
算法工程师的修养 | 图解SQL
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
作者:不剪发的Tony老师
https://blog.csdn.net/horses/article/details/104553075
本文介绍关系数据库的设计思想:在 SQL 中,一切皆关系。
在 Unix 中,一切皆文件。
在面向对象的编程语言中,一切皆对象。
关系模型由数据结构、关系操作、完整性约束三部分组成。
关系模型中的数据结构就是关系表,包括基础表、派生表(查询结果)和虚拟表(视图)。
常用的关系操作包括增加、删除、修改和查询(CRUD),使用的就是 SQL 语言。其中查询操作最为复杂,包括选择(Selection)、投影(Projection)、并集(Union)、交集(Intersection)、差集(Exception)以及笛卡儿积(Cartesian product)等。
完整性约束用于维护数据的完整性或者满足业务约束的需求,包括实体完整性(主键约束)、参照完整性(外键约束)以及用户定义的完整性(非空约束、唯一约束、检查约束和默认值)。
我们今天的主题是关系操作语言,也就是 SQL。
接下来我们具体分析一下关系的各种操作语句;目的是为了让大家能够了解 SQL 是一种面向集合的编程语言,它的操作对象是集合,操作的结果也是集合。
在关系数据库中,关系、表、集合三者通常表示相同的概念。
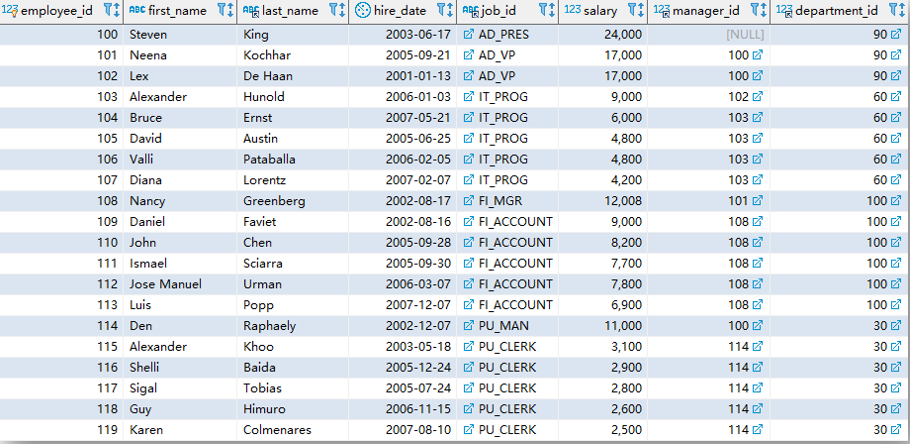
SELECT employee_id, first_name, last_name, hire_date
FROM employees;
SELECT *
FROM (SELECT employee_id, first_name, last_name, hire_date
FROM employees) t;
我们再看一个 PostgreSQL 中的示例:
-- PostgreSQL
SELECT *
FROM upper('sql');
| upper |
|-------|
| SQL |
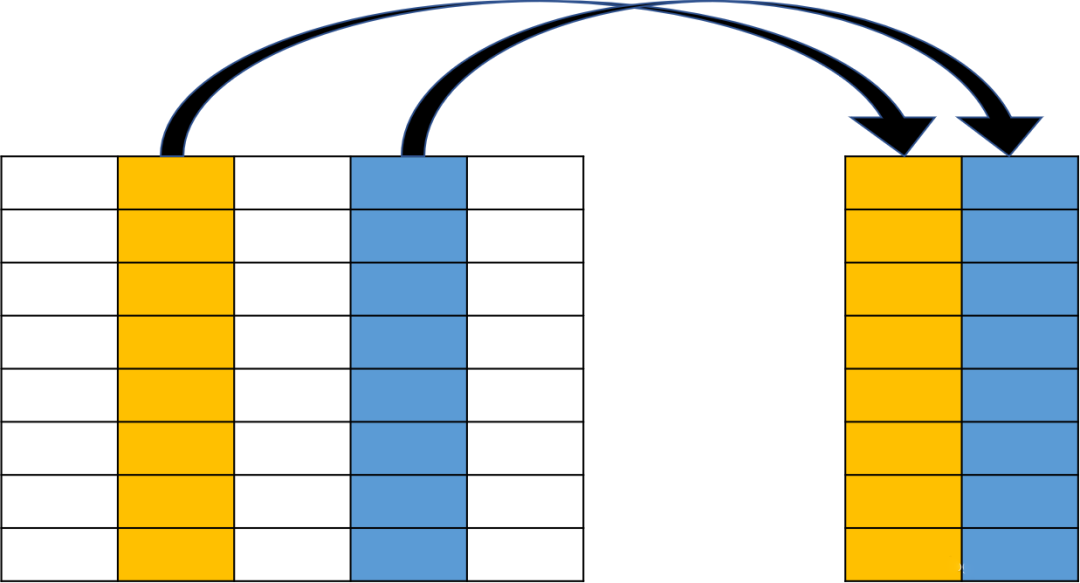
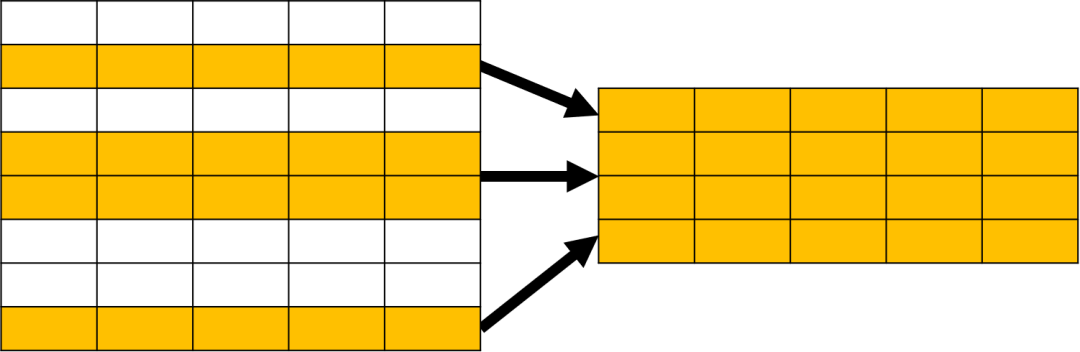
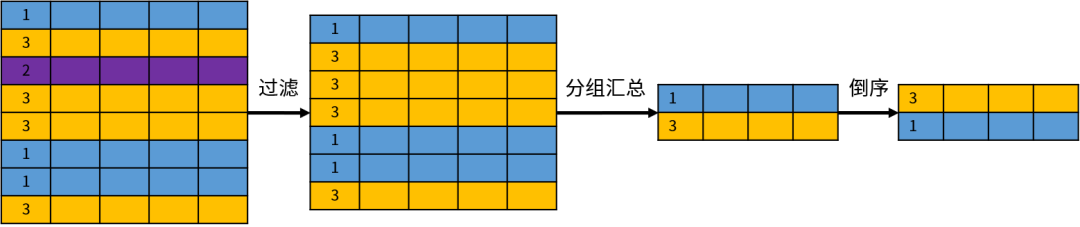
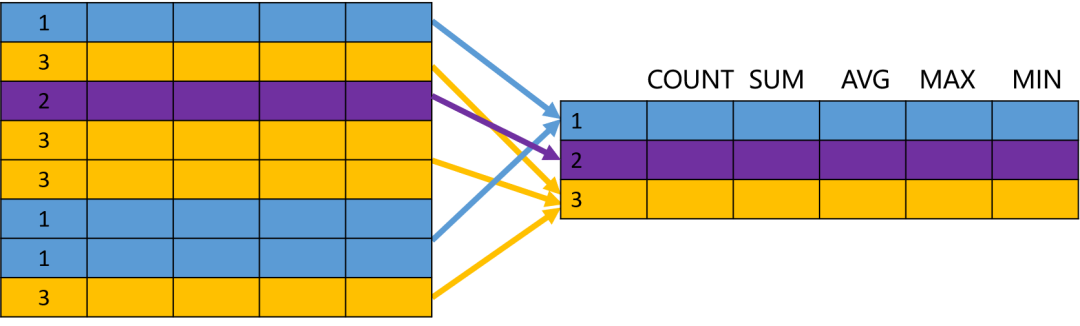
SELECT department_id, count(*), first_name
FROM employees
GROUP BY department_id;
UNION(并集运算)
