加法」。
相比于普通的矩阵乘法,使用WinoGrad算法之后乘法次数减少了,这样就可以达到加速的目的了。
这个例子实际上是「1D的WinoGrad算法」,我们将上面的计算过程写成矩阵的形式如下:
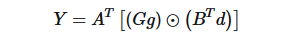 式子4
式子4其中,表示element-wise multiplication(Hadamard product)对应位置相乘。其中,
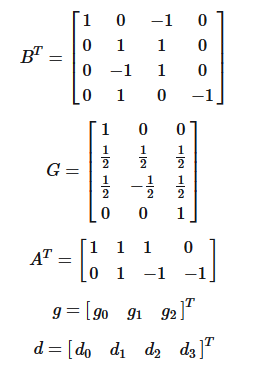 相关矩阵解释
相关矩阵解释- :表示卷积核
- :表示输入信号
- :卷积核变换矩阵,尺寸为
- :输入变换矩阵,尺寸
- :输出变换矩阵,尺寸
所以整个计算过程可以分为4步:
- 输入变换
- 卷积核变换
- 外积
- 输出变换
然后我们将1D的WinoGrad扩展到2D,就可以实现卷积的加速了,那么如何从1维扩展到2维呢?公式如下:
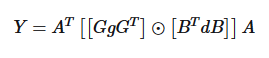 式子5
式子5其中,为的卷积核,为的图像块,我们把上面的扩展到,先写成矩阵乘法的方式:
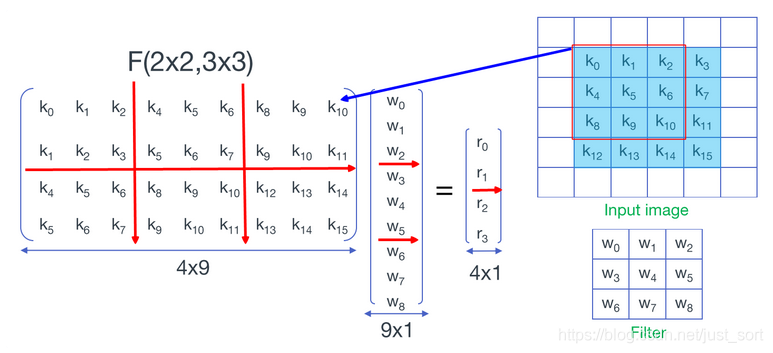 F(2x2,3x3) 图片来自https://www.cnblogs.com/shine-lee/p/10906535.html
F(2x2,3x3) 图片来自https://www.cnblogs.com/shine-lee/p/10906535.html上图表示我们将卷积核的元素拉成了一列,将输入信号每个滑动窗口中的元素拉成了一行。注意图中红线分成的矩阵块,每个矩阵块中重复元素的位置与一维相同,即:
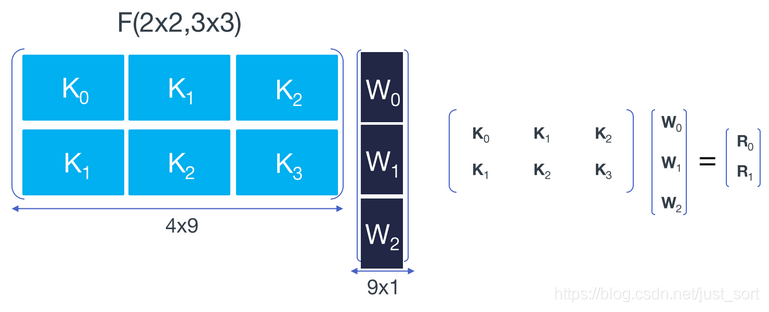 二维和一维的WinoGrad矩阵关系
二维和一维的WinoGrad矩阵关系然后,令,即图像窗口中的第0行元素,然后表示第行,,然后可以推导:
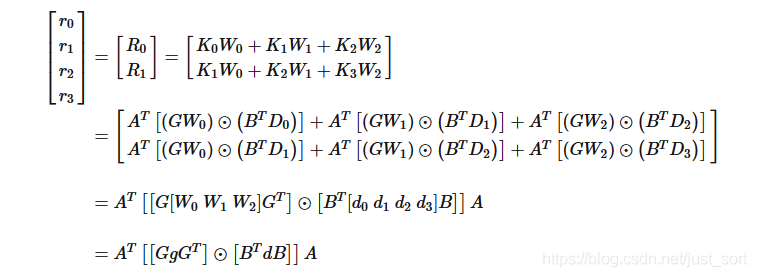 2D WinoGrad矩阵形式计算推导
2D WinoGrad矩阵形式计算推导在上面的推导中,表示长度为4的和长度为的卷积结果,结果为长度为2的列向量,其中和均为长度为4的列向量。
进一步,可以看成3对长度为4的列向量两两对应位置相乘再相加,结果为长度为4的列向量,也可以看成是4组长度为3的行向量的点积运算。
同样,也是3对长度为4的列向量的内积运算。
然后类似1D WinoGrad算法,我们考虑两者的重叠部分和,刚好对应1D WinoGrad中的每一行在的对应行上进行1维卷积,基于上面推导的1D WinoGrad公式,行向量的卷积只需要将所有左乘的变换矩阵转置后变成右乘即可。
然后上面的推导就做完了。
下图表示2D WinoGrad的示意图:
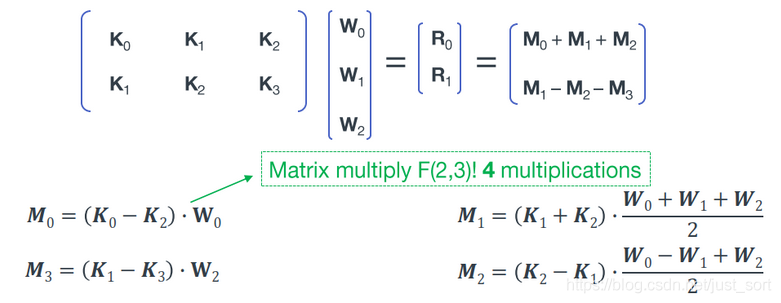 2D WinoGrad示意图
2D WinoGrad示意图这个时候,WinoGrad算法的乘法次数为,而如果直接卷积乘法次数为,「降低了2.25倍的乘法计算复杂度」。
4. 从工程角度来看WinoGrad下面我们就从一个实际例子来说,如何利用WinoGrad来实现并且步长为1的卷积运算。基于上面介绍的2D WinoGrad的原理,我们现在只需要分4步即可实现WnoGrad算法:
- 第一步就是对输入卷积核的变换:
- 第二步就是对输入数据的变换:
- 第三步就是对M矩阵的计算:
- 最后一步就是结果的计算:
接下来我们就以WinoGrad实现并且步长为1的卷积计算为例子,来理解一下WinoGrad的工程实现。
4.1 对输入卷积核进行变换
这一步就是对卷积核进行变化,公式为:,其中表示输出通道标号,表示输入通道标号,一个对应卷积核的一个。由于我们要实现的是,因此是一个的矩阵,我们不难写出这部分代码(其中,矩阵可以通过https://github.com/andravin/wincnn 这个工具进行计算):
// 矩阵G
const float ktm[8][3] = {
{1.0f, 0.0f, 0.0f},
{-2.0f / 9, -2.0f / 9, -2.0f / 9},
{-2.0f / 9, 2.0f / 9, -2.0f / 9},
{1.0f / 90, 1.0f / 45, 2.0f / 45},
{1.0f / 90, -1.0f / 45, 2.0f / 45},
{1.0f / 45, 1.0f / 90, 1.0f / 180},
{1.0f / 45, -1.0f / 90, 1.0f / 180},
{0.0f, 0.0f, 1.0f}
};
const int kernelTmSize = inChannel * 8 * 8;
