
Hive数据库join操作雷区
基础操作测试
首先准备两张表收入表 hive_join_gaap_test 和 信息表 hive_join_pl_test,表内容如下:
select * from hive_join_pl_test;
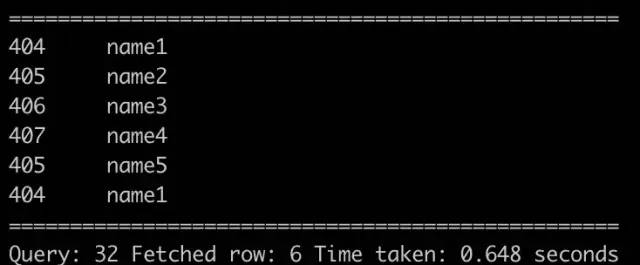
hive_join_pl_testselect * from hive_join_gaap_test;
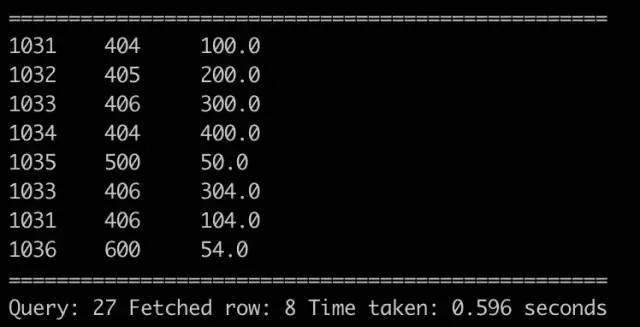
hive_join_gaap_test
1、LEFT OUTER JOIN
select a.clid, a.pid, b.pid, b.plname, a.gaap from hive_join_gaap_test a left outer join hive_join_pl_test b on a.pid = b.pid;
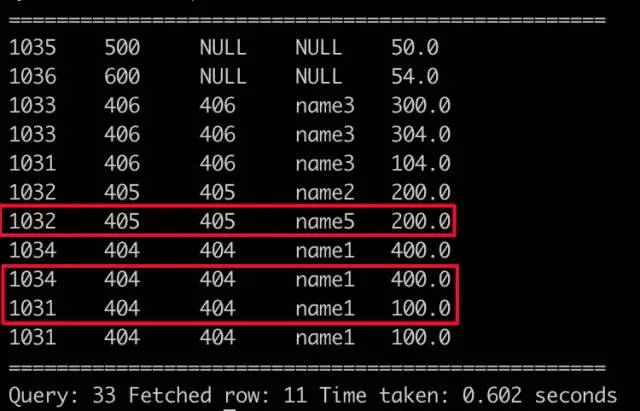
LEFT OUTER JOIN
1)若右表连接key没有重复,行数等于左表;
2)若右表连接key有重复,则左表相关key行数就会 * 重复次数;所以,这里是个巨坑。左连接右表的key不能重复。
3)以左表key为基础,包含左表全部行,匹配不到左表key及其他字段为NULL,这很基础不讲了。
2、RIGHT OUTER JOIN
select a.clid, a.pid, b.pid, b.plname, a.gaap from hive_join_gaap_test a right outer join hive_join_pl_test b on a.pid = b.pid;
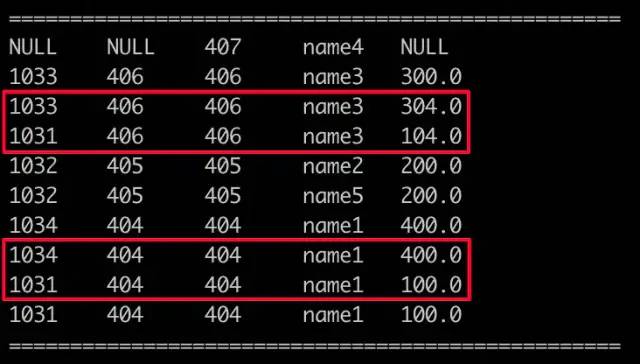
RIGHT OUTER JOIN
注:与左连接正好相反,没什么好讲的。切记,左连接右表的key不能重复,右连接左表的key不能重复,否则基础表相关key行数就会 * 信息表key重复次数。
