
多线程程序中操作的原子性
来源:Guancheng (G.C.)
0. 背景
原子操作就是不可再分的操作。在多线程程序中原子操作是一个非常重要的概念,它常常用来实现一些同步机制,同时也是一些常见的多线程Bug的源头。
本文主要讨论了三个问题:
1. 多线程程序中对变量的读写操作是否是原子的?
2. 多线程程序中对Bit field(位域)的读写操作是否是线程安全的?
3. 程序员该如何使用原子操作?
我们先从一道很热门的百度笔试题讲起。很多人讲不清楚其背后的原理,下面我们就来对它进行一下剖析(其实这个题目有点歧义,后面我们会讲到):
要彻底理解这个问题,我们首先需要从硬件讲起。以常见的X86 CPU来说,根据Intel的参考手册,它基于以下三种机制保证了多核中加锁的原子操作(8.1节):
(1)Guaranteed atomic operations (注:8.1.1节有详细介绍)
(2)Bus locking, using the LOCK# signal and the LOCK instruction prefix
(3)Cache coherency protocols that ensure that atomic operations can be carried out on cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon, and P6 family processors
这三个机制相互独立,相辅相承。简单的理解起来就是:
(1)一些基本的内存读写操作是本身已经被硬件提供了原子性保证(例如读写单个字节的操作);
(2)一些需要保证原子性但是没有被第(1)条机制提供支持的操作(例如read-modify-write)可以通过使用”LOCK#”来锁定总线,从而保证操作的原子性
(3)因为很多内存数据是已经存放在L1/L2 cache中了,对这些数据的原子操作只需要与本地的cache打交道,而不需要与总线打交道,所以CPU就提供了cache coherency机制来保证其它的那些也cache了这些数据的processor能读到最新的值。
那么CPU对哪些(1)中的基本的操作提供了原子性支持呢?根据Intel手册8.1.1节的介绍:
从Intel486 processor开始,以下的基本内存操作是原子的:
• Reading or writing a byte(一个字节的读写)
• Reading or writing a word aligned on a 16-bit boundary(对齐到16位边界的字的读写)
• Reading or writing a doubleword aligned on a 32-bit boundary(对齐到32位边界的双字的读写)
从Pentium processor开始,除了之前支持的原子操作外又新增了以下原子操作:
• Reading or writing a quadword aligned on a 64-bit boundary(对齐到64位边界的四字的读写)
• 16-bit accesses to uncached memory locations that fit within a 32-bit data bus(未缓存且在32位数据总线范围之内的内存地址的访问)
从P6 family processors开始,除了之前支持的原子操作又新增了以下原子操作:
• Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line(对单个cache line中缓存地址的未对齐的16/32/64位访问)
需要注意的是尽管从P6 family开始对一些非对齐的读写操作已经提供了原子性保障,但是非对齐访问是非常影响性能的,需要尽量避免。当然了,对于一般的程序员来说不需要太担心这个,因为大部分编译器会自动帮你完成内存对齐。
回到最开始那个笔试题。我们先反汇编一下看看它们到底执行了什么操作:
x = y;mov eax,dword ptr [y]mov dword ptr [x],eaxx++;mov eax,dword ptr [x]add eax,1mov dword ptr [x],eax++x;mov eax,dword ptr [x]add eax,1mov dword ptr [x],eaxx = 1;mov dword ptr [x],1
(1)很显然,x=1是原子操作。
因为x是int类型,32位CPU上int占32位,在X86上由硬件直接提供了原子性支持。实际上不管有多少个线程同时执行类似x=1这样的赋值语句,x的值最终还是被赋的值(而不会出现例如某个线程只更新了x的低16位然后被阻塞,另一个线程紧接着又更新了x的低24位然后又被阻塞,从而出现x的值被损坏了的情况)。
(2)再来看x++和++x。
其实类似x++, x+=2, ++x这样的操作在多线程环境下是需要同步的。因为X86会按三条指令的形式来处理这种语句:从内存中读x的值到寄存器中,对寄存器加1,再把新值写回x所处的内存地址(见上面的反汇编代码)。
例如有两个线程,它们按照如下顺序执行(注意读x和写回x是原子操作,两个线程不能同时执行):
time Thread 1 Thread 20 load eax, x1 load eax, x2 add eax, 1 add eax, 13 store x, eax4 store x, eax
我们会发现最终x的值会是1而不是2,因为Thread 1的结果被覆盖掉了。这种情况下我们就需要对x++这样的操作加锁(例如Pthread中的mutex)以保证同步,或者使用一些提供了atomic operations的库(例如Windows API中的atomic库,Linux内核中的atomic.h,Java concurrent库中的Atomic Integer,C++0x中即将支持的atomic_int等等,这些库会利用CPU提供的硬件机制做一层封装,提供一些保证了原子性的API)。
(3)最后来看看x=y。
在X86上它包含两个操作:读取y至寄存器,再把该值写入x。读y的值这个操作本身是原子的,把值写入x也是原子的,但是两者合起来是不是原子操作呢?我个人认为x=y不是原子操作,因为它不是不可再分的操作。但是它需要不需要同步呢?其实问题的关键在于程序的上下文。
例如有两个线程,线程1要执行{y = 1; x = y;},线程2要执行{y = 2; y = 3;},假设它们按如下时间顺序执行:
time Thread 1 Thread 20 store y, 11 store y, 22 load eax, y3 store y, 34 store x, eax
那么最终线程1中x的值为2,而不是它原本想要的1。我们需要加上相应的同步语句确保y = 2不会在线程1的两条语句之间发生。y = 3那条语句尽管在load y和store x之间执行,但是却不影响x=y这条语句本身的语义。所以你可以说x=y需要同步,也可以说x=y不需要同步,看你怎么理解题意了。x=1是否需要同步也是一样的道理,虽然它本身是原子操作,但是如果有另一个线程要读x=1之后的值,那肯定也需要同步,否则另一个线程读到的就是x的旧值而不是1了。
2. 对Bit field(位域)的读写操作是否是线程安全的?
