
七步搞定一个综合案例,掌握pandas进阶用法!
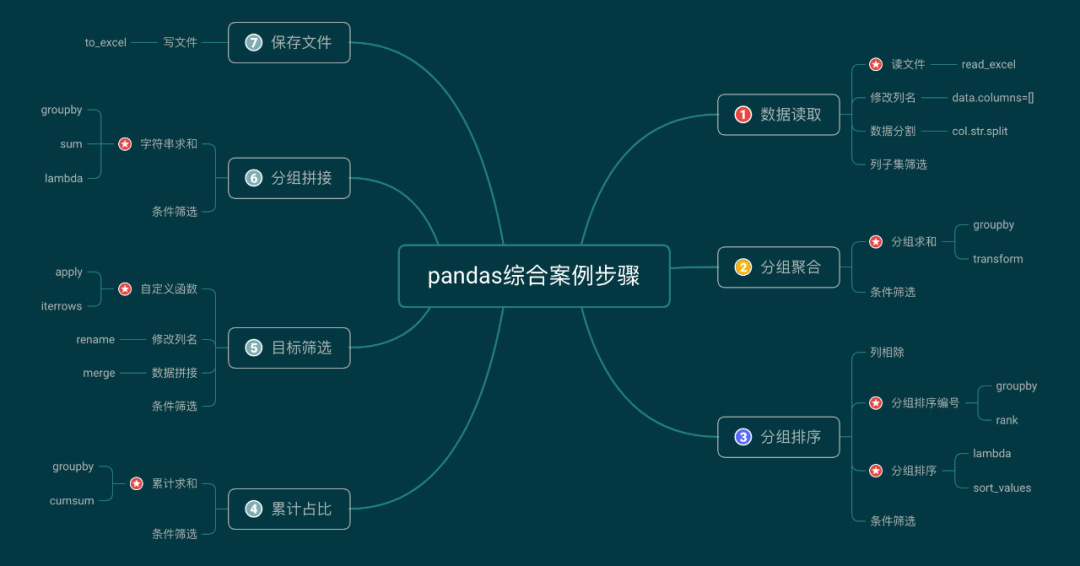
案例引入
现有一批销售数据,如下图所示:
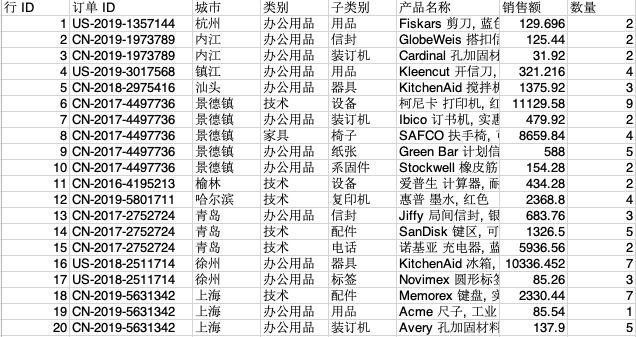
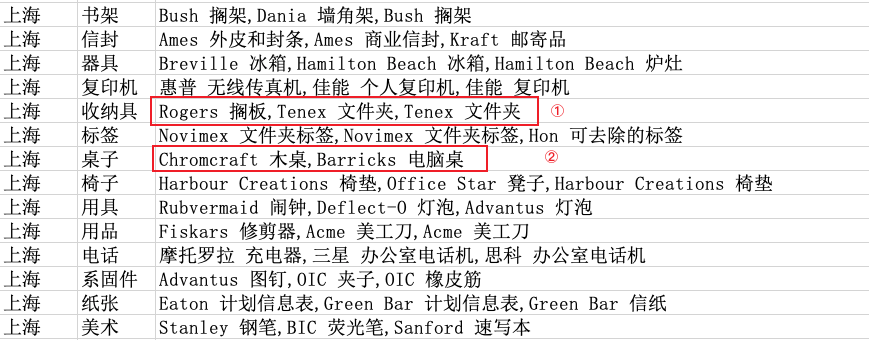
每个城市会销售各种各样的产品,现在想要统计每个城市各个子类别中,累计销售数量筛选出每个城市每个子类别中销量占比top 50%的至多3个产品。如果销量排名前3种的产品未超过50%,则取Top3,如果超过50%,则取刚好大于50%的Top产品。输出的结果为3列,分别为城市,子类别,产品列表(逗号隔开)。如下图所示,①处有3种产品,是【上海-收纳具】销量Top3的产品,其销售数量占比超过50%(或未达50%但已达到Top3,虽然这里后两个产品都是文件夹,但观察原始数据会发现,这是两种不同的文件夹);②处有两件商品,说明【上海-桌子】中木桌,电脑桌销量已超桌子的50%。
案例浅析
虽然在表述上有些绕,但其实需求还是比较明确的。仔细分析,从业务逻辑上,这里需要用到pandas的如下技巧。文件读取-->分组求和-->分组排序-->计算各组累计百分比-->取Top3(需要与50%作比较)-->分组取列表-->文件保存。从具体实现上,可能还有其他处理技巧,如数据拼接(merge)等。下面结合代码进行讲解。
案例解答
0.必要包导入
正式开始前,需要引入相关包,主要是pandas。为过滤异常,这里也引入了warnings包。