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int outc = 0; outc < outChannel; outc++){
for(int inc = 0; inc < inChannel; inc++){
const float* kernel0 = (const float*)kernel + outc * inChannel * 9 + inc * 9;
float *kernel_tm0 = kernel_tm + outc * kernelTmSize + inc * 64;
//需要变换的卷积核
const float* k0 = kernel0;
const float* k1 = kernel0 + 3;
const float* k2 = kernel0 + 6;
float tmpG[8][3]; // tmp = G*g
for(int i = 0; i < 8; i++){
tmpG[i][0] = k0[0] * ktm[i][0] + k0[1] * ktm[i][1] + k0[2] * ktm[i][2];
tmpG[i][1] = k1[0] * ktm[i][0] + k1[1] * ktm[i][1] + k1[2] * ktm[i][2];
tmpG[i][2] = k2[0] * ktm[i][0] + k2[1] * ktm[i][1] + k2[2] * ktm[i][2];
}
//U = kernel_tm0 = G*g*G^T
//[8*3] x [3*8]
for(int i = 0; i < 8; i++){
float *tmpPtr = &tmpG[i][0];
for(int j = 0; j < 8; j++){
kernel_tm0[i * 8 + j] = tmpPtr[0] * ktm[j][0] + tmpPtr[1] * ktm[j][1] + tmpPtr[2] * ktm[j][2];
}
}
}
}
通过这段代码,所有的卷积核都被转换成了U,存放在了kernel_tm上,一行代表一个,kernel_tm的内存排布如下图所示:
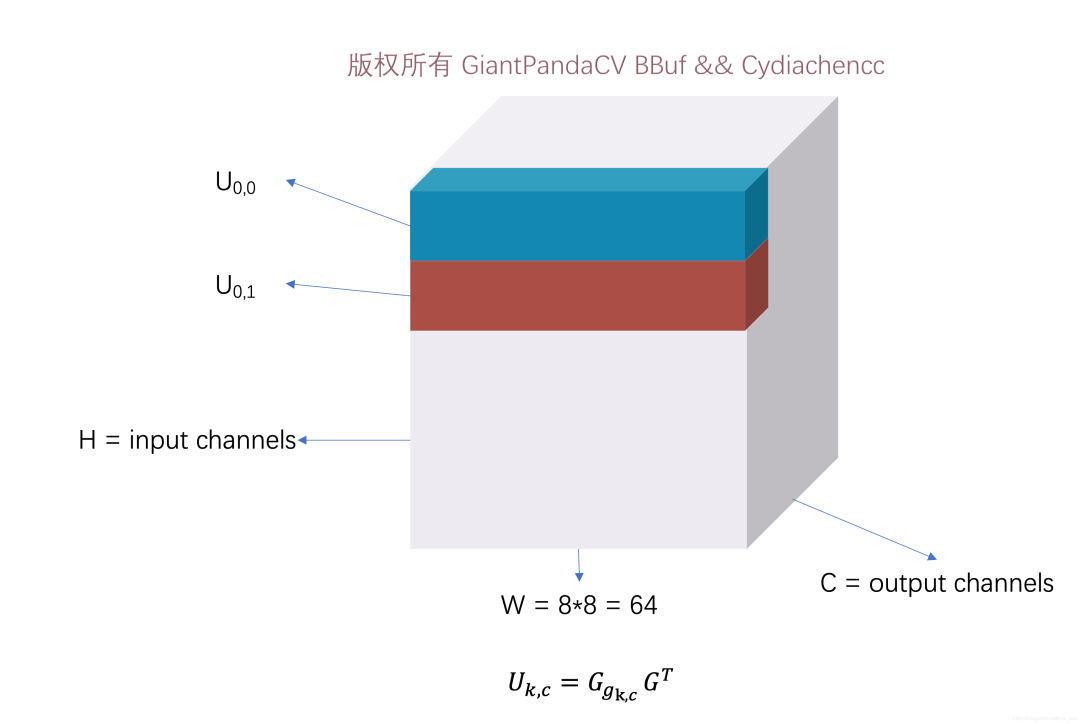 U_{k,c}的内存排布
U_{k,c}的内存排布其中W=64的原因是因为F(6x6,3x3)需要每一个输入图像块(tile)的大小为,权重块也对应,这样才可以做卷积运算(eltwise_mult)。
然后上次我们讲到数据Pack的优势详解Im2Col+Pack+Sgemm策略更好的优化卷积运算,所以这里仍然使用NCNN的Pack策略来获得更好的访存,即将上面的kernel_tm进行一次重排,将维度全部压到维度上,另外再对维度做一个额外的4倍压缩,来获得更好的访存。
将H的维度全部压到维度上示意图:
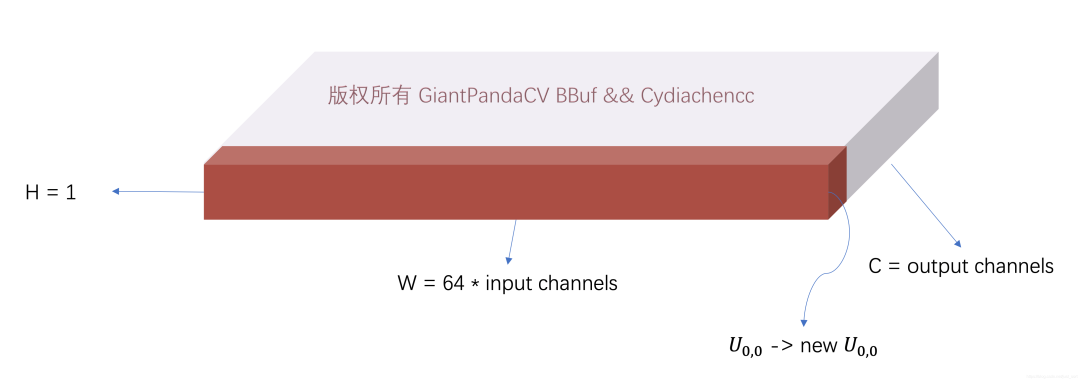 将kernel_tm的H维度全部压到W维度变成一个扁平的Blob
将kernel_tm的H维度全部压到W维度变成一个扁平的Blob然后在这个基础上,将C维度进行进一步压缩,这个时候还需要注意的是对于每一个输出通道,我们在这个平面上是同时拿出了2行,也就是拿出了128个数据,然后进行交织排列,最后获得kernel_tm2。这里以输出通道的前4个为例,即刚好处理8个U矩阵之后结果矩阵kernel_tm2应该是长什么样子,如下图所示:
![Pack策略之后的矩阵kernel_tm2就长这个样子
这部分的代码实现如下:
int nnOutchannel = outChannel >> 2;
int remainOutChannel = nnOutchannel << 2;
int packOutChannel = nnOutchannel + (outChannel % 4 + 3) / 4;
int packOutH = 1;
int packOutW = (8 * 8 * inChannel * 4);
//float *kernel_tm2 = new float[packOutChannel * packOutH * packOutW];
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int cc = 0; cc < nnOutchannel; cc++){
int c = cc << 2;
float *ktm2 = kernel_tm2 + cc * packOutH * packOutW;
const float *kernel0_tm = kernel_tm + c * kernelTmSize;
const float *kernel1_tm = kernel_tm + (c + 1) * kernelTmSize;
const float *kernel2_tm = kernel_tm + (c + 2) * kernelTmSize;
