
机器学习中数据缺失值这样处理才香!
在日常工作中,数据在大多数情况下都有很多缺失数据,每个值缺失的原因可能不同,但缺失的数据会降低模型的预测能力。
数据缺失类型
由于多种原因,可能会出现缺失数据。我们可以将它们分为三个主要组:完全随机丢失、随机丢失、随机未丢失。
完全随机缺失(MCAR)
当数据为 MCAR 时,数据缺失与任何值之间都没有关系,也没有特定的缺失值原因。
随机缺失(MAR)
与 MCAR 不同,这里的数据在特定子集中缺失。当缺失不是随机的,但缺失值与其他观察到的数据之间存在系统关系。
非随机缺失(NMAR)
假设调查的目的是衡量对社交媒体的过度使用,如果过度使用社交媒体的人故意没有填写调查表,那么我们就有一个 NMAR 案例。
检测缺失数据
我们使用 Kaggle 的 Big Mart 销售预测数据,链接:https://www.kaggle.com/datasets/shivan118/big-mart-sales-prediction-datasets
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings # Ignores any warning
warnings.filterwarnings("ignore")
train = pd.read_csv("Train.csv")
mis_val =train.isna().sum()
mis_val_per = train.isna().sum()/len(train)*100
mis_val_table = pd.concat([mis_val, mis_val_per], axis=1)
mis_val_table_ren_columns = mis_val_table.rename(columns = {0 : 'Missing Values', 1 : '% of Total Values'})
mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:,:] != 0].sort_values('% of Total Values', ascending=False).round(1)
mis_val_table_ren_columns
 我们也可以使用 Missingno 库直观地检测缺失值:
我们也可以使用 Missingno 库直观地检测缺失值:
Missingno 是一个简单的 Python 库,它提供了一系列可视化来识别 Pandas 数据框中缺失数据的行为和分布。
