
ClickHouse要了解的骚气join操作
1. ClickHouse单机JOIN实现
SELECT <expr_list>FROM <left_table>[GLOBAL] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI|ANY|ASOF] JOIN <right_table>(ON <expr_list>)|(USING <column_list>) ...
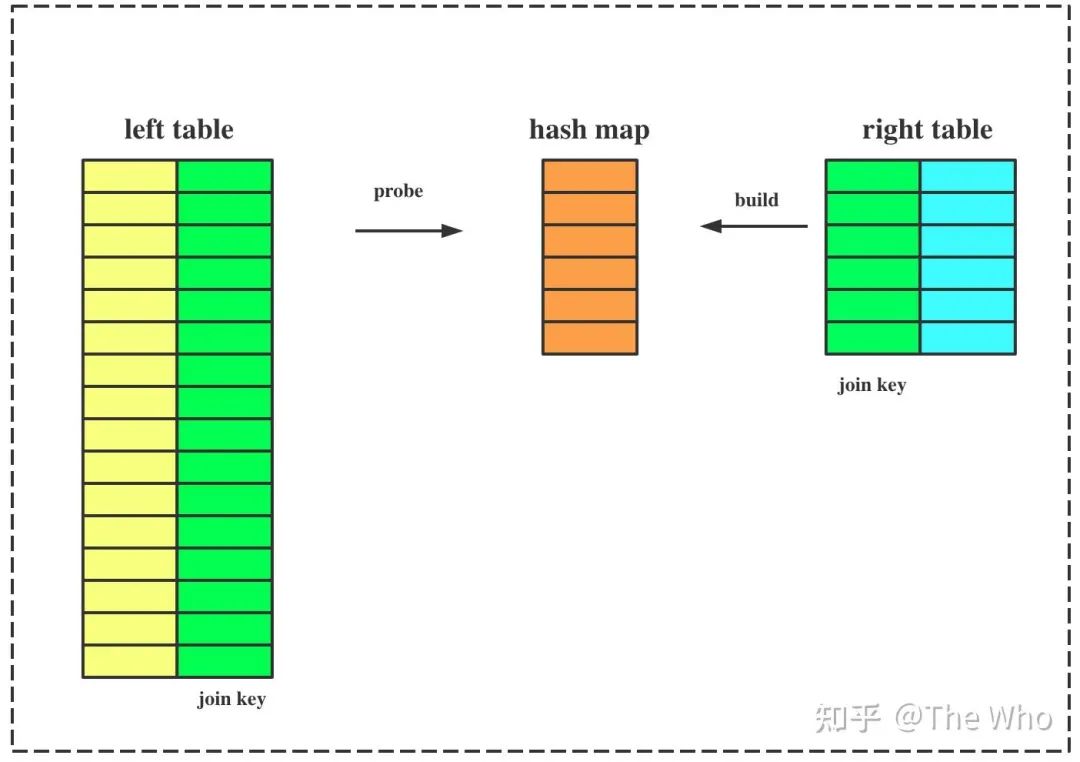
ClickHouse 的 HASH JOIN算法实现比较简单:
从right_table 读取该表全量数据,在内存中构建HASH MAP; 从left_table 分批读取数据,根据JOIN KEY到HASH MAP中进行查找,如果命中,则该数据作为JOIN的输出;
2. ClickHouse分布式JOIN实现
Broadcast JOIN Shuffle Join Colocate JOIN
2.1 普通JOIN实现
a. initiator 将SQL S中左表分布式表替换为对应的本地表,形成S' b. initiator 将a.中的S'分发到集群每个节点 c. 集群节点执行S',并将结果汇总到initiator 节点 d. initiator 节点将结果返回给客户端
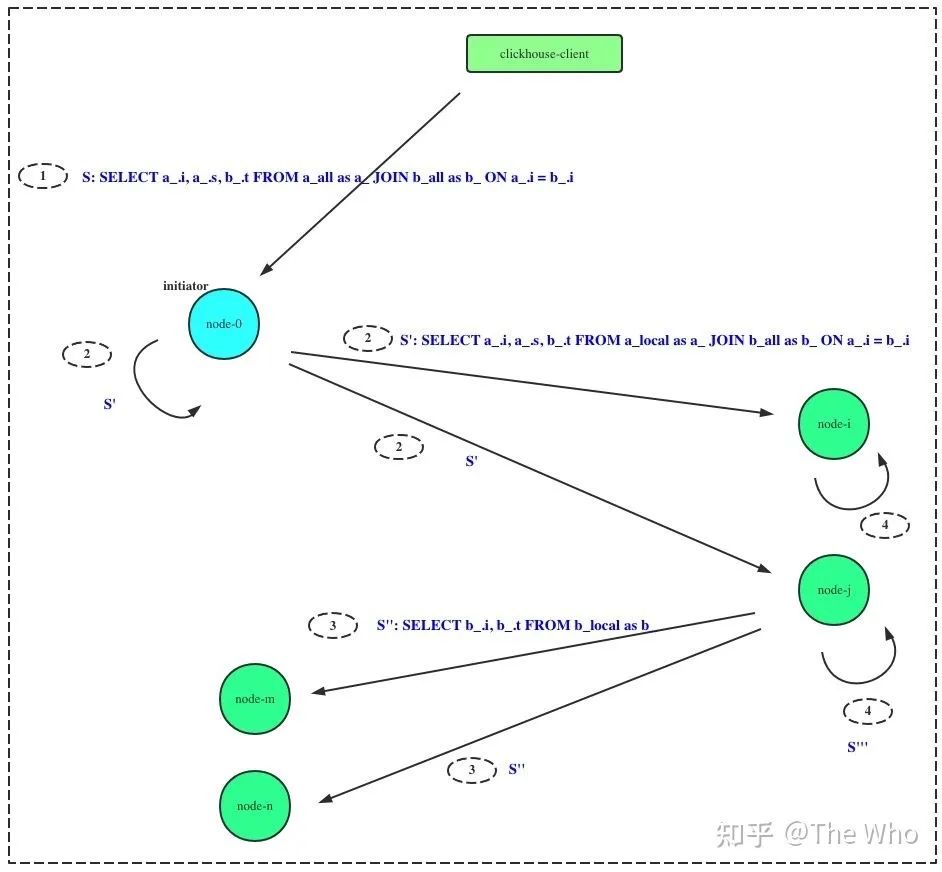
SELECT a_.i, a_.s, b_.t FROM a_all as a_ JOIN b_all AS b_ ON a_.i = b_.i
其中,a_all, b_all为分布式表,对应的本地表名为a_local, b_local。则改SQL在分布式执行的时序为:
