
真正的无极放大!30x插值效果惊艳,英伟达等开源LIIF:巧妙的图像超分新思路
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
How to represent an image?在本文中,作者提出一种新颖的LIIF用于对自然图像进行连续表达。同时所提方法甚至可以进行30x插值,且效果惊人。另外,所提表达对于尺寸可变的学习任务具有天然有效性。
加州大学圣地亚哥分校&英伟达提出了一种新颖的连续图像表达方案。它在离散2D图像与连续2D图像之间构建了一种巧妙的连接。受益于所提方法的“连续表达”,它能够对图像进行分辨率调整,做到了真正意义上的“无极放大”,甚至可以进行30x的放大处理。
poster video
下面是一个简单的演示:
如何表达一张图像?
作者一上来就提到这样一个问题:
How to represent an image?
这个问题好回答也不回答。对于人类视觉系统而言,图像是一种连续形式进行呈现的;而在机器世界里,图像是以2D矩阵的离散形式进行存放的。现有的计算机视觉问题的研究也基本都是在2D离散数据集上进行的处理。
在该文中,作者希望学习一种连续图像表达。受启发于3D重建的隐式函数进展,作者提出一种Local Implicit Image Function, LIIF,它采用图像坐标以及2D深度特征作为输入,直接预测给定位置上的RGB输出。由于坐标的连续性,LIIF可以表示成任意分辨率形式。
为生成连续的图像表达,作者通过自监督方式在超分任务上训练了一个encoder和LIIF。所学习到的连续表达能够以任意分辨率对图像进行插值,甚至可以进行30x插值(注:训练时并未引入该尺度)。
作者进一步表明:LIIF表达在2D图像的离散与连续表达之间构建了一个连接,它可以自然的支持尺寸可变的学习任务。下图给出了所提方法在不同倍率下的局部图像示意图。

该文贡献主要包含以下几点:
提出一种新颖的LIIF用于对自然图像进行连续表达;
所提方法甚至可以进行30x插值,且效果惊人;
所提表达对于尺寸可变的学习任务具有天然有效性。
局部隐函数
接下来,我们将逐步引入本文所提出的LIIF表达方式及相应改进点。 在LIIF表达中,每个连续图像
可以表示为2D特征形式
。Neural Implicit Funciotn, NIF
是全图像共享,它是一种MLP,其形式如下:
其中,z为向量,
表示连续图像域坐标,
表示预测信号(也就是RGB值)。基于上述定义,每个向量z可以表示为这样的映射过程:
,也就是说
可以表示为连续图像,它将坐标映射到RGB。

假设
的
的特征向量均匀的分布在连图像域的2D空间,见上图圆点,同时我们可以为每个圆点赋予2D坐标信息。对于图像
,其在位置
处的RGB值可以表示如下:
其中,
表示
中距离
最近的隐特征,
表示因特征对应的坐标。仍以上图为例,
表示
的最近邻因特征,
表示
的坐标。简单来讲,通过上述隐函数
可以将2D特征均匀的扩散到2D连续图像域。
Feature unfolding
有了上述定义后,为了丰富每个因特征的信息,作者对
进行unfolding,也就是说采用前述的隐特征的局部近邻对齐进行了信息丰富。该过程可以描述如下:
看公式,可能有点复杂,直接看code就会发现:很简单。

