
ARM 原子操作里的两个汇编指令

今天一个读者朋友给我留言,问了这个问题,ARM原子操作的汇编代码,还给我截图了两个不同的解释,让我说哪个是正确的。
原子操作的起因是为了内核同步,保证数据在正确性,之前已经吹过一波,可以看这几篇文章。
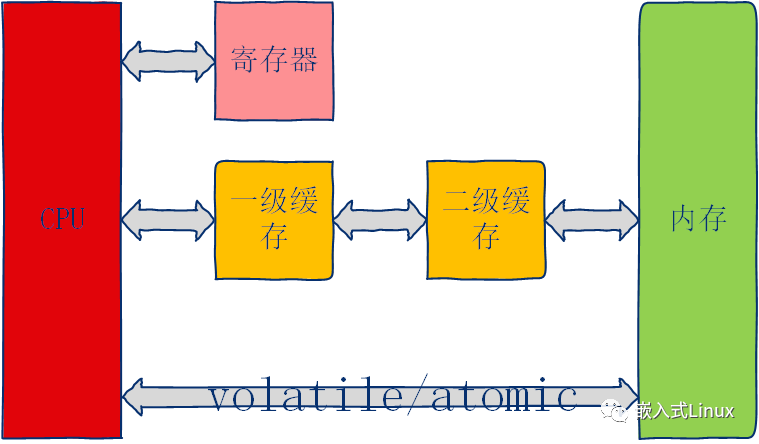
CPU和和存储的连接图
原子操作的代码
我截取的这段是ARM7之后的代码,在ARM6之前的CPU并不支持SMP。所以原子操作的代码也分成了ARM6之前的和ARM7之后的区分。
#define ATOMIC_OP(op, c_op, asm_op) \
static inline void atomic_##op(int i, atomic_t *v) \
{ \
unsigned long tmp; \
int result; \
\
prefetchw(&v->counter); \
errata_855872_dmb(); \
\
__asm__ __volatile__("@ atomic_" #op "\n" \
"1: ldrex %0, [%3]\n" \
" " #asm_op " %0, %0, %4\n" \
" strex %1, %0, [%3]\n" \
" teq %1, #0\n" \
" bne 1b" \
: "=&r" (result), "=&r" (tmp), "+Qo" (v->counter) \
: "r" (&v->counter), "Ir" (i) \
: "cc"); \
}
我们主要讨论两个汇编指令
LDREX
,[]
LDREX 指令从「内存地址」,并且将「内存地址」的内容加载到「」目标寄存器中。
STREX
,,[]
STREX 指令从「内存地址」,并且将「内存地址」的内容加载到「」目标寄存器中,并且把执行结果保存在 「
在执行的时候,还有两个监视器在共同工作
local monitor 「 本地监视器」global monitor「 全局监视器」
单CPU执行原子操作执行的同步情况
单CPU的情况下是不需要global monitor 参与的。
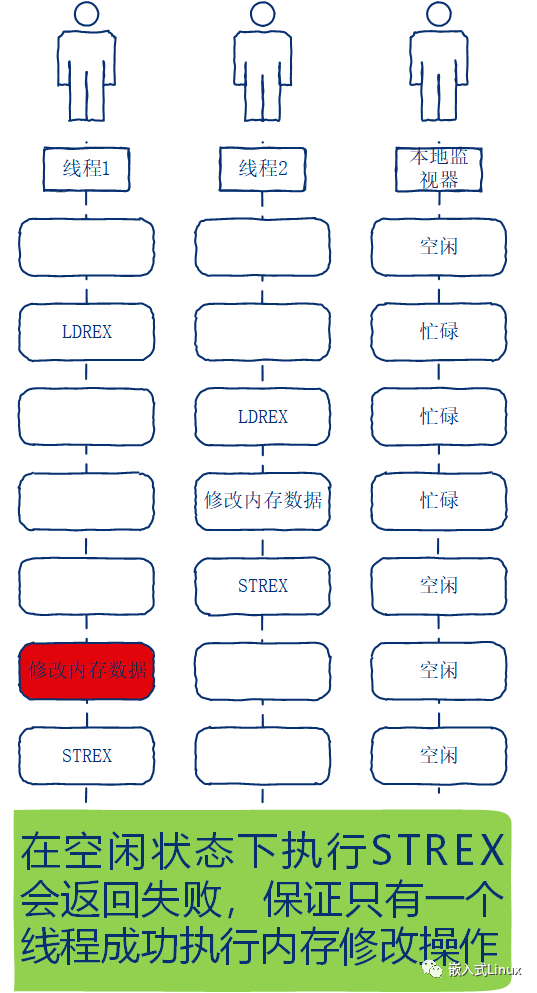
多CPU执行原子操作执行的同步情况
多CPU的情况下需要global monitor 参与。

关于这个同步机子的C语言嵌入汇编代码,还有更加详细的解释,大家如果有兴趣的话,可以看这几个链接,会更加详细。
http://www.wowotech.net/linux_kenrel/atomic.html
https://biscuitos.github.io/blog/ATOMIC/

评论