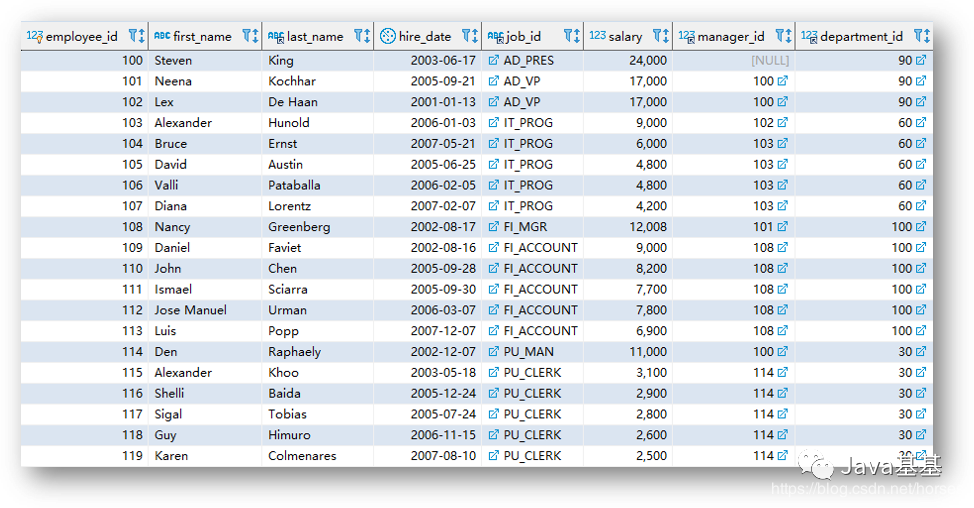
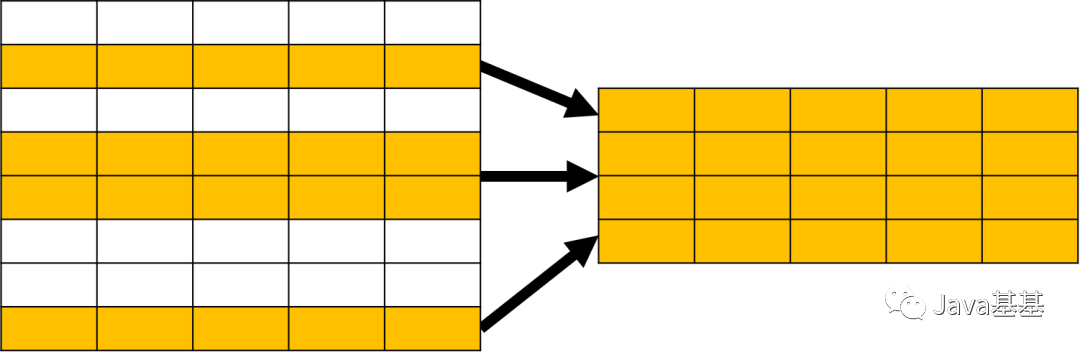
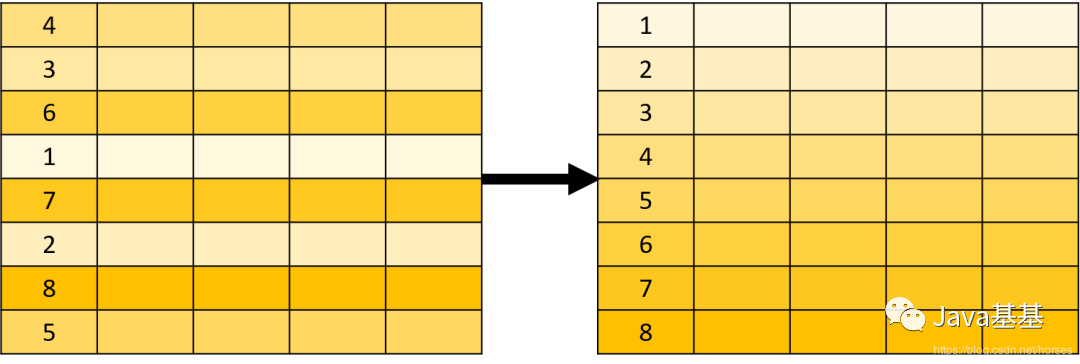
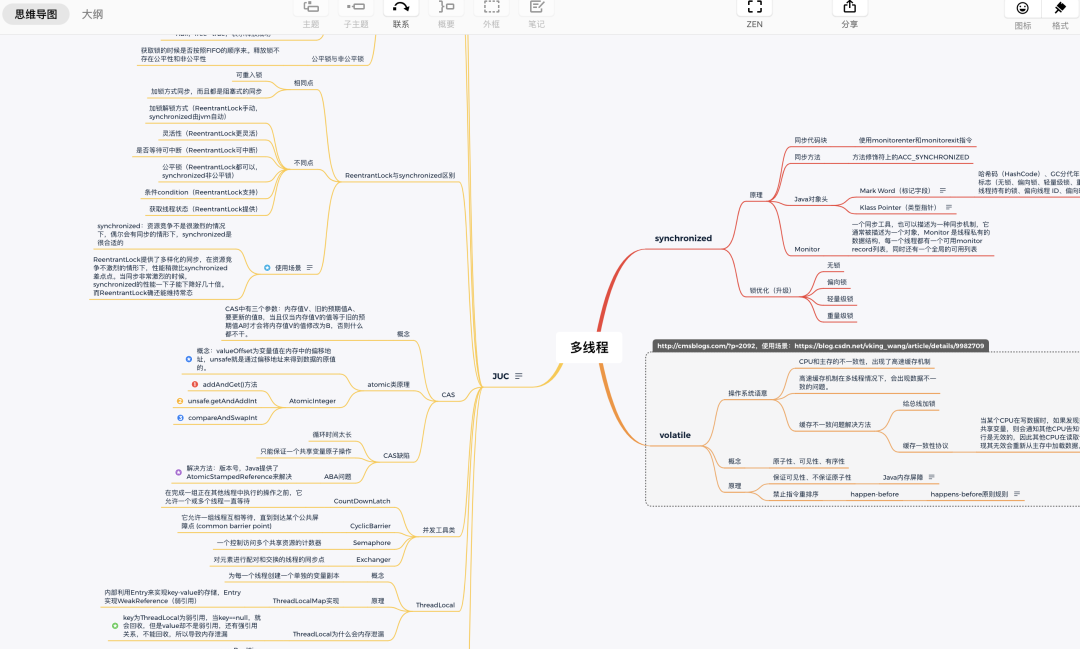
upper() 是一个大写转换的函数。它出现再 FROM 子句中,意味着它的结果也是一个表,只不过是 1 行 1 列的特殊表。SELECT 子句用于指定需要查询的字段,可以包含表达式、函数值等。SELECT 在关系操作中被称为投影(Projection),看下面的示意图应该就比较好理解了。除了 SELECT 之外,还有一些常用的 SQL 子句。WHERE 用于指定数据过滤的条件,在关系运算中被称为选择(Selection),示意图如下:ORDER BY 用于对查询的结果进行排序,示意图如下:总之,SQL 可以完成各种数据操作,例如过滤、分组、排序、限定数量等;所有这些操作的对象都是关系表,结果也是关系表。在这些关系操作中,有一个比较特殊,就是分组。
GROUP BY