import pandas as pdimport warningswarnings.filterwarnings('ignore')
1.数据读取
读文件是数据处理的第一步,pandas提供了read_xxx系列函数,本次用到的是excel格式,因此使用read_excel即可,读取成功后,用head查看数据样例。
data = pd.read_excel('data.xlsx')#读取数据文件data.head()#查看样例
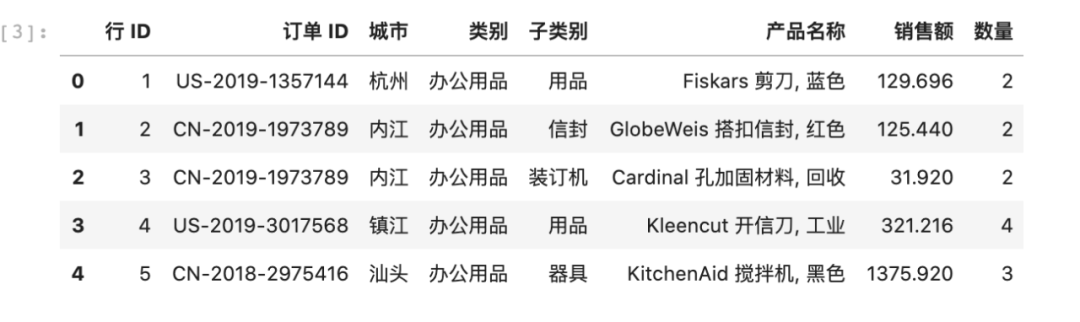
可以看到原始数据的列名为中文格式,为便于后续处理,我们统一改为英文,采用列名直接赋值的方式,如下面代码。
# 直接赋值修改列名data.columns=['id', 'order_id', 'city', 'cate', 'sub_cate', 'prod_name', 'sale_amt', 'amt']data.head()
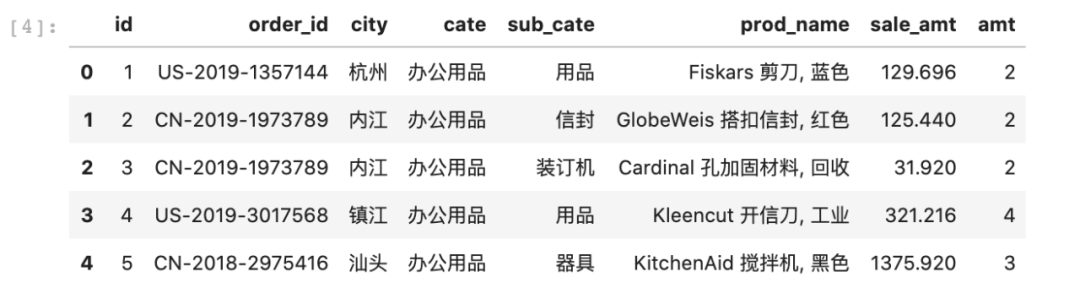
注意到prod_name包含的信息较多,逗号前是英文和中文名称,逗号后是一些补充信息,我们使用split把它分隔开,因为分割出来是两个字段,所以要写成下面的形式,注意最后要加上str。
data['prod_full_name'], data['remark'] = data['prod_name'].str.split(',').strdata.head(10)
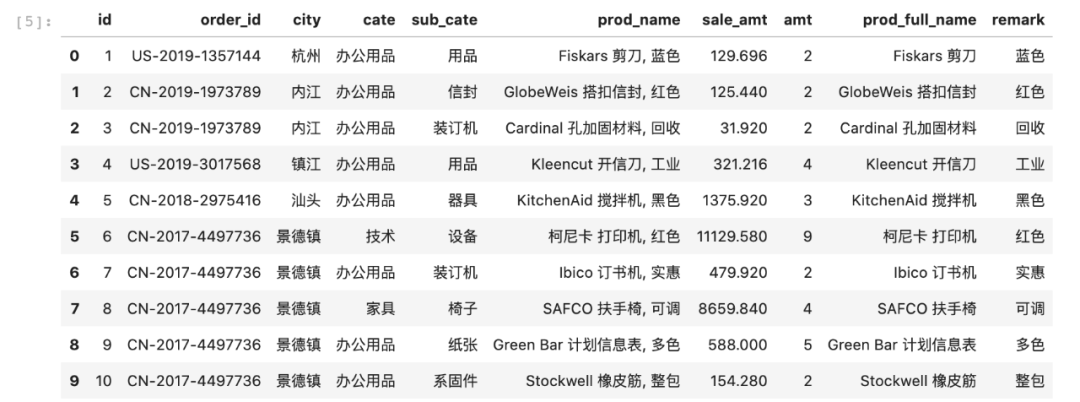