const float *kernel3_tm = kernel_tm + (c + 3) * kernelTmSize;
int q = 0;
for(; q + 1 < inChannel; q += 2){
const float *k00 = kernel0_tm + q * 64;
const float *k01 = kernel0_tm + (q + 1) * 64;
const float *k10 = kernel1_tm + q * 64;
const float *k11 = kernel1_tm + (q + 1) * 64;
const float *k20 = kernel2_tm + q * 64;
const float *k21 = kernel2_tm + (q + 1) * 64;
const float *k30 = kernel3_tm + q * 64;
const float *k31 = kernel3_tm + (q + 1) * 64;
for(int i = 0; i < 16; i++){
for(int j = 0; j < 4; j++){
ktm2[0 + j] = k00[j];
ktm2[4 + j] = k01[j];
ktm2[8 + j] = k10[j];
ktm2[12 + j] = k11[j];
ktm2[16 + j] = k20[j];
ktm2[20 + j] = k21[j];
ktm2[24 + j] = k30[j];
ktm2[28 + j] = k31[j];
}
k00 += 4;
k01 += 4;
k10 += 4;
k11 += 4;
k20 += 4;
k21 += 4;
k30 += 4;
k31 += 4;
ktm2 += 32;
}
}
//inChannel方向的拖尾部分
for(; q < inChannel; q++){
const float *k00 = kernel0_tm + q * 64;
const float *k10 = kernel1_tm + q * 64;
const float *k20 = kernel2_tm + q * 64;
const float *k30 = kernel3_tm + q * 64;
for(int i = 0; i < 16; i++){
for(int j = 0; j < 4; j++){
ktm2[0 + j] = k00[j];
ktm2[4 + j] = k10[j];
ktm2[8 + j] = k20[j];
ktm2[12 + j] = k30[j];
}
k00 += 4;
k10 += 4;
k20 += 4;
k30 += 4;
ktm2 += 16;
}
}
}
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int cc = remainOutChannel; cc < outChannel; cc++){
float *ktm2 = kernel_tm2 + nnOutchannel * packOutH * packOutW + 8 * 8 * inChannel * (cc - remainOutChannel);
const float* kernel0_tm = kernel_tm + cc * kernelTmSize;
int q = 0;
for(; q < inChannel; q++){
const float* k00 = kernel0_tm + q * 64;
for(int i = 0; i < 16; i++){
for(int j = 0; j < 4; j++){
ktm2[j] = k00[j];
}
k00 += 4;
ktm2 += 4;
}
}
}
4.2 对输入数据进行变换
对卷积核进行变换之后,接下来就轮到对输入矩阵进行变换了,即对V矩阵进行计算,。上面我们已经提到过,对于卷积核获得的每一个,我们都需要一个对应的的图像块(tile)和它做卷积运算(eltwise_multiply)。所以这里我们首先需要确定输入数据可以被拆成多少个图像块,并且我们需要为变换矩阵V申请空间,从第三节可知:输入变换矩阵,尺寸为,即每个小块的变换矩阵都为,但是输入特征图长宽不一定会被8整除,这个时候就需要对输入特征图进行扩展(padding),这部分预处理的代码实现如下:
// Vc,b = B^Td_{c,b}B
// 输出特征图如果长宽不够需要Padding
int outW = (outWidth + 5) / 6 * 6;
int outH = (outHeight + 5) / 6 * 6;
int W = outW + 2;
int H = outH + 2;
int Top = 0;
int Left = 0;
int Bottom = H;
