
基于OpenCV的实时停车地点查找
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
简介
我们常常会在停车场周围四处行驶很多次来寻找一个停车位,如果我们的电话可以准确告诉我们最近的停车位在哪里,那是不是很方便!
事实证明,使用深度学习和OpenCV解决这个问题相对容易。所需要的只是停车场的鸟瞰图,我们的模型中将突出显示LA机场停车场上的所有可用停车位,并显示可用停车位的数量,而且具有很好的实时性。
实时停车位检测
步骤概述
建立此停车检测模型的主要步骤有两个:
• 检测所有可用停车位的位置
• 识别停车位是否空置或有人占用
由于这里安装了摄像机视图,因此我们可以使用OpenCV对每个停车位进行一次映射。一旦知道了每个停车位的位置,便可以使用深度学习来预测其是否空置。
检测所有可用停车位的位置
我用来检测停车位的基本思想是,这里的所有停车位分隔线都是水平线,列中的停车位之间的间距大致相等。我首先使用Canny边缘检测来获取边缘图像。我还掩盖了没有停车位的区域。见下文:

卡尼边缘检测输出
然后,我们在边缘图像上进行了hough线变换,绘制出了所有可以识别的线。仅通过选择斜率接近零的线来隔离水平线。请参见下面的霍夫变换输出:

使用HoughLines进行线检测
如大家所见,hough线在识别停车线方面做得相当不错,但是输出并不干净-多次检测到多条停车线,而有些漏掉了。那么我们如何清理呢?
使用线返回的坐标,我们对x观测值进行了聚类,以识别主要的停车车道。聚类逻辑通过识别检测到的车道线的x坐标中的间隙来工作。这使我可以在此处识别12条停车道。见下文
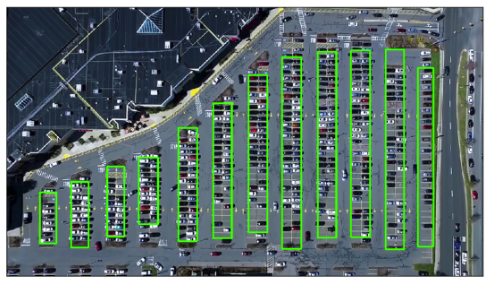
通过将hough线的x坐标聚类来识别停车道
如果所有这些看起来都很复杂,请不要担心-我们已经逐步记录了代码:
https://github.com/priya-dwivedi/Deep-Learning/blob/master/parking_spots_detector/identify_parking_spots.ipynb
现在,我对所有停车位都非常了解,因此我通过假设所有停车位的大小相同来确定每个停车位,这是一个合理的假设。我仔细观察了结果,以确保尽可能准确地捕捉到斑点之间的边界。我们终于能够划出每个停车位。

标出每个停车位
现在完成了—我们可以为每个位置分配一个ID,并将其坐标保存在字典中。我腌了这本字典,以便以后可以检索。这是可能的,因为已经安装了相机,我们不需要一次又一次地计算视图中每个点的位置。
识别斑点是否被标记
现在我们有了停车地图,我们认为有几种方法可以确定该地点是否有人居住:
• 使用OpenCV检查斑点的像素颜色是否与空的停车点的颜色对齐。这是一种简单的方法,但容易出错。例如,照明的改变将改变一个空的停车位的颜色,这将使这种逻辑难以全天工作。同样,如果有可能,逻辑将使灰色的汽车混淆为空的停车位
• 使用对象检测来识别所有汽车,然后检查汽车的位置是否与停车位重叠。我做了尝试,发现可以实时工作的对象检测模型在检测小尺寸对象方面确实遇到了困难。被检测到的汽车中不超过30%
• 使用CNN查看每个停车位,并预测是否有人占用。这种方法最终效果最佳
要构建CNN,我们需要具有和不具有汽车的停车位图像。我提取了每个斑点的图像并将其保存在文件夹中,然后将这些图像分组为是否占用。培训文件夹可以在以下链接中找到:
https://github.com/priya-dwivedi/Deep-Learning/tree/master/parking_spots_detector
由于在尺寸为1280x720的图像中有近550个停车位,因此每个停车位的大小仅为15x60像素。请参见下面的空白图片:

占用地点

空点
但是,由于占用的位置和空的位置看起来很不一样,因此对于CNN来说,这不是一个具有挑战性的问题
但是,对于这两个类,我们只有大约550张图像,因此决定使用转移学习,方法是获取VGG的前10层,并在VGG模型的输出中添加一个softmax层。大家可以在以下链接中找到此迁移学习模型的代码。该模型的验证精度为94%。见下文:
https://github.com/priya-dwivedi/Deep-Learning/blob/master/parking_spots_detector/CNN_model_for_occupancy.ipynb
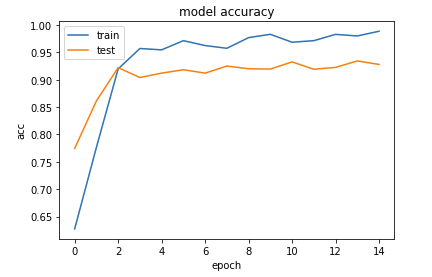
CNN模型测试和训练精度
现在,我们将停车位检测与CNN预测器结合起来,构建了一个停车位检测器。
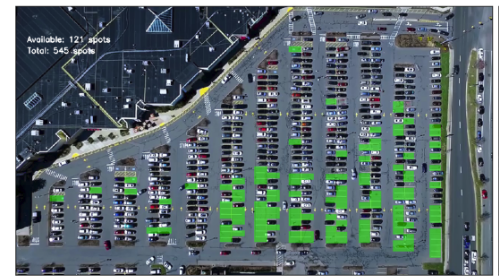
空点预测
结论
现在,链接不同的工具并使用深度学习来构建实际应用变得如此容易,令我们感到十分惊讶。我们可以在两个下午完成这项工作。
进一步拓展的几个其他想法:
• 如果可以使用深度学习将停车位检测逻辑扩展到在任何停车地图上工作,那就太好了。OpenCV的局限性在于需要针对每个用例进行调整
• CNN中使用的VGG模型相当繁重。很想尝试重量更轻的模型
代码链接:https://github.com/priya-dwivedi/Deep-Learning/tree/master/parking_spots_detector
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~