最后,我们可以筛选一些最终会用到的列,用于后面的处理。
#列子集筛选data_new = data[['city', 'sub_cate', 'prod_full_name', 'amt']]data_new.head()

2.分组聚合
按照需求,需要计算每个城市每个子类别下产品的销售总量,因此需要按照city和sub_cate分组,并对amt求和。为计算占比,求得的和还需要和原始数据合在一块作为新的一列。这里有两种方式,可以先分组求和,再与原数据进行merge,也可以使用分组transform一步到位,在前面的文章Pandas tricks 之 transform的用法一文中有详细的讲解。这里采用第二种方式。计算的结果作为新的一列amt_sum添加到原数据上。
#分组求和并用transform与原数据合并amt_sum = data_new.groupby(['city', 'sub_cate'])['amt'].transform('sum')data_new['amt_sum'] = amt_sumdata_new.head(10)
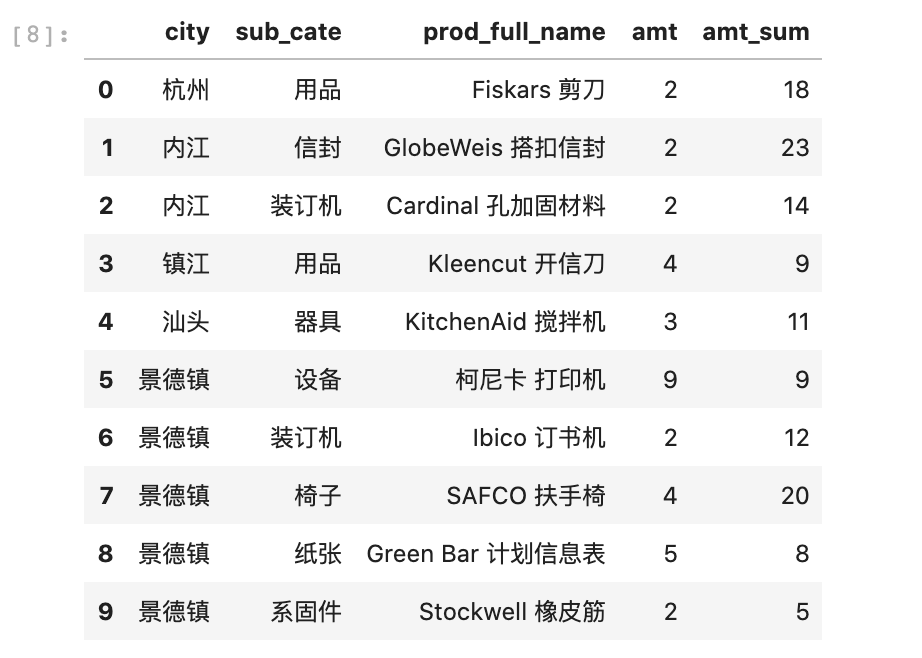
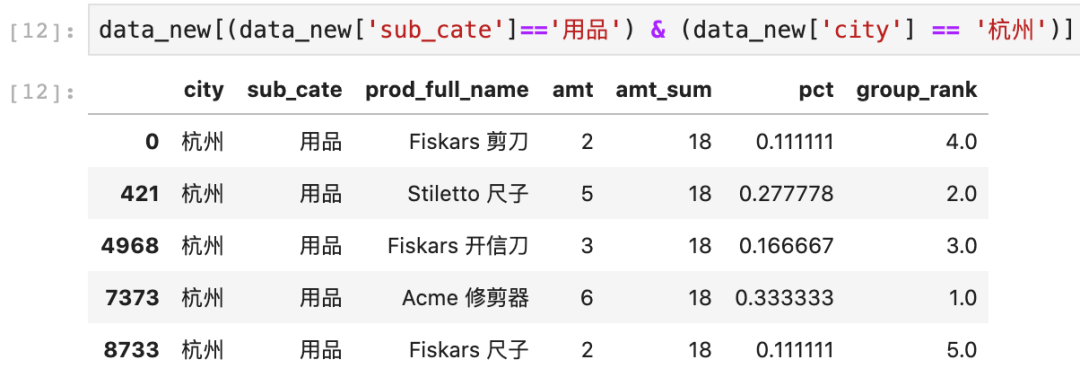
为了验证结果,我们取出city='杭州',sub_cate='用品'的所有样本进行查看,这里用到了pandas多条件筛选数据操作。