要使用这个库,我们需要安装和导入它
pip install missingno
import missingno as msno
msno.bar(train)
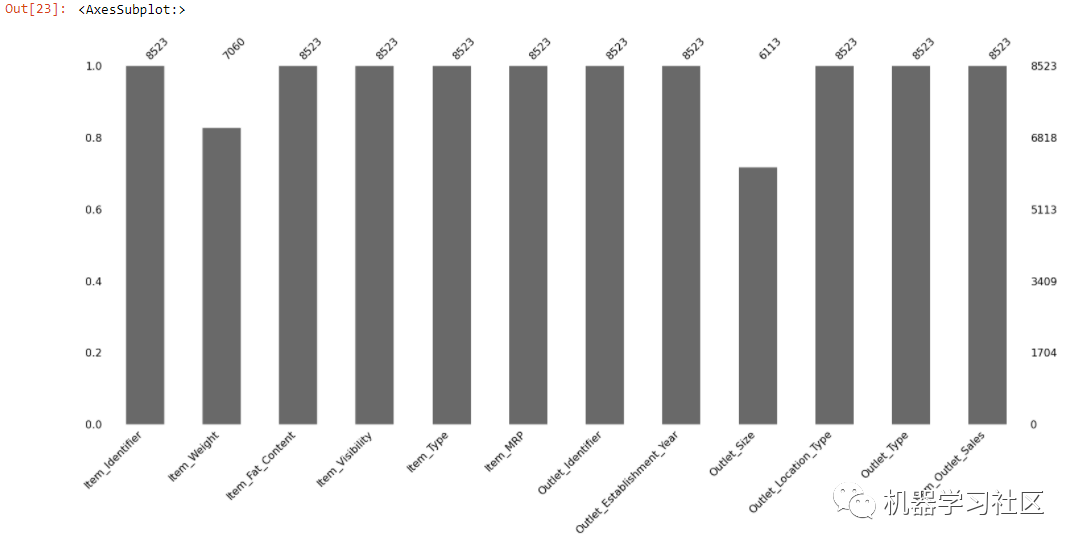 我们可以观察到 Item_Weight、Outlet_Size 列有缺失值。如果它能够找出丢失数据的位置,那就有意义了。
我们可以观察到 Item_Weight、Outlet_Size 列有缺失值。如果它能够找出丢失数据的位置,那就有意义了。
msno.matrix() 是一个空值矩阵,有助于可视化空值观测值的位置。
msno."parent.postMessage({'referent':'.missingno.matrix'}, '*')">matrix(train)
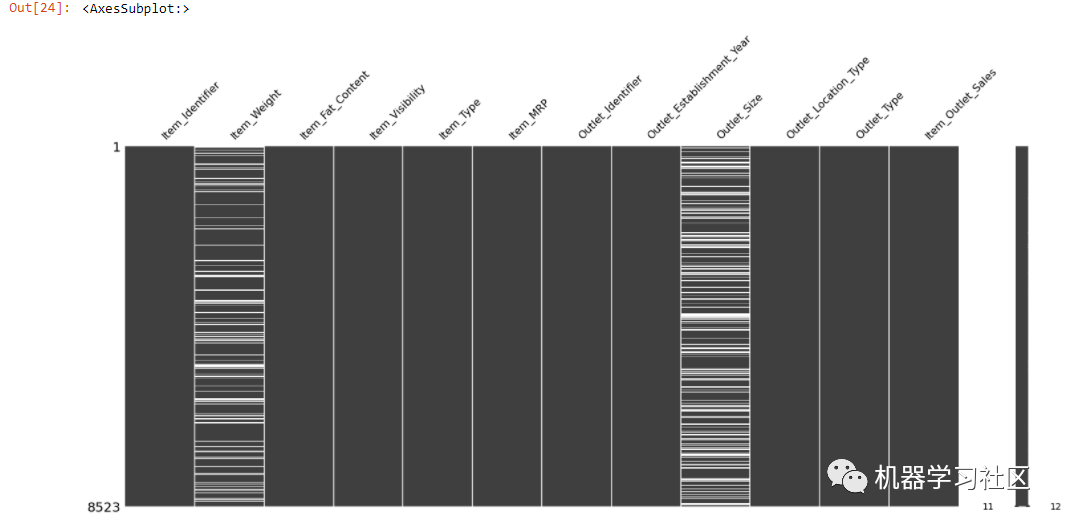 只要有缺失值,该图就会显示为白色。一旦你得到了丢失数据的位置,你就可以很容易地找出丢失数据的类型。
只要有缺失值,该图就会显示为白色。一旦你得到了丢失数据的位置,你就可以很容易地找出丢失数据的类型。
Item_Weight 和 Outlet_Size 列都有很多缺失值。missingno 包还允许我们按选择性列对图表进行排序。让我们按 Item_Weight 列对值进行排序,以检测缺失值中是否存在模式。
sorted = train.sort_values('Item_Weight')
msno.matrix(sorted)
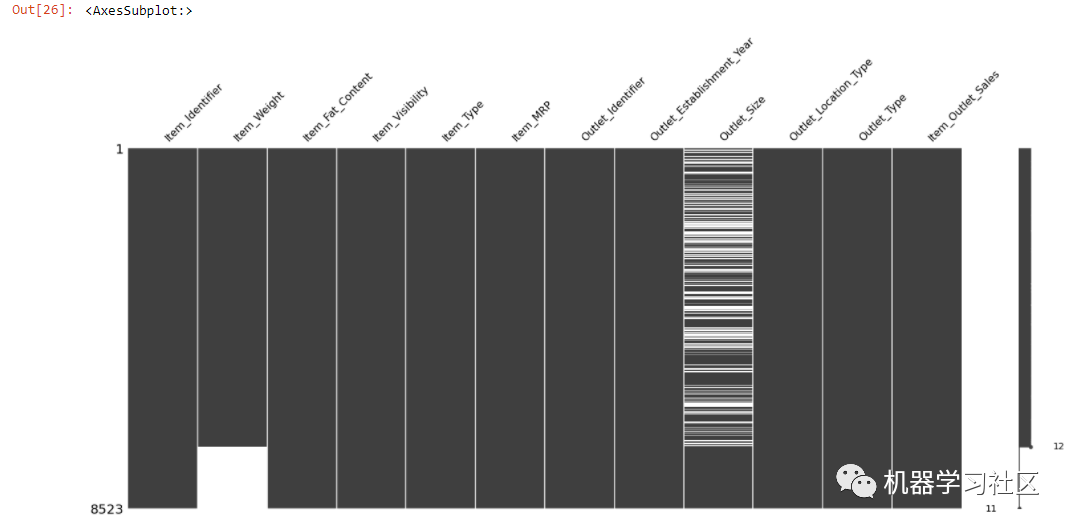 上图显示了 Item_Weight 和 Outlet_Size 之间的关系。
上图显示了 Item_Weight 和 Outlet_Size 之间的关系。
让我们检查一下与观察到的数据是否有任何关系。
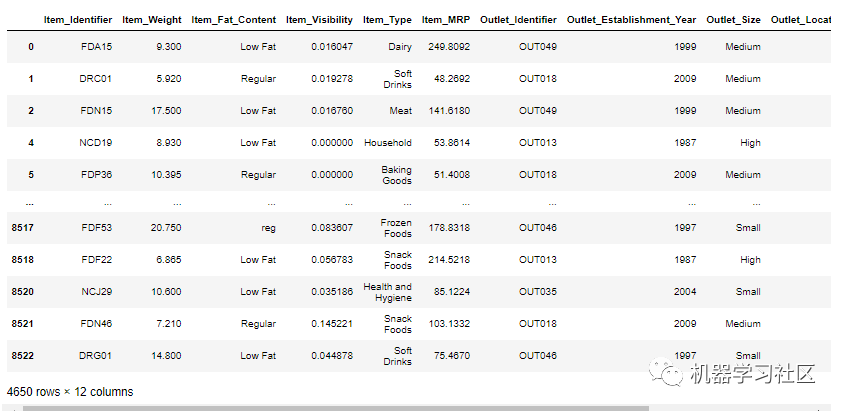
data = train.loc[(train["Outlet_Establishment_Year"] == 1985)]
data
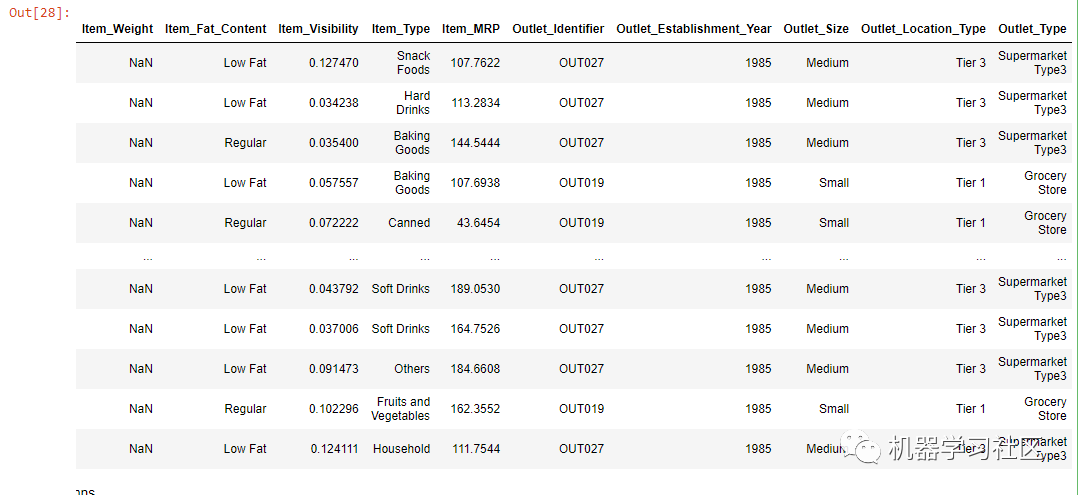
上图显示,Item_Weight 全部为空,属于 1985 年成立年份。
Item_Weight 为空,属于 Tier3 和 Tier1,其中 outlet_size 中、低,包含低脂肪和常规脂肪。这种缺失是一种随机缺失(MAR),因为所有缺失的 Item_Weight 都与一个特定年份有关。