Local ensemble
前述公式2存在一个重要的问题是:连续预测性。特别的,
处的信号预测依赖于其最近邻隐变量
,当
在图像域进行移动时,隐变量的选择可能会出现突然的跳转。这就会导致输出图像的不连续性问题。
为解决上述问题,作者提出了局部集成技术,其实说白了就是:双线性插值思想。将前述公式扩展成如下形式:
其中
表示
与
之间构成的矩形的面积并进行了归一化,这里其实就是双线性插值,不再过多描述了。这种局部集成方式使得输出图像可以自然的连续过渡,而不会导致不连续性。
Cell decoding
作者希望LIIF表示能够对图像进行任意分辨率表示,尽管上述方式可以在连续图像域进行插值输出。但是上述方式并非最优的,因为每个像素的面积信息却被忽略了。为解决该问题,作者提出了cell decoding,见下图。
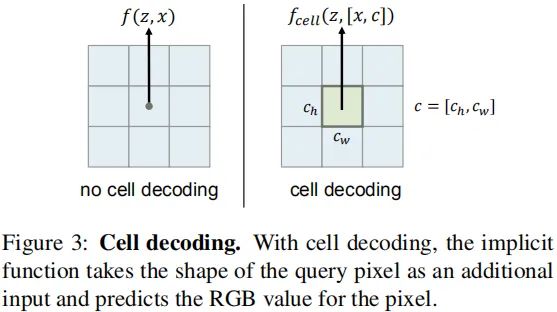
作者进一步扩充前述隐函数为如下形式:
其中,
包含像素的宽高信息。而该隐函数可以更好的描述连续图像,但c趋向于0时,上述表示就代表了像素的面积无限小,也就意味着图像接近真正意义上的连续。
连续图像表达学习
前面介绍了LIIF的定义与构成,那么如何进行训练呢?数据准备与训练过程见下图。
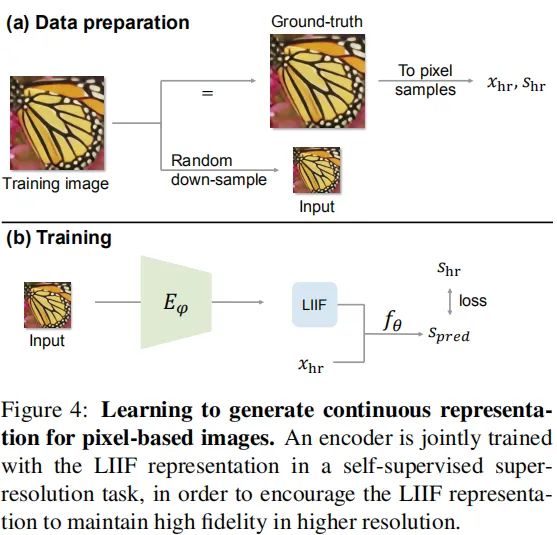
在这里,我们需要训练两个东西:Encoder与LIIF。前者用于将图像转成特征并送入到LIIF。Encoder就简单了,现有超分中的提取特征的方式都可以拿来直接用,比如EDSR、EDN、RCAN等等。作者采用EDSR与RDN进行实验,关于这两个网络的结构信息建议查看对应文章。
作者希望学习的LIIF不仅可以重建输出图像,而且能够在更高分辨率保持图像内容,因此,作者在超分任务上采用自监督方式进行Encoder和LIIF的训练。
实验
在实验方面,作者选用了DIV2K进行模型训练,采用DIV2K-val、Set5等标准数据进行验证。输入图像块大小为
,训练过程中尺度在1-4之间均匀采样,batch=16;损失函数为L1;隐函数
为五层MLP(隐含层维度为256)。初始学习率为1e-4,每个200epoch折半,合计训练1000epoch。
Table1与Table2给出了所提方法与Bicubic、MetaSR在不同倍率的指标对比,可以看到:所提方法取得全面性的超越;在超出训练尺度外,所提方法所取得优势更大。

下图给出了所提方法在30x超分上的效果对比。可以看到:所提方法生成的结果更为自然,无任何伪影问题;而MetaSR则存在严重的伪影问题。

更多消融实验分析建议去查看原文,这里不再描述。
Demo演示
一点点理解
在笔者看来,这篇论文的思路真的非常巧妙。有这么三点巧妙的地方所在:
坐标与特征的组合
当然这个组合不是作者首次提出的,甚至在深度学习大火之前就有了,类似的思想在2010年前后层被用于加速双边滤波;但是将这个idea与图像分辨率的连续性结合起来真的太巧妙了,坐标的连续性直接构成了图像尺寸的连续性。
Cell decoding
在现有的图像超分领域,甚少有去考虑pixel面积问题的,大多采用暴力的堆网络的方式进行端到端训练。像素面积与图像分辨率存在非常紧密的联系,也更能反映图像的信息。做个比喻:假设
图像的像素面积为1,通过最近邻插值放大的图像的像素面积仍然为1,尽管它的面积变大,但其信息增加仍为0。大概是这么个意思吧。
local ensemble
虽然看上去比较简单,但可能这也就是MetaSR效果不如LIIF的关键所在:训练尺度外存在不连续问题。
虽然这篇论文最初的目标在于:图像连续表达学习。但这种连续表达学习真的是非常适合于图像超分这个任务,尤其是在实际应用中的非整数倍率超分。一般学术上的超分往往指的是整数倍超分,但这种超分在实际应用中非常受限(有时需要超分的倍率可能只是1.5倍)。而本文所提出的这种连续图像表达则可以完美的避免上述问题,可以做到真正意义上的“无极放大”,也就是说:连续简便的放大,类似于拍照过程中的放大。
虽然所提方法可以达到“无极放大”的目的与效果,但目前该方案的计算量还是比较大的。如何将其做到更轻量可能会是一个不错的尝试点,如能做到手机端实时那就真的能够......
最后再提一下,这个方法训练还是挺快的。大概只需要5个小时就可以训练出一个效果还不错的模型。目前作者开源了EDSR-LIIF与RDN-LIIF两个模型,感兴趣的同学可以去把玩一番。
传送门
论文链接:
https://arxiv.org/abs/2012.09161
代码链接:
https://github.com/yinboc/liif
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
觉得不错就点亮在看吧