#多条件筛选,用&连接data_new[(data_new['sub_cate']=='用品') & (data_new['city'] == '杭州')]

可以看到所有杭州,用品的销售总量为18,和我们的计算结果一致。
3.分组排序
由于我们最终需要取排序Top3(或top50%)的产品,因此需要在各组内先按照销售量降序排列,再计算百分比,最后求累计百分比。也可以先计算每个产品各自的占比,再排序之后求累计百分比。这里也采用第二种方式。
#计算占比:data_new['pct'] = data_new['amt'] / data_new['amt_sum']data_new.head(10)
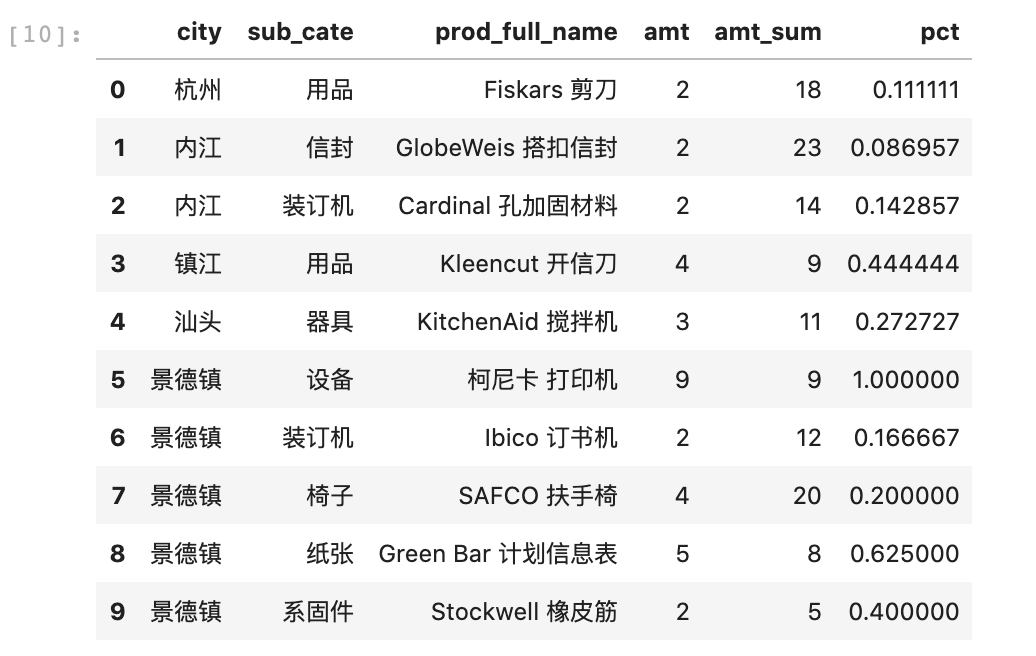
各组内按销售数量(或百分比)做降序。这里的排序有两个层次的含义,第一种是组内实际顺序不变,只给一个排序编号。代码如下所示,method=first是保证序号是连续且唯一的。
data_new['group_rank'] = data_new.groupby(['city', 'sub_cate'])['amt'].rank(method='first', ascending=False)data_new.head(10)
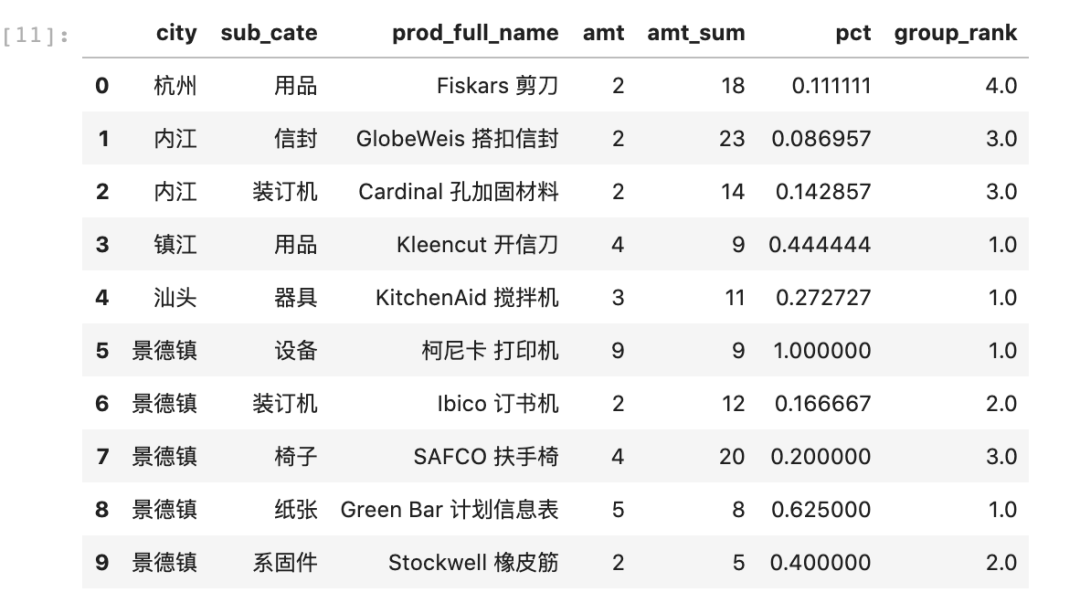
同样来看一下city='杭州',sub_cate='用品'的结果,如下图所示,可以看到已经数量最多的编号为1,数量最少的编号为5,给出的序号并不是严格降序或升序的,说明数据的实际顺序并没有改变。