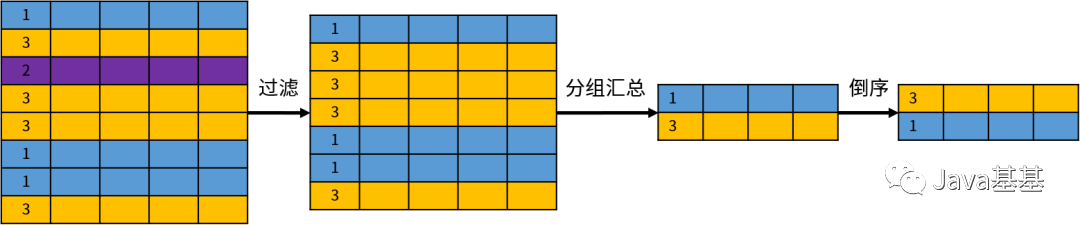
分组( GROUP BY)操作和其他的关系操作不同,因为它改变了关系的结构。来看下面的示例:
SELECT department_id, count(*), first_name FROM employees GROUPBY department_id;
该语句的目的是按照部门统计员工的数量,但是存在一个语法错误,就是 first_name 不能出现在查询列表中。原因在于按照部门进行分组的话,每个部门包含多个员工;无法确定需要显示哪个员工的姓名,这是一个逻辑上的错误。所以说,GROUP BY 改变了集合元素(数据行)的结构,创建了一个全新的关系。分组操作的示意图如下:尽管如此,GROUP BY 的结果仍然是一个集合。
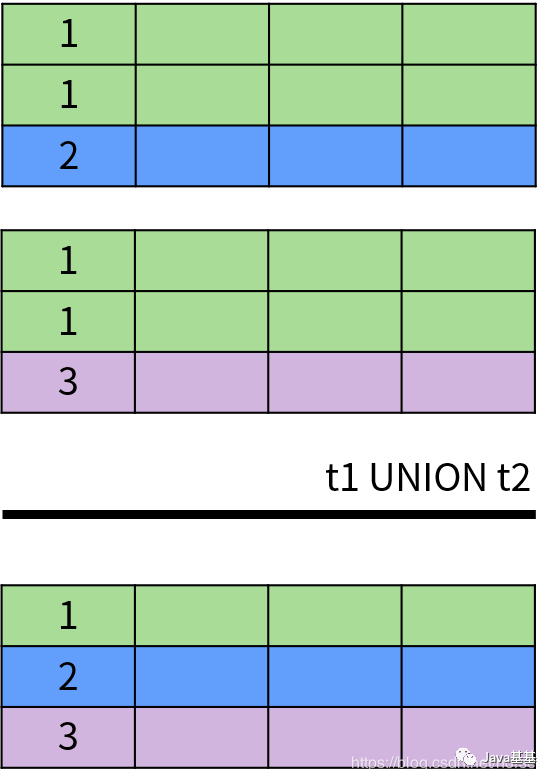
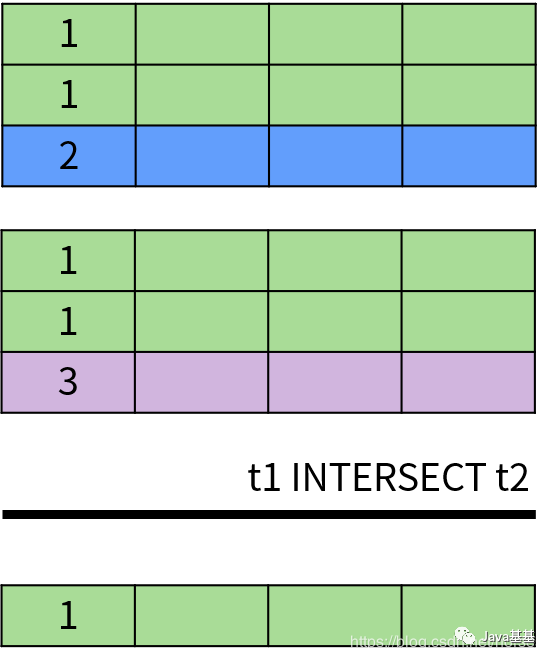
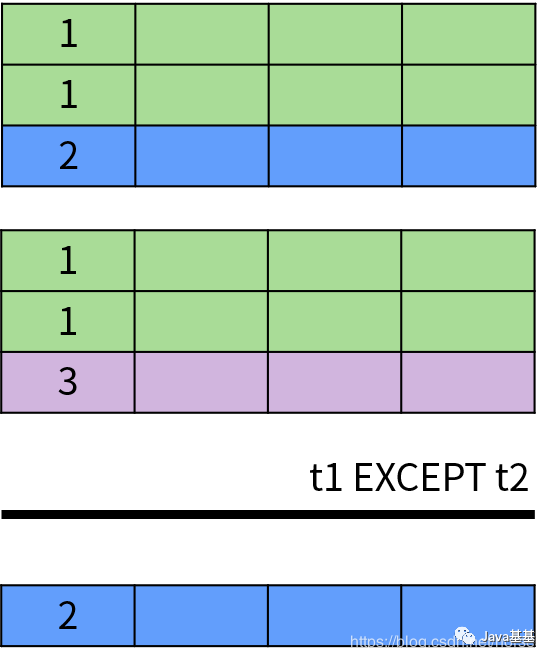