Bit field常用来高效的存储有限位数的变量,多用于内核/底层开发中。一般来说,对同一个结构体内的不同bit成员的多线程访问是无法保证线程安全的。
例如Wikipedia中的如下例子:
struct foo {int flag : 1;int counter : 15;};struct foo my_foo;/* ... *//* in thread 1 */pthread_mutex_lock(&my_mutex_for_flag);my_foo.flag = !my_foo.flag;pthread_mutex_unlock(&my_mutex_for_flag);/* in thread 2 */pthread_mutex_lock(&my_mutex_for_counter);++my_foo.counter;pthread_mutex_unlock(&my_mutex_for_counter);
两个线程分别对my_foo.flag和my_foo.counter进行读写操作,但是即使有上面的加锁方式仍然不能保证它是线程安全的。原因在于不同的成员在内存中的具体排列方式“跟Byte Order、Bit Order、对齐等问题都有关,不同的平台和编译器可能会排列得很不一样,要编写可移植的代码就不能假定Bit-field是按某一种固定方式排列的”[3]。而且一般来讲CPU对内存操作的最小单位是word(X86的word是16bits),而不是1bit。这就是说,如果my_foo.flag和my_foo.counter存储在同一个word里,CPU在读写任何一个bit member的时候会同时把两个值一起读进寄存器,从而造成读写冲突。这个例子正确的处理方式是用一个mutex同时保护my_foo.flag和my_foo.counter,这样才能确保读写是线程安全的。
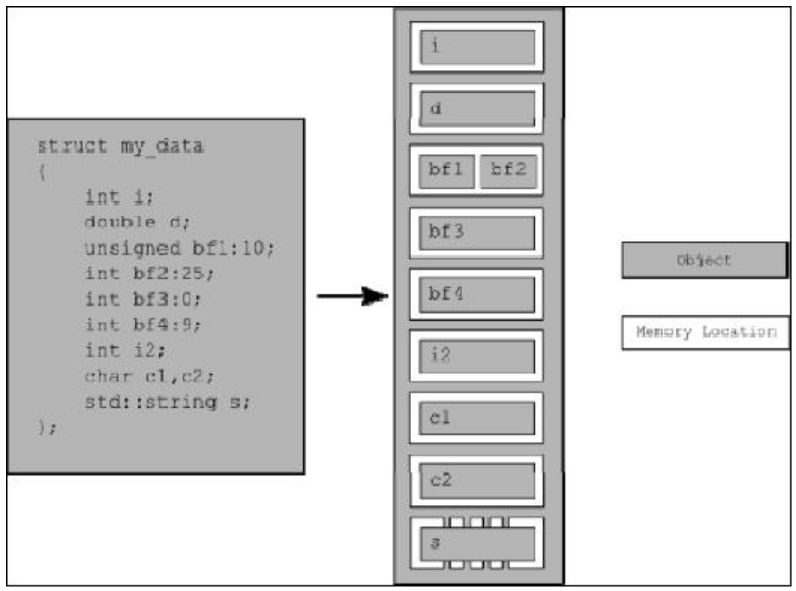
在C++0x草案中对bit field是这样定义的:
连续的多个非0bit的bit fields是属于同一个memory location的;长度为0bit的bit field会把占单独的一个memory location。对同一个memory location的读写不是线程安全的;对不同memory location的读写是线程安全的。
这里有一个因为Bit field不是线程安全所导致的一个Linux内核中的Bug。
引用一下Pongba的总结:
3. 程序员该怎么用Atomic操作?
一般情况下程序员不需要跟CPU提供的原子操作直接打交道,所以只需要选择语言或者平台提供的atomic API即可。而且使用封装好了的API还有一个好处是它们常常还提供了诸如compare_and_swap,fetch_and_add这样既有读又有写的较复杂操作的封装。
常见的API如下:
Windows上InterlockedXXXX的API
GNU/Linux上linux kernel中atomic_32.h
GCC中的Atomic Builtins (__sync_fetch_and_add()等)
Java中的java.util.concurrent.atomic
C++0x中的atomic operation
Intel TBB中的atomic operation
4. 参考文献:
[1] 关于变量操作的原子性(atomicity)FAQ
[2] http://en.wikipedia.org/wiki/Atomic_operation
[3] 关于内存对齐、bit field等 –《Linux C编程一站式学习》
[4] Do you need mutex to protect an ‘int’?
[5] C++ Concurrency in Action
[6] Multithreaded simple data type access and atomic variables
- EOF -
点赞和在看就是最大的支持❤️