int Right = W;
int PadHeight = Bottom - Top;
int PadWidth = Right - Left;
int PadSize = PadHeight * PadWidth;
float *srcPadding = new float[PadHeight * PadWidth * inChannel];
PaddingLayerArm now;
now.padding(src, inWidth, inHeight, inChannel, srcPadding, 0, H - inHeight, 0, W - inWidth, 0);
int w_tm = outW / 6 * 8;
int h_tm = outH / 6 * 8;
int tiles = w_tm / 8 * h_tm / 8;
int src_tm_channel = inChannel;
int src_tm_h = 16 * w_tm / 8 * h_tm / 8;
int src_tm_w = 4;
int src_tm_size = src_tm_h * src_tm_w;
float *src_tm = new float[src_tm_channel * src_tm_h * src_tm_w];
注意上面src_tm的形状,这是考虑到了卷积核变换矩阵已经执行了Pack策略,所以这里为了方便后续的卷积计算和进行指令集加速,同样将src_tm进行Pack,这个Pack是直接规定计算完之后4个4个岔开存储的方式来实现的。另外,输入Blob的一个Channel对应了输出Blob的一个Channel。
然后我们再通过WinCNN工具可以获得B矩阵和B的转置矩阵,并确定V矩阵更好的计算策略(指的是可以复用一些中间变量)。
// BT =
// ⎡1 0 -21/4 0 21/4 0 -1 0⎤
// ⎢ ⎥
// ⎢0 1 1 -17/4 -17/4 1 1 0⎥
// ⎢ ⎥
// ⎢0 -1 1 17/4 -17/4 -1 1 0⎥
// ⎢ ⎥
// ⎢0 1/2 1/4 -5/2 -5/4 2 1 0⎥
// ⎢ ⎥
// ⎢0 -1/2 1/4 5/2 -5/4 -2 1 0⎥
// ⎢ ⎥
// ⎢0 2 4 -5/2 -5 1/2 1 0⎥
// ⎢ ⎥
// ⎢0 -2 4 5/2 -5 -1/2 1 0⎥
// ⎢ ⎥
// ⎣0 -1 0 21/4 0 -21/4 0 1⎦
//B =
// ⎡1 0 0 0 0 0 0 0 ⎤
// ⎢0 1 -1 1/2 -1/2 2 -2 -1 ⎥
// ⎢-21/4 1 1 1/4 1/4 4 4 0 ⎥
// ⎢0 -17/4 17/4 -5/2 5/2 -5/2 5/2 21/4 ⎥
// ⎢21/4 -17/4 -17/4 -5/4 -5/4 -5 -5 0 ⎥
// ⎢0 1 -1 2 2 1/2 -1/2 -21/4⎥
// ⎢-1 1 1 1 1 1 1 0 ⎥
// ⎢0 0 0 0 0 0 0 1 ⎥
// 0 = r00 - r06 + (r04 - r02) * 5.25
// 7 = r07 - r01 + (r03 - r05) * 5.25
// 1 = (r02 + r06 - r04 * 4.25) + (r01 - r03 * 4.25 + r05)
// 2 = (r02 + r06 - r04 * 4.25) - (r01 - r03 * 4.25 + r05)
// 3 = (r06 + r02 * 0.25 - r04 * 1.25) + (r01 * 0.5 - r03 * 2.5 + r05 * 2)
// 4 = (r06 + r02 * 0.25 - r04 * 1.25) - (r01 * 0.5 - r03 * 2.5 + r05 * 2)
// reuse r04 * 1.25
// reuse r03 * 2.5
// 5 = (r06 + (r02 - r04 * 1.25) * 4) + (r01 * 2 - r03 * 2.5 + r05 * 0.5)
// 6 = (r06 + (r02 - r04 * 1.25) * 4) - (r01 * 2 - r03 * 2.5 + r05 * 0.5)
接下来我们就可以开始计算V矩阵了,代码如下:
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int q = 0; q < inChannel; q++){
const float *padptr = srcPadding + q * PadSize;
float *srcptr = src_tm + q * src_tm_size;
float tmpV[8][8];
//tile
for(int i = 0; i < h_tm / 8; i++){