第二种是排序之后,改变数据的实际顺序。我们使用lambda函数实现:对每个分组按照上一步生成的rank值,升序排列。
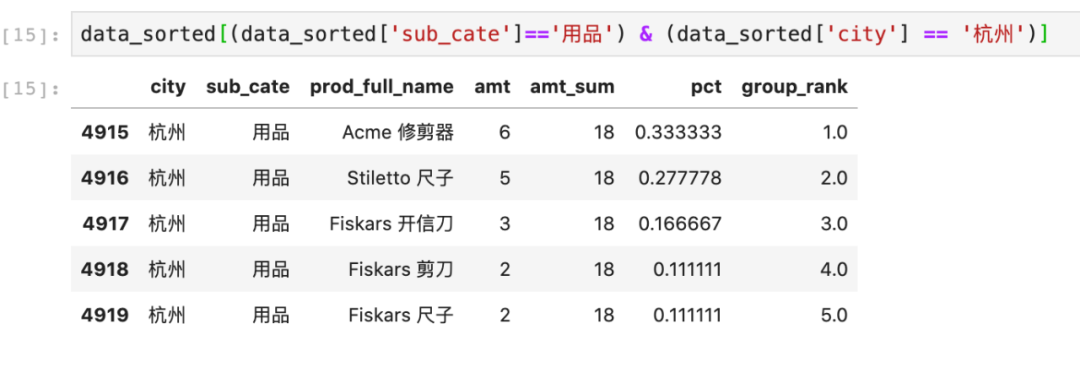
data_sorted = data_new.groupby(['city', 'sub_cate']).apply(lambda x: x.sort_values('group_rank', ascending=True)).reset_index(drop=True)data_sorted.head(10)

结果如上图,这样销量占比最高的产品就会出现在每组的第一行。同样看一下city='杭州',sub_cate='用品'的结果,发现amt,pct是降序的,group_rank是升序的。
4.求累计占比
前一步之所以要改变数据的顺序,就是为了在这里算累计占比时,可以直接累加。我们需要对pct列求累计值,最终用来与目标值50%作比较。注意同样是在每组内进行,需要用cumsum函数求累计和。
#分组并用cumsum计算累计占比data_sorted['cum_pct'] = data_sorted.groupby(['city', 'sub_cate'])['pct'].cumsum()data_sorted.head(10)
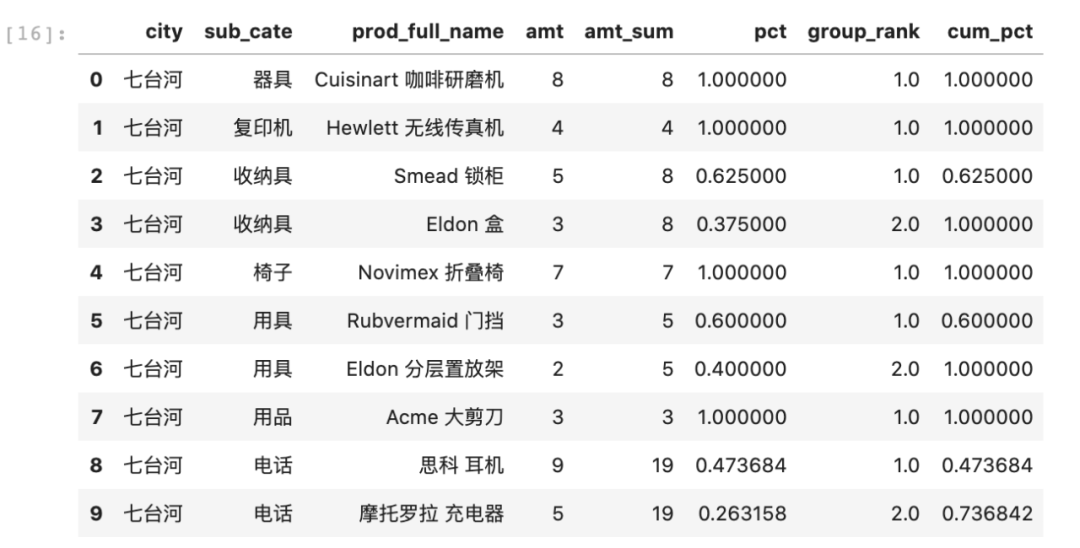
再来看一下city='杭州',sub_cate='用品'的结果。
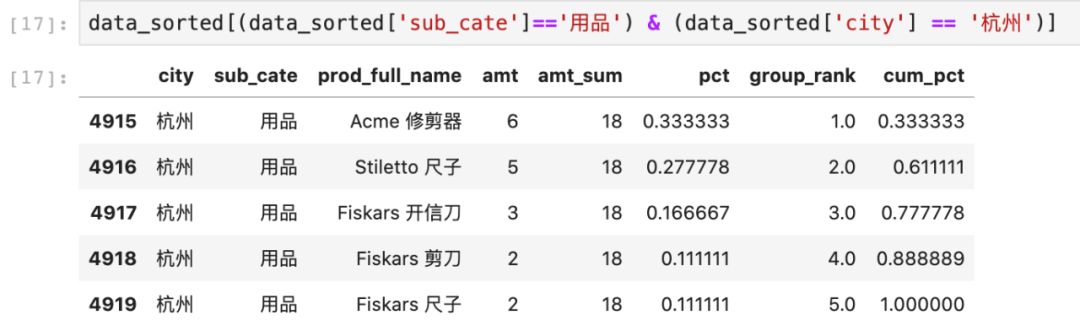