msno.heatmap(train)
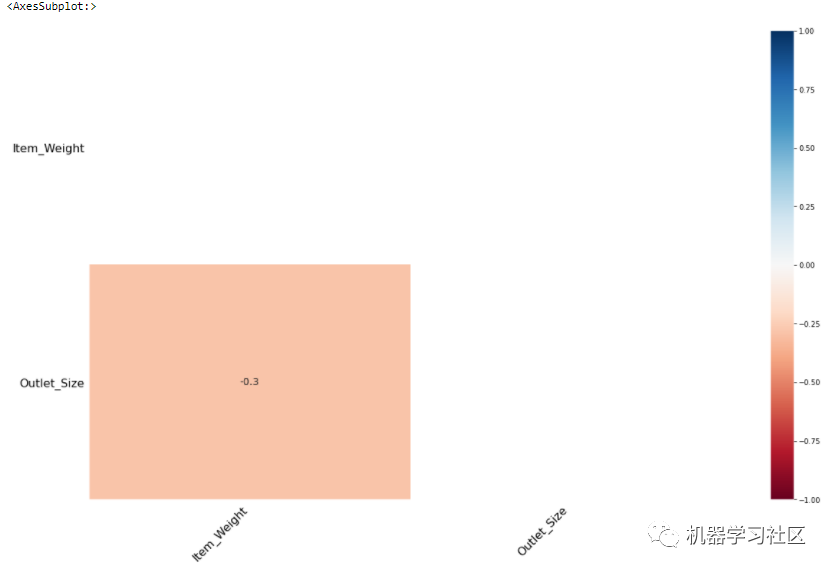 Item_Weight 与 Outlet_Size 呈负相关(-0.3)
Item_Weight 与 Outlet_Size 呈负相关(-0.3)
缺失数据处理
在对缺失值的模式进行分类后,需要对其进行处理。
1、列表删除
当在随机情况下完全丢失时,首选按列表删除。 在 python 中,我们使用 dropna() 函数进行 Listwise 删除。
在 python 中,我们使用 dropna() 函数进行 Listwise 删除。
train_1 = train.copy()
train_1.dropna()
 如果数据集很小,则不推荐按列表删除,并且机器学习模型不会在小数据集上给出好的结果。
如果数据集很小,则不推荐按列表删除,并且机器学习模型不会在小数据集上给出好的结果。
2、成对删除
如果缺失完全随机缺失,即 MCAR,则使用成对删除。 首选成对删除,以减少 Listwise 删除中发生的损失,因为它只删除空观察,而不是整行。
首选成对删除,以减少 Listwise 删除中发生的损失,因为它只删除空观察,而不是整行。
3、删除完整的列
如果一列有很多缺失值,比如超过 80%,并且该特征没有意义,那么我们可以删除整个列。
插补技术:
插补技术用替换值替换缺失值。根据数据的性质及其问题,可以通过多种方式估算缺失值。插补技术可以大致分为以下几类:
1、具有恒定值的插补
正如标题所暗示的那样——它用零或任何常数值替换缺失值。我们将使用 sklearn 中的 SimpleImputer 类。
from sklearn.impute import SimpleImputer
train_constant = train.copy()
#setting strategy to 'constant'
mean_imputer = SimpleImputer(strategy='constant') # imputing using constant value
train_constant.iloc[:,:] = mean_imputer.fit_transform(train_constant)
train_constant.isnull().sum()

2、使用统计插补