for(int j = 0; j < w_tm / 8; j++){
float *r0 = padptr + i * 6 * PadWidth + j * 6;
// Bd_{c,b}
for(int m = 0; m < 8; m++){
tmpV[0][m] = r0[0] - r0[6] + (r0[4] - r0[2]) * 5.25f;
tmpV[7][m] = r0[7] - r0[1] + (r0[3] - r0[5]) * 5.25f;
float t1 = (r0[2] + r0[6] - r0[4] * 4.25f);
float t2 = (r0[1] + r0[5] - r0[3] * 4.25f);
tmpV[1][m] = t1 + t2;
tmpV[2][m] = t1 - t2;
float t3 = (r0[6] + r0[2] * 0.25f - r0[4] * 1.25f);
float t4 = (r0[1] * 0.5f - r0[3] * 2.5f + r0[5] * 2.f);
tmpV[3][m] = t3 + t4;
tmpV[4][m] = t3 - t4;
float t5 = (r0[6] + (r0[2] - r0[4] * 1.25f) * 4.f);
float t6 = (r0[1] * 2.f - r0[3] * 2.5f + r0[5] * 0.5f);
tmpV[5][m] = t5 + t6;
tmpV[6][m] = t5 - t6;
r0 += PadWidth;
}
//Bd_{c,b}B^T
float *r00 = srcptr + (i * w_tm / 8 + j) * src_tm_w;
float *r04 = srcptr + (i * w_tm /8 + j + tiles) * src_tm_w;
for(int m = 0; m < 8; m++){
float* tmpVPtr = tmpV[m];
r00[0] = tmpVPtr[0] - tmpVPtr[6] + (tmpVPtr[4] - tmpVPtr[2]) * 5.25f;
r04[3] = tmpVPtr[7] - tmpVPtr[1] + (tmpVPtr[3] - tmpVPtr[5]) * 5.25f;
float t1 = (tmpVPtr[2] + tmpVPtr[6] - tmpVPtr[4] * 4.25f);
float t2 = (tmpVPtr[1] - tmpVPtr[3] * 4.25f + tmpVPtr[5]);
r00[1] = t1 + t2;
r00[2] = t1 - t2;
float t3 = (tmpVPtr[6] + tmpVPtr[2] * 0.25f - tmpVPtr[4] * 1.25);
float t4 = (tmpVPtr[1] * 0.5f - tmpVPtr[3] * 2.5f + tmpVPtr[5] * 2.f);
r00[3] = t3 + t4;
r04[0] = t3 - t4;
float t5 = (tmpVPtr[6] + (tmpVPtr[2] - tmpVPtr[4] * 1.25f) * 4.f);
float t6 = (tmpVPtr[1] * 2.f - tmpVPtr[3] * 2.5f + tmpVPtr[5] * 0.5f);
r04[1] = t5 + t6;
r04[2] = t5 - t6;
r00 += 2 * tiles * src_tm_w;
r04 += 2 * tiles * src_tm_w;
}
}
}
}
delete [] srcPadding;
可以看到这个地方不仅计算了V矩阵,并在存储时就对V矩阵进行了重新排列,以适应卷积核变化矩阵的Pack结果,方便后面进行卷积计算的加速同时获得更好的访存,这个过程如下图所示:
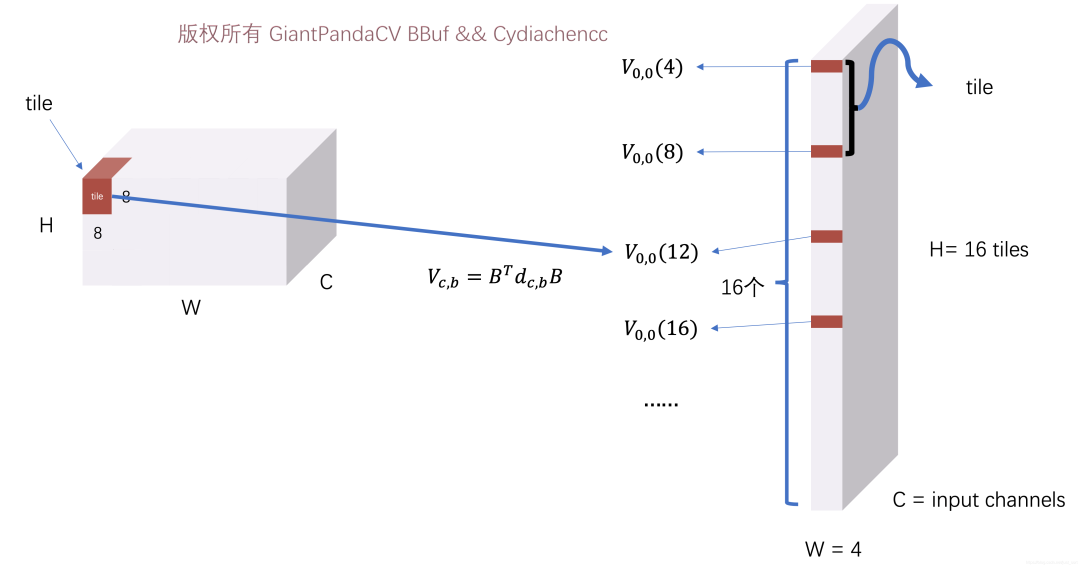 对输入矩阵进行变换的过程
对输入矩阵进行变换的过程4.3 计算M矩阵
M矩阵的计算公式为:
其中,k代表输出通道数,b表示tile序号。
由于上面输入图像块已经执行了Pack策略,这里只需要将对应小块进行乘加操作即完成了M矩阵的计算,这部分的代码实现如下:
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int cc = 0; cc < nnOutChannel; cc++){
int c = cc * 4;
float *dest0 = dest_tm + c * dst_tm_size;
float *dest1 = dest_tm + (c + 1) * dst_tm_size;
float *dest2 = dest_tm + (c + 2) * dst_tm_size;
