
ClickHouse 原理 | ClickHouse 的索引原理

这篇文章来讲一讲对ClickHouse性能影响比较大的主题——索引。
如果带着RDBMS的经验来使用ClickHouse的索引的话,一定会对ClickHouse创建索引的sql感到有些陌生
ALTER TABLE skip_table ADD INDEX vix my_value TYPE set(100) GRANULARITY 2;
这条sql里面包含了很多在RDBMS的索引里没有见过的元素:TYPE,set(100),GRANULARITY。之所以在建索引语句上和RDBMS有如此大的差异,正是因为ClickHouse的索引和RDBMS的索引有着本质的不同。因此两者建索引需要的参数不同,就导致了语法上的不同。
接下来就会讲一讲ClickHouse的索引的原理,并解释下上面几个参数的含义。
基本原理
在开始讲解ClickHouse的索引之前,先来回忆下RDBMS的secondary index是如何实现的。
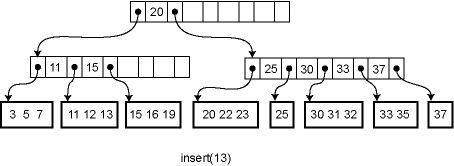
一个B-tree索引的例子
当使用索引进行查询时,最终都会定位到叶子结点的一条或多条记录,因此RDBMS的索引的特点就是——快速找到想要的数据。
说完了RDBMS的索引,再来说ClickHouse的。ClickHouse的索引和RDBMS的索引正好相反,不是找到想要的数据,而是“快速排除不想要的数据”,因此被称为skip index。
举个例子,假设某张表共有1亿条数据,按照默认配置,每8192条记录构成一个granule,则共有12208个granule。如果不使用索引,我们需要读取12208个granule的数据。假设我们通过“某些条件”排除了其中的12200个granule,那么只需要读取8个granule,查询的数据量减到之前的0.07%!(当然了,不可能每个索引都有如此奇效)
那么“某些条件”具体有哪些呢?ClickHouse目前提供了3种索引类型:
minmax set bloomfilter
minmax是最轻量的一种索引类型,就是在索引文件里保存了每个granule的最大值和最小值(针对索引列),然后在查询时,根据查询条件是否在最大值和最小值框定的范围内来确定是否排除granule。说它最轻量是因为索引需要存储的数据量最小的。
set是在索引文件里保存每个granule的所有唯一值。它的优势是不存在假阳性,有就是有,没有就是没有,查询效率很高。但有个缺点是索引的大小不可控,如果数据的唯一值比较多,索引就会变得很大,反而影响查询性能。所以ClickHouse允许用户建索引时,设置索引的max_size,当一个granule的唯一值数量超过max_size时,就不保存这个granule的set。例如set(100)设置max_size是100时,如果一个granule的唯一值超过了100,那么对这个granule就不会保存对应set,则每次查询时都会读取这个granule。
bloomfilter和set的思想类似,只不过用bloomfilter来代替set,因此它的优点是索引大小是固定的(远比set小),不会因数据的分布发生变化,缺点则是bloomfilter固有的假阳性问题。
聊完了ClickHouse的索引类型,再来聊一聊GRANULARITY这个关键字。其实我上面说的索引针对每个granule保存对应的索引信息,如最大最小值,唯一值的集合等,并不准确,确切地说是GRANULARITY 1时的情况。如果设置GRANULARITY 2的话,那么就是“每2个granule保存对应的索引信息”。所以这个配置项控制的还是索引体积与索引效率的取舍。
索引实现
讲完了索引的基本原理,接下来我会循着ClickHouse的读路径(read path)讲一讲ClickHouse如何使用skip index。
ClickHouse和大部分数据库系统一样,使用”SQL解析 -> 生成逻辑执行计划 -> 生成物理执行计划 -> 运行物理执行计划“的方式来处理查询请求。
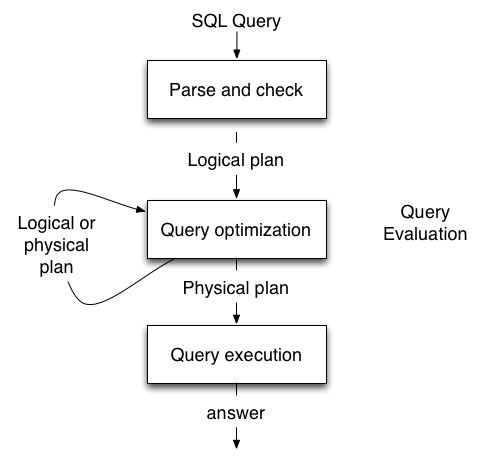
典型的query处理流程
在ClickHouse的源代码中,QueryPlan对应的是逻辑执行计划,QueryPipeline对应的是物理执行计划。而读取数据的代码都在ReadFromMergeTree这个类(是逻辑执行计划的一个节点)里面。
ReadFromMergeTree的工作整体可分为三个步骤:
确定需要查询的part和granule范围 生成物理执行计划中负责读取数据的 MergeTreeSelectProcessor节点执行计划,通过 MergeTreeRangeReader从文件中读取数据
和索引相关的工作都在第一步里面,所以这里着重介绍第一步。
第一步的工作可以继续分为三个步骤:
首先根据查询条件过滤出需要读取的part 然后根据primary key进一步过滤出需要读取的granule 最后再使用skip index进一步缩小granule的读取范围
具体查询索引的代码在MergeTreeDataSelectExecutor类的filterPartsByPrimaryKeyAndSkipIndexes方法里面,我在这里不再赘述。不过值得一提的是,ClickHouse即使做索引过滤时也是并发处理的(并发地读取索引,并发地对granule过滤)。
总结
这篇文章把ClickHouse的skip index原理基本已经讲完了。相比于RDBMS,ClickHouse的索引对数据分布的要求更加苛刻。如果数据比较离散,则无论哪种索引的效果都不是太好,建索引反而拖累性能,所以不能想当然地认为”多加索引一定能提高性能“。
最后总结下本文的知识点:
skip index的作用机制是排除掉不满足条件的数据。 skip index的对象是granule,保存的是每个granule的最大最小值、唯一值集合等。 索引并不一定能够提高查询性能,必须根据数据分布的特点谨慎地建索引。
如果觉得这篇文章对你有所帮助,
请点一下赞或在看,是对我的肯定和支持~