语法与使用常量的插补相同,只是 SimpleImputer 策略会改变。它可以是"平均值"或"中位数"或"最频繁"。
在使用任何策略之前,最重要的一步是检查数据类型和特征分布。
sns.distplot(train['Item_Weight'])
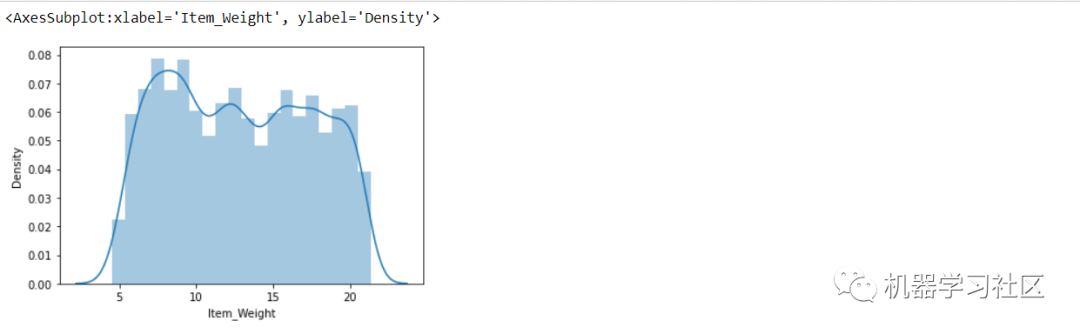 Item_Weight 列同时满足数值类型且没有偏态(遵循高斯分布),在这里,我们可以使用任何策略。
Item_Weight 列同时满足数值类型且没有偏态(遵循高斯分布),在这里,我们可以使用任何策略。
from sklearn.impute import SimpleImputer
train_most_frequent = train.copy()
#setting strategy to 'mean' to impute by the mean
mean_imputer = SimpleImputer(strategy='most_frequent')# strategy can also be mean or median
train_most_frequent.iloc[:,:] = mean_imputer.fit_transform(train_most_frequent)
train_most_frequent.isnull().sum()

3、高级插补技术
与以前的技术不同,高级插补技术采用机器学习算法来插补数据集中的缺失值。以下是有助于估算缺失值的机器学习算法。
KNN 算法通过使用欧几里德距离度量找到具有缺失数据的观测值的最近邻居并根据邻居中的非缺失值来估算缺失数据,从而帮助估算缺失数据。
train_knn = train.copy(deep=True)
from sklearn.impute import KNNImputer
knn_imputer = KNNImputer(n_neighbors=2, weights="uniform")
train_knn['Item_Weight'] = knn_imputer.fit_transform(train_knn[['Item_Weight']])
train_knn['Item_Weight'].isnull().sum()
结论
没有单一的方法来处理缺失值。在应用任何方法之前,有必要了解缺失值的类型,然后检查缺失列的数据类型和偏度,然后决定哪种方法最适合特定问题。
--end-- 扫码即可加我微信
学习交流
老表朋友圈经常有赠书/红包福利活动