float *dest3 = dest_tm + (c + 3) * dst_tm_size;
const float *ktm = kernel + cc * kernelSize;
int q = 0;
for(; q + 1 < inChannel; q += 2){
const float* r0 = src_tm + q * src_tm_size;
const float* r1 = src_tm + (q + 1) * src_tm_size;
float* destptr0 = dest0;
float *destptr1 = dest1;
float *destptr2 = dest2;
float *destptr3 = dest3;
for(int r = 0; r < 16; r++){
for(int t = 0; t < tiles; t++){
for(int m = 0; m < 4; m++){
destptr0[m] += r0[m] * ktm[m];
destptr0[m] += r1[m] * ktm[m + 4];
destptr1[m] += r0[m] * ktm[m + 8];
destptr1[m] += r1[m] * ktm[m + 12];
destptr2[m] += r0[m] * ktm[m + 16];
destptr2[m] += r1[m] * ktm[m + 20];
destptr3[m] += r0[m] * ktm[m + 24];
destptr3[m] += r1[m] * ktm[m + 28];
}
r0 += 4;
r1 += 4;
destptr0 += 4;
destptr1 += 4;
destptr2 += 4;
destptr3 += 4;
}
ktm += 32;
}
}
for(; q < inChannel; q++){
const float *r0 = src_tm + q * src_tm_size;
float* destptr0 = dest0;
float *destptr1 = dest1;
float *destptr2 = dest2;
float *destptr3 = dest3;
for(int r = 0; r < 16; r++){
for(int t = 0; t < tiles; t++){
for(int m = 0; m < 4; m++){
destptr0[m] += r0[m] * ktm[m];
destptr1[m] += r0[m] * ktm[m + 4];
destptr2[m] += r0[m] * ktm[m + 8];
destptr3[m] += r0[m] * ktm[m + 12];
}
r0 += 4;
destptr0 += 4;
destptr1 += 4;
destptr2 += 4;
destptr3 += 4;
}
ktm += 16;
}
}
}
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int cc = remainOutChannel; cc < outChannel; cc++){
int c = cc;
float *dest0 = dest_tm + c * dst_tm_size;
const float *ktm = kernel + nnOutChannel * kernelSize + 8 * 8 * inChannel * (c - remainOutChannel);
int q = 0;
for(; q < inChannel; q++){
const float* r0 = src_tm + q * src_tm_size;
float* destptr0 = dest0;
for(int r = 0; r < 16; r++){
for(int i = 0; i < tiles; i++){
for(int m = 0; m < 4; m++){
destptr0[m] += r0[m] * ktm[m];
}
r0 += 4;
destptr0 += 4;
}
ktm += 4;
}
}
}
至此,我们获得了M矩阵,矩阵大概长下面这样子,它仍然是交错排列的:
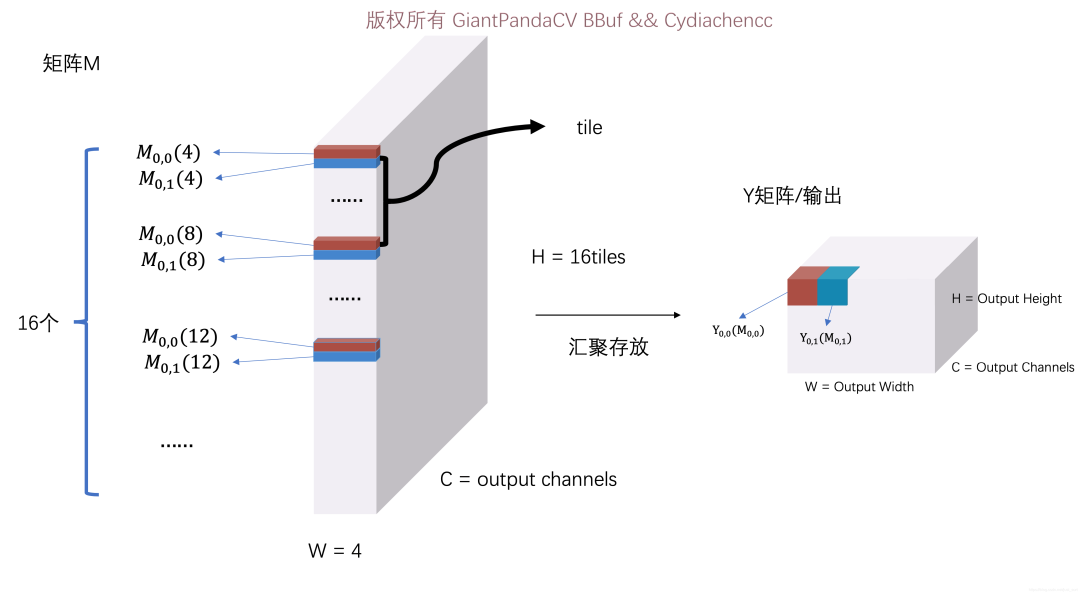 M矩阵长得和V矩阵有点像,主要是通道维度变了
M矩阵长得和V矩阵有点像,主要是通道维度变了4.4 计算结果Y矩阵
现在就到了最后一步了,我们需要计算结果矩阵Y,公式为:
其中表示输出通道数,b表示tile标号,这部分和上面卷积核的计算类似,代码如下:
// Yk,b=A^TMk,bA
// AT=
// ⎡1 1 1 1 1 1 1 0⎤
// ⎢ ⎥
// ⎢0 1 -1 2 -2 1/2 -1/2 0⎥
// ⎢ ⎥