具体来说,UNION 和 UNION ALL 用于计算两个集合的并集,返回出现在第一个查询结果或者第二个查询结果中的数据。它们的区别在于 UNION 排除了结果中的重复数据,UNION ALL 保留了重复数据。下面是 UNION 操作的示意图:INTERSECT 操作符用于返回两个集合中的共同部分,即同时出现在第一个查询结果和第二个查询结果中的数据,并且排除了结果中的重复数据。INTERSECT 运算的示意图如下:EXCEPT 或者 MINUS 操作符用于返回两个集合的差集,即出现在第一个查询结果中,但不在第二个查询结果中的记录,并且排除了结果中的重复数据。EXCEPT 运算符的示意图如下:除此之外,DISTINCT 运算符用于消除重复数据,也就是排除集合中的重复元素。
SQL
中的关系概念来自数学中的集合理论,因此 UNION、INTERSECT 和 EXCEPT
分别来自集合论中的并集(∪\cup∪)、交集(∩\cap∩)和差集(∖\setminus∖)运算。需要注意的是,集合理论中的集合不允许存在重复的数据,但是
SQL 允许。因此,SQL 中的集合也被称为多重集合(multiset);多重集合与集合理论中的集合都是无序的,但是 SQL 可以通过
ORDER BY 子句对查询结果进行排序。