3、INNER JOIN
select a.clid, a.pid, b.pid, b.plname, a.gaap from hive_join_gaap_test a inner join hive_join_pl_test b on a.pid = b.pid;
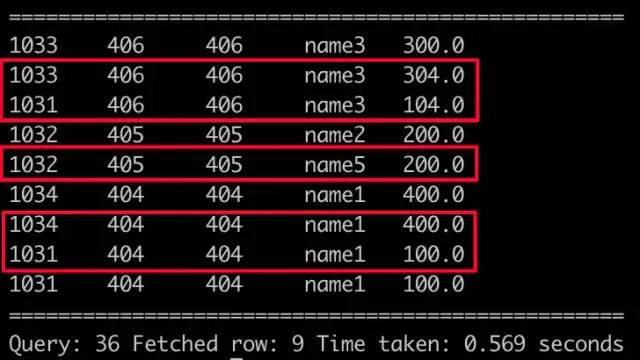
INNER JOIN
1)两表key交集以外的行会被去除,这么什么好讲的,inner join精髓就是取交集,往往用来过滤信息表key以外的收入;
2)两表key取笛卡尔积,若信息表key重复,收入依然会 * 信息表key重复次数。
4、JOIN
select a.clid, a.pid, b.pid, b.plname, a.gaap from hive_join_gaap_test a join hive_join_pl_test b on a.pid = b.pid;
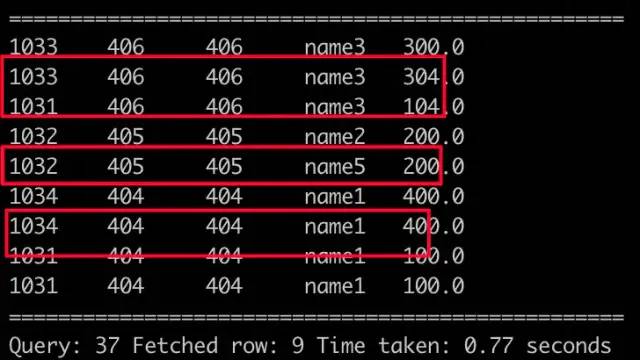
JOIN
注:和 INNER JOIN 一样,不再赘述;Hive 不支持 / LEFT INNER JOIN / RIGHT INNER JOIN.
5、FULL OUTER JOIN
select a.clid, a.pid, b.pid, b.plname, a.gaap from hive_join_gaap_test a full outer join hive_join_pl_test b on a.pid = b.pid;
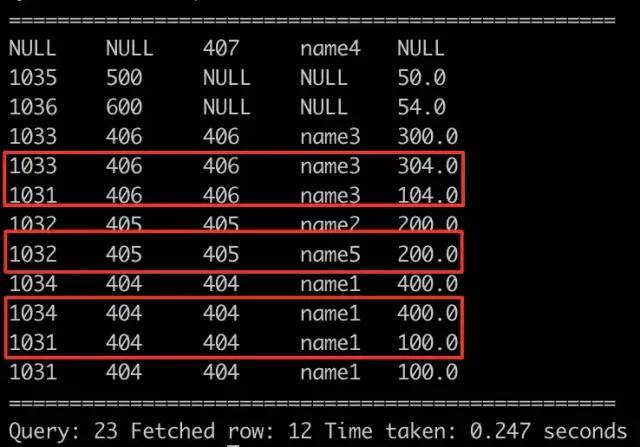
FULL OUTER JOIN
由上可见,连接操作雷区有两个:
1)四种连接,首先要清楚取交集、左集合、右集合、还是并集,清楚哪些行会被去除。
2)若信息表key重复,则根据笛卡尔积,收入表就会乘以相应key重复次数。
作者:朝思暮巷
链接:https://www.jianshu.com/p/677120c48cfc