// ⎢0 1 1 4 4 1/4 1/4 0⎥
// ⎢ ⎥
// ⎢0 1 -1 8 -8 1/8 -1/8 0⎥
// ⎢ ⎥
// ⎢0 1 1 16 16 1/16 1/16 0⎥
// ⎢ ⎥
// ⎣0 1 -1 32 -32 1/32 -1/32 1⎦
// 0 = r0 + (r1 + r2) + (r3 + r4) + (r5 + r6) * 32
// 1 = (r1 - r2) + (r3 - r4) * 2 + (r5 - r6) * 16
// 2 = (r1 + r2) + (r3 + r4) * 4 + (r5 + r6) * 8
// 3 = (r1 - r2) + (r3 - r4) * 8 + (r5 - r6) * 4
// 4 = (r1 + r2) + (r3 + r4) * 16+ (r5 + r6) * 2
// 5 = r7 + (r1 - r2) + (r3 - r4) * 32+ (r5 - r6)
float *dest_tm2 = new float[outW * outH * outChannel];
const int dst_tm_size2 = outW * outH;
const int outSize = outHeight * outWidth;
#if USE_OMP
#pragma omp parallel for num_threads(OMP_THREAD)
#endif
for(int cc = 0; cc < outChannel; cc++){
float *destptr = dest_tm + cc * dst_tm_size;
float *outptr = dest_tm2 + cc * dst_tm_size2;
float tmpA[6][8];
for(int i = 0; i < outH / 6; i++){
for(int j = 0; j < outW / 6; j++){
float *destptr0 = destptr + (i * w_tm / 8 + j) * dst_tm_w;
float *destptr4 = destptr + (i * w_tm / 8 + j + tiles) * dst_tm_w;
for(int m = 0; m < 8; m++){
float t1 = destptr0[1] + destptr0[2];
float t2 = destptr0[1] - destptr0[2];
float t3 = destptr0[3] + destptr4[0];
float t4 = destptr0[3] - destptr4[0];
float t5 = destptr4[1] + destptr4[2];
float t6 = destptr4[1] - destptr4[2];
tmpA[0][m] = destptr0[0] + t1 + t3 + t5 * 32;
tmpA[2][m] = t1 + t3 * 4 + t5 * 8;
tmpA[4][m] = t1 + t3 * 16 + t5 + t5;
tmpA[1][m] = t2 + t4 + t4 + t6 * 16;
tmpA[3][m] = t2 + t4 * 8 + t6 * 4;
tmpA[5][m] = destptr4[3] + t2 + t4 * 32 + t6;
destptr0 += dst_tm_w * 2 * tiles;
destptr4 += dst_tm_w * 2 * tiles;
}
float *outptr0 = outptr + (i * 6) * outW + j * 6;
for(int m = 0; m < 6; m++){
const float* tmp0 = tmpA[m];
float t1 = tmp0[1] + tmp0[2];
float t2 = tmp0[1] - tmp0[2];
float t3 = tmp0[3] + tmp0[4];
float t4 = tmp0[3] - tmp0[4];
float t5 = tmp0[5] + tmp0[6];
float t6 = tmp0[5] - tmp0[6];
outptr0[0] = tmp0[0] + t1 + t3 + t5 * 32;
outptr0[2] = t1 + t3 * 4 + t5 * 8;
outptr0[4] = t1 + t3 * 16 + t5 + t5;
outptr0[1] = t2 + t4 + t4 + t6 * 16;
outptr0[3] = t2 + t4 * 8 + t6 * 4;
outptr0[5] = tmp0[7] + t2 + t4 * 32 + t6;
outptr0 += outW;
}
}
}
}