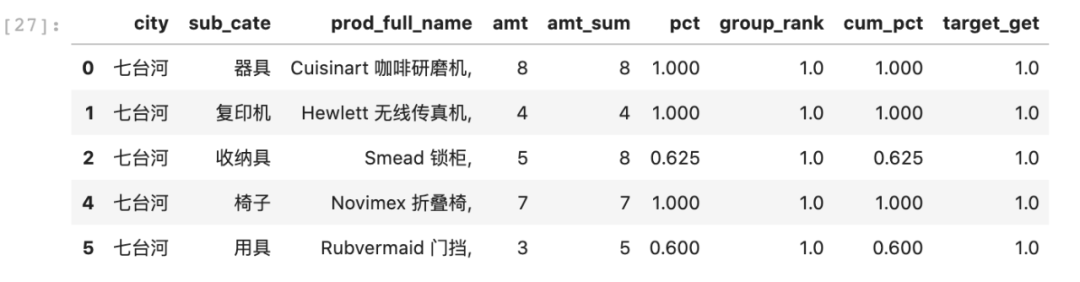
可以看到最后一列cum_pct已经按照pct列计算了累计百分比。其中累计到第二行的时候已经达到了61.1%,超过了50%,因此最终只需取前两行即可。
5.目标筛选
经过了前面的数据准备,在这一步需要在每组内,筛选累计值达到50%的行,且最多三行。这里需要对每组内按行进行遍历,用到了iterrows函数,并判断cum_pct与50%,group_rank与3的关系。我们自定义一个函数来实现。
def get_top_50_pct_rank(group_data, num=3, target=0.5):res = -1for index, grp in group_data.iterrows():if grp['group_rank'] <= num and grp['cum_pct'] >= target:res = grp['group_rank']breakif grp['cum_pct'] < target and grp['group_rank'] == num:res = numbreakreturn res
调用该函数之后,对每个组能得到符合条件的目标group_rank值,如下面代码和图片所示:
data_target_rank = data_sorted.groupby(['city', 'sub_cate']).apply(get_top_50_pct_rank).reset_index()data_target_rank.head()