INTERSECT(交集运算)
EXCEPT/MINUS(差集运算)
两边的集合中字段的数量和顺序必须相同;
两边的集合中对应字段的类型必须匹配或兼容。
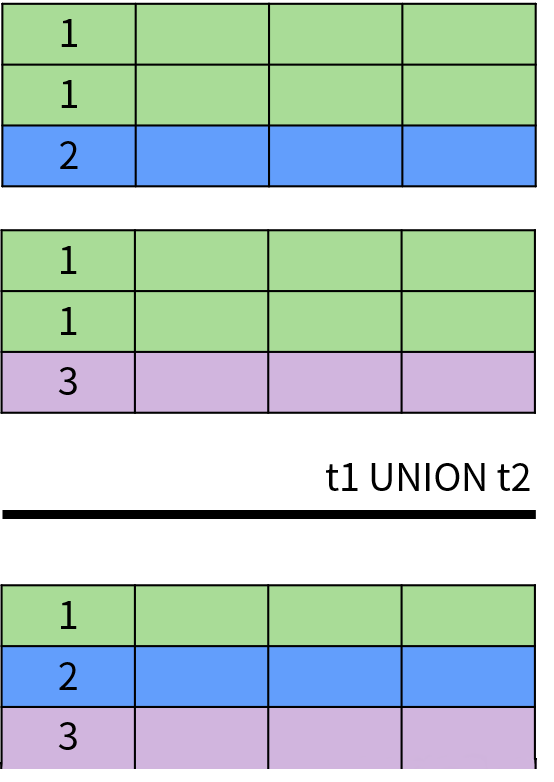
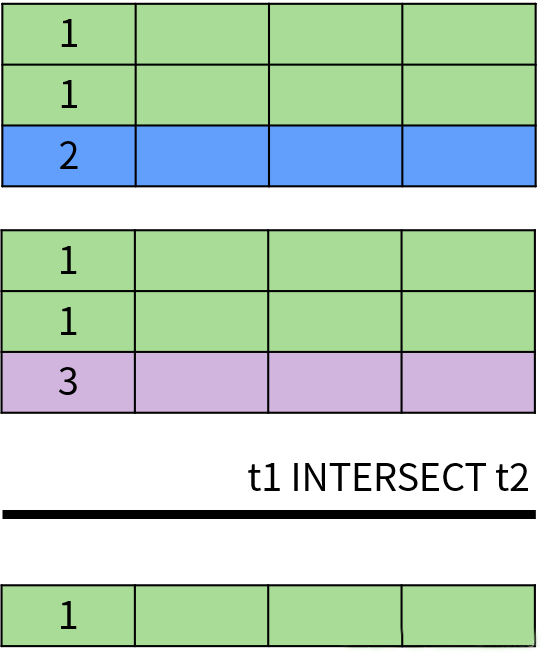
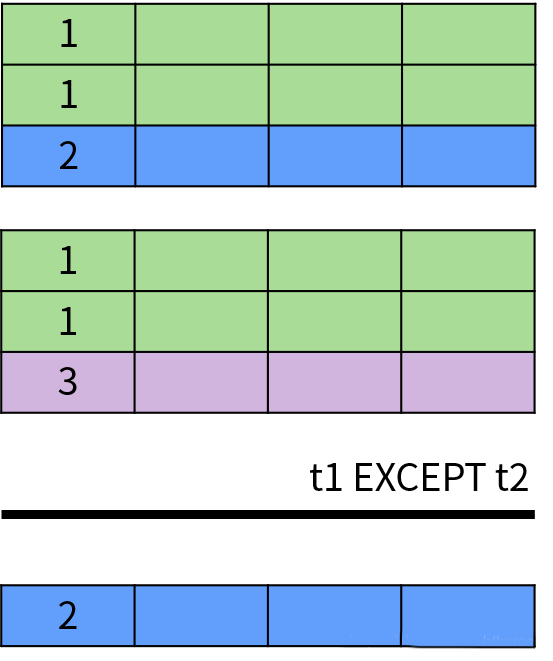
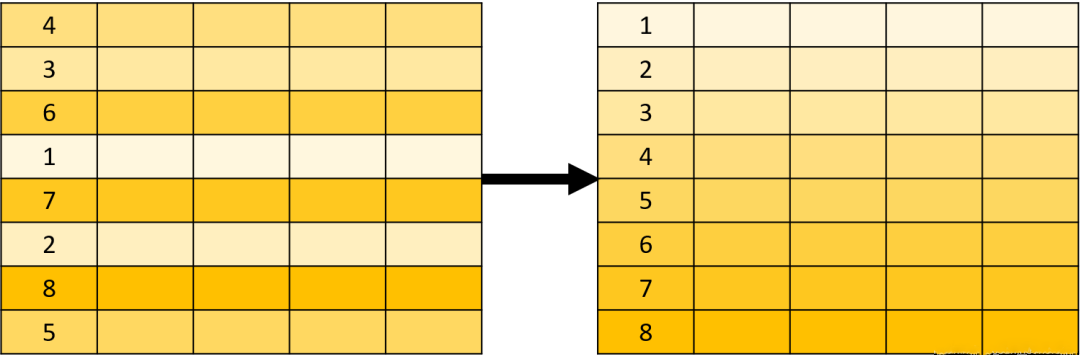
SQL 中的关系概念来自数学中的集合理论,因此 UNION、INTERSECT 和 EXCEPT 分别来自集合论中的并集(∪\cup∪)、交集(∩\cap∩)和差集(∖\setminus∖)运算。 需要注意的是,集合理论中的集合不允许存在重复的数据,但是 SQL 允许。因此,SQL 中的集合也被称为多重集合(multiset);多重集合与集合理论中的集合都是无序的,但是 SQL 可以通过 ORDER BY 子句对查询结果进行排序。


t1 RIGHT JOIN t2
t2 LEFT JOIN t1
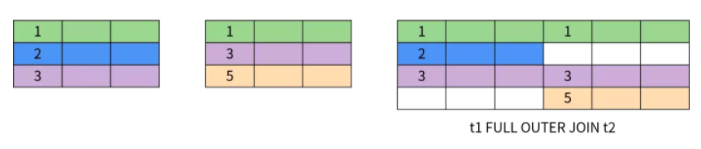
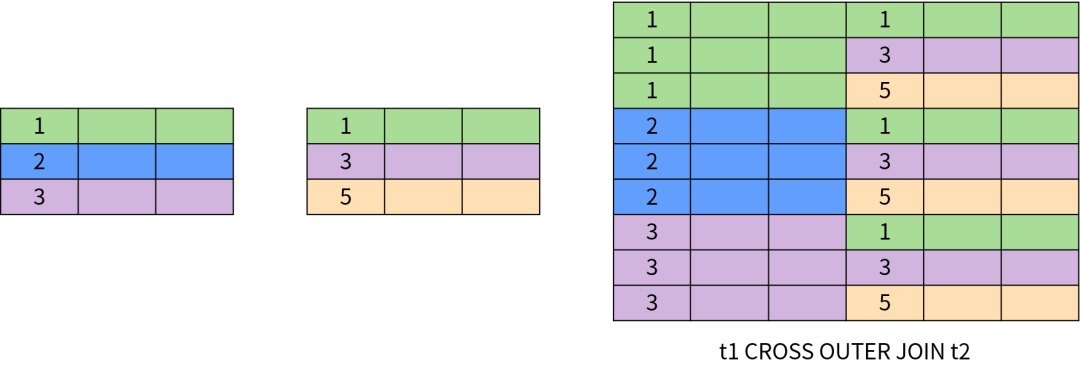
其他类型的连接还有半连接(SEMI JOIN)、反连接(ANTI JOIN)。
SELECT department_id
FROM departments
UNION
SELECT department_id
FROM employees;
SELECT COALESCE(d.department_id, e.department_id)
FROM departments d
FULL JOIN employees e ON (e.department_id = d.department_id);
CREATE TABLE test(id int);
-- MySQL、SQL Server 等
INSERT INTO test(id) VALUES (1),(2),(3);
-- Oracle
INSERT INTO test(id)
(SELECT 1 AS id FROM DUAL
UNION ALL
SELECT 2 FROM DUAL
UNION ALL
SELECT 3 FROM DUAL);
SELECT *
FROM (
VALUES(1),(2),(3)
) test(id);
同样,UPDATE 和 DELETE 语句也都是以关系表为单位的操作;只不过我们习惯了说更新一行数据或者删除几条记录。
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论