这部分代码就实现了M矩阵汇聚并利用A矩阵获得了最终的结果Y。这个过程上一节图中已经画了,这里主要实现的是图中的右半部分:
Y矩阵汇聚存放获得输出Blob但是需要注意的是这里获得的Y有可能是多了几行或者几列,也就是拖尾为0的部分,所以需要把这一部分Crop掉,才能获得我们最终的结果特征图。Crop部分的代码如下:
//crop
for(int cc = 0; cc < outChannel; cc++){
float *outptr = dest_tm2 + cc * dst_tm_size2;
float *outptr2 = dest + cc * outHeight * outWidth;
for(int i = 0; i < outHeight; i++){
for(int j = 0; j < outWidth; j++){
outptr2[0] = outptr[0];
outptr2++;
outptr++;
}
outptr += (outW - outWidth);
}
}
至此,WinoGrad的算法流程结束,我们获得了最后的卷积计算结果。
5. WinoGrad算法进一步加速上面无论是针对U,V,M还是Y矩阵的计算我们使用的都是暴力计算,所以接下来可以使用Neon Instrics和Neon Assembly技术进行优化。介于篇幅原因,这里就不贴代码了,有需要学习的可以关注后续MsnhNet的WinoGrad代码部分https://github.com/msnh2012/Msnhnet/blob/master/src/layers/arm/MsnhConvolution3x3s1Winograd.cpp。这个代码实现的思路取自开源框架NCNN,在此表示感谢NCNN这一优秀工作(github:https://github.com/Tencent/ncnn)。
和Sgemm用于卷积一样,我们也需要思考WinoGrad在何种情况下是适用的,或者说是有明显加速的。这篇文章介绍的WinoGrad卷积是针对NCHW这种内存排布的,然后我们来看一下NCNN在基于NCHW这种内存排布下,是在何种情况下启用WinoGrad()?
通过查看NCNN的源码(https://github.com/Tencent/ncnn/blob/master/src/layer/arm/convolution_arm.cpp)可以发现,只有在输入输出通道均>=16,并且特征图长宽均小于等于120的条件下才会启用WinoGrad卷积。
那么这个条件是如何得出的,除了和手工优化的conv3x3s1(https://github.com/msnh2012/Msnhnet/blob/master/src/layers/arm/MsnhConvolution3x3s1.cpp)在不同条件下做速度对比测试之外,我们也可以感性的分析一下。
第一,WinoGrad算法设计到几个矩阵变换,如果计算量不大,这几个矩阵变换的成本占计算总成本的比例就越大,所以WinoGrad应当是在计算量比较大时才能有效,如VGG16。
第二,当计算量比较大的时候,又要考虑到Cache命中率的问题,这个时候WinoGrad访存可能会比直接手动优化更差,导致速度上不去。
7. 速度测试由于笔者还未实现完整Neon Instrics和Assembly部分,所以暂时无法给出速度对比。尝试从NCNN的BenchMark中找到WinoGrad的加速效果大概是什么样的,但只能找到各个网络在各种板子上的整体推理速度,没有WinoGrad F(6,3)单独的速度对比,等国庆争取补上来吧。
8. 结语关于WinoGrad的原理介绍还有工程实现(基于NCNN)暂时就讲到这里了,有问题欢迎在评论区讨论哦。我刚入门移动端优化几个月还有非常多知识需要学习,nihui,虫叔,白牛,大老师他们都是高人,这几个月从他们的文章受益良多,非常感谢!
9. 致谢- https://zhuanlan.zhihu.com/p/72149270
- https://www.cnblogs.com/shine-lee/p/10906535.html
- https://zhuanlan.zhihu.com/p/81201840
MsnhNet是一款基于纯c++的轻量级推理框架,本框架受到darknet启发。
项目地址:https://github.com/msnh2012/Msnhnet ,欢迎一键三连。
本框架目前已经支持了X86、Cuda、Arm端的推理(支持的OP有限,正努力开发中),并且可以直接将Pytorch模型(后面也会尝试接入更多框架)转为本框架的模型进行部署,欢迎对前向推理框架感兴趣的同学试用或者加入我们一起维护这个轮子。
最后,欢迎加入Msnhnet开发QQ交流群,有对项目的建议或者说个人的需求都可以在里面或者github issue提出。
交流群图片欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
二维码