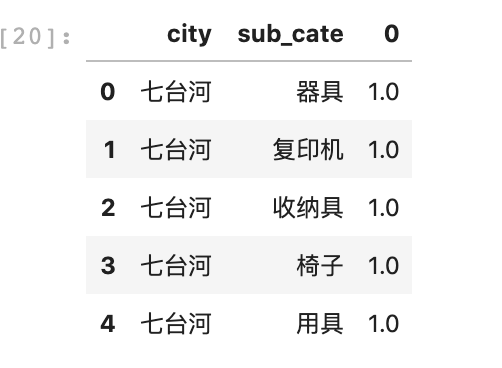
上图第三列就是我们需要的目标group_rank值,注意先要把默认的名字改过来,并将此结果与原始数据做一个合并。在此基础上,就可以将每组内不超过目标group_rank值的行筛选出来。
data_target_rank.rename(columns={0: 'target_get'}, inplace=True)merge_data = pd.merge(data_sorted, data_target_rank,on=['city', 'sub_cate'], how='left')result_data = merge_data[merge_data['group_rank'] <= merge_data['target_get']]result_data.head()
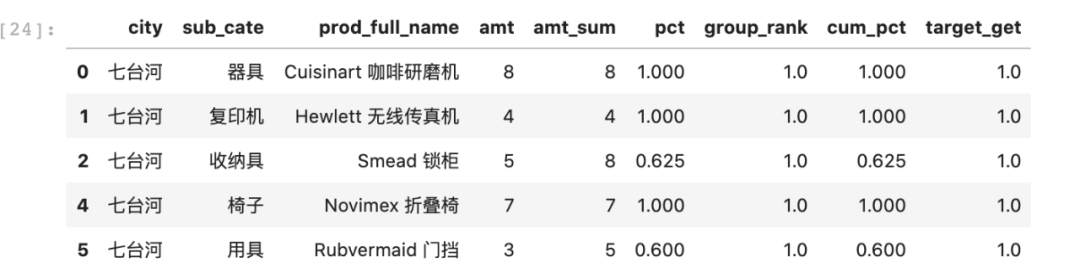
还是看一下city='杭州',sub_cate='用品'的最终结果:
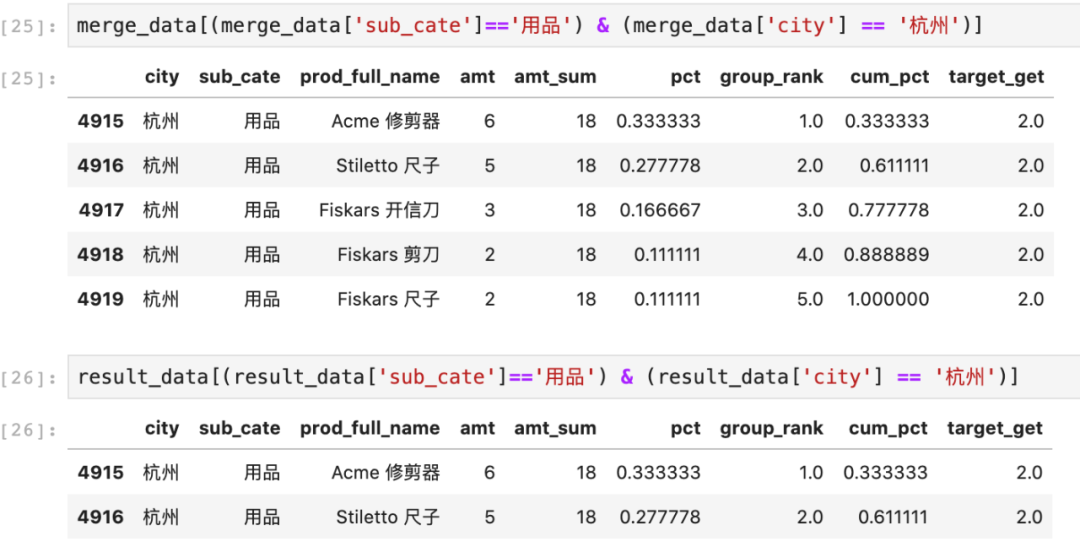
可以看出,该组内最初有5行数据,筛选后剩下两行,且销售量占比超过50%,至此需求已基本实现。
6.分组拼接
在上一步筛选出了目标行,未达到最终目标,还需将每个分组内所有符合条件的产品名称拼接起来,并用逗号隔开。这里采用分组对字符串求和的方式来实现。先在每个产品后面拼上一个逗号,然后“求和”,最后把末尾的逗号去掉。代码如下:
#给每一个产品名称末尾拼接一个逗号result_data['prod_full_name'] = result_data['prod_full_name'].apply(lambda x: x + ',')result_data.head()
#用求和的方式实现对产品名称进行拼接result = result_data.groupby(['city', 'sub_cate'])['prod_full_name'].sum().reset_index()#去掉最末尾的逗号result['prod_full_name'] = result['prod_full_name'].apply(lambda x: x[:-1])
result就是我们想要的目标dataframe。最终的city='杭州',sub_cate='用品'的结果如下。

7.保存文件
将上一步得到的result保存成Excel,即可得到文中开头截图的结果,使用to_excel方法,指定文件名,忽略索引即可。
result.to_excel('result.xlsx', index=None)小结
本文使用pandas,通过7个步骤实现了一个综合案例:筛选出每个城市每个子类别中销量占比top 50%的至多3个产品。涉及到的操作依次有:数据读取,列名修改,字段分割,列子集筛选;分组求和(transform);分组排序(编号),分组排序;累计求和;按行迭代,数据拼接,条件筛选,分组拼接,apply/lambda函数;保存文件等。有一些是核心操作,有一些只是辅助。可以用下图来总结,带有五角星的是核心操作,其余是辅助操作,叶子节点是用到的函数。