1)initiator 收到查询请求 2) initiator 执行分布式查询,本节点和其他节点执行 SELECT a_.i, a_.s, b_.t FROM a_local AS a_ JOIN b_all as b_ ON a_.i = b_.i即左表分布式表更改为本地表名。该SQL在集群范围内并行执行。 3)集群节点收到2)中SQL后,分析出右表时分布式表,则触发一次分布式查询: SELECT b_.i, b_.t FROM b_local AS b_集群各节点并发执行,并合并结果,记为subquery.4)集群节点完成3)中SQL执行后,执行 SELECT a_.i, a_.s, b_.t FROM a_local AS a_ JOIN subquery as b_ ON a_.i = b_.i其中subquery表示2中执行的结果5) 各节点执行完成JOIN计算后,向initiator节点发送数据
2.2 GLOBAL JOIN 实现
a. 若右表为子查询,则initiator完成子查询计算; b. initiator 将右表数据发送给集群其他节点; c. 集群节点将左表本地表与右表数据进行JOIN计算; d. 集群其他节点将结果发回给initiator节点; e. initiator 将结果汇总,发给客户端;
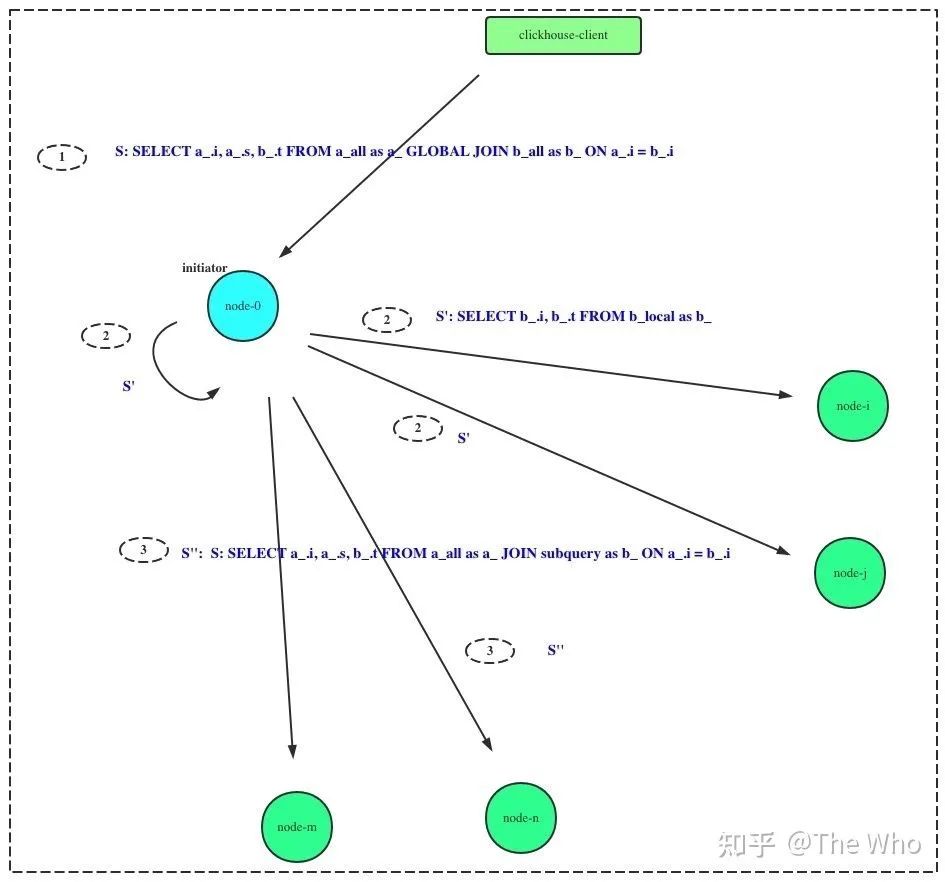
SELECT a_.i, a_.s, b_.t FROM a_all as a_ GLOBAL JOIN b_all AS b_ ON a_.i = b_.i
其中,a_all, b_all为分布式表,对应的本地表名为a_local, b_local。则改SQL在分布式执行的时序为:
1)initiator 收到查询请求 2) initiator 和集群其他节点均执行 SELECT b_.i, b_.t FROM b_local AS b_即左表分布式表更改为本地表名。该SQL在集群范围内并行执行。 汇总结果,记录为subquery。 3)initiator 将2)中subquery发送到集群中其他节点,并触发分布式查询: SELECT a_.i, a_.s, b_.t FROM a_local AS a_ JOIN subquery as b_ ON a_.i = b_.i其中subquery表示2)中执行的结果4) 各节点执行完成JOIN计算后,向initiator节点发送数据
3. 分布式JOIN最佳实践
一、尽量减少JOIN右表数据量
二、利用GLOBAL JOIN 避免查询放大带来性能损失
三、数据预分布实现Colocate JOIN
将涉及JOIN的表按JOIN KEY分片 根据2.2节描述,将JOIN预计中右表换成相应的本地表
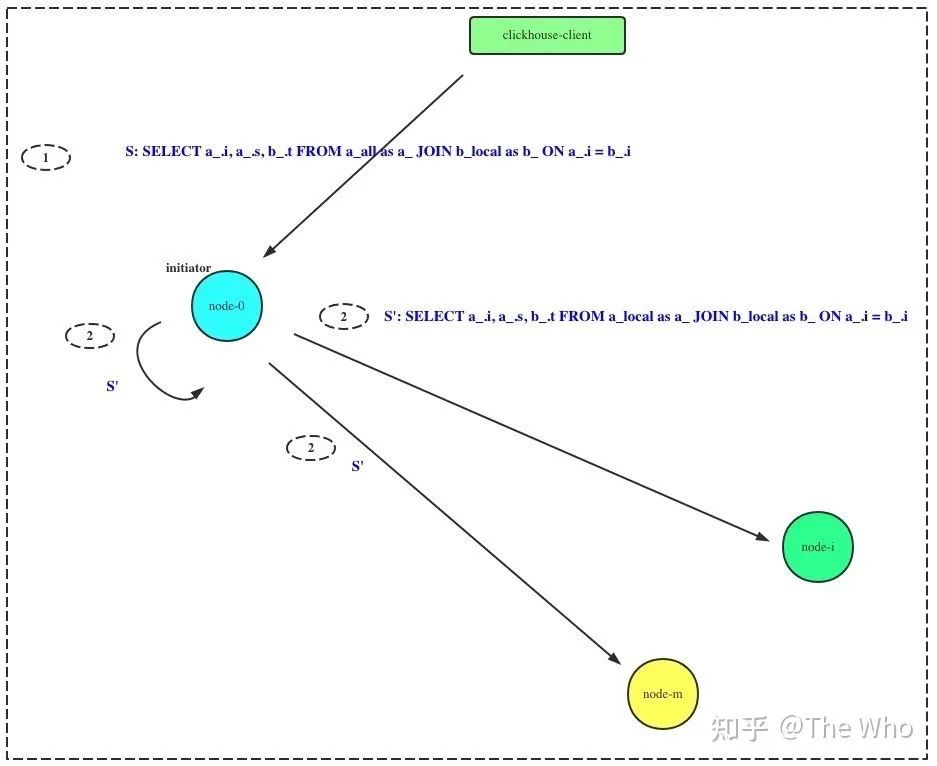
SELECT a_.i, a_.s, b_.t FROM a_all as a_ JOIN b_local AS b_ ON a_.i = b_.i
其中,a_all, b_all为分布式表,对应的本地表名为a_local, b_local。则改SQL在分布式执行的时序为:
1)initiator 收到查询请求 2)initiator 发起一次分布式查询,本机以及其他节点执行: SELECT a_.i, a_.s, b_.t FROM a_local AS a_ JOIN b_local as b_ ON a_.i = b_.i3) 各节点执行完成JOIN计算后,向initiator节点发送数据
4. 总结
减少JOIN右表数据量 避免查询放大带来性能损失 数据预分布实现Colocate JOIN;
评论