
一个真实问题,搞定三个冷门pandas函数

最近有一个粉丝问过我一个问题,觉得挺有意思,分享给大家。经过简化后大概就是有一个长这样的时间序列数据?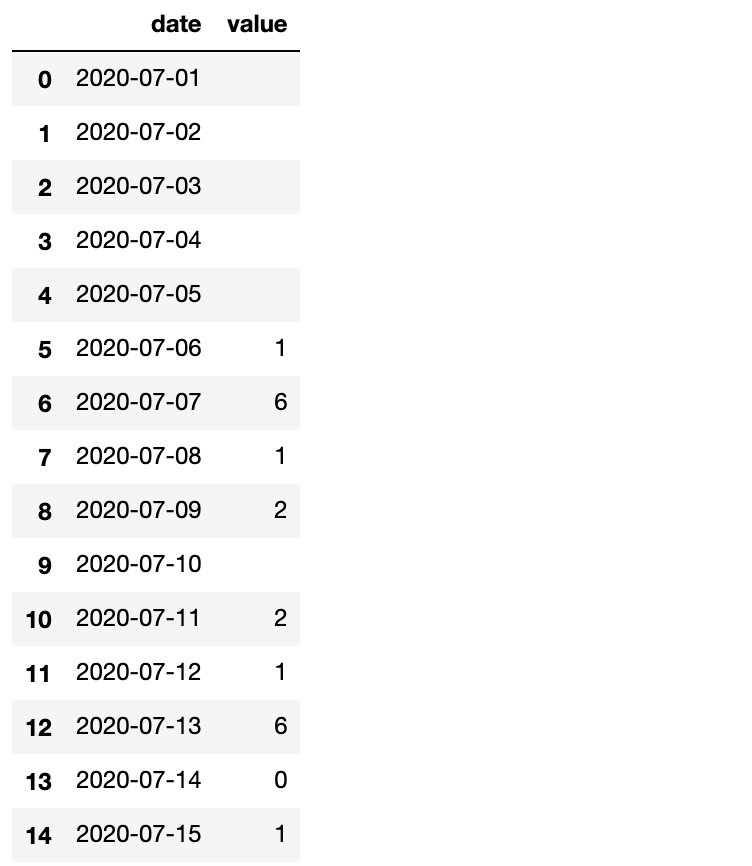
可以看到,一共有15行数据,其中有一些行的value是空值, 现在想在不改变原数据的情况下取出从第一个不是空值的行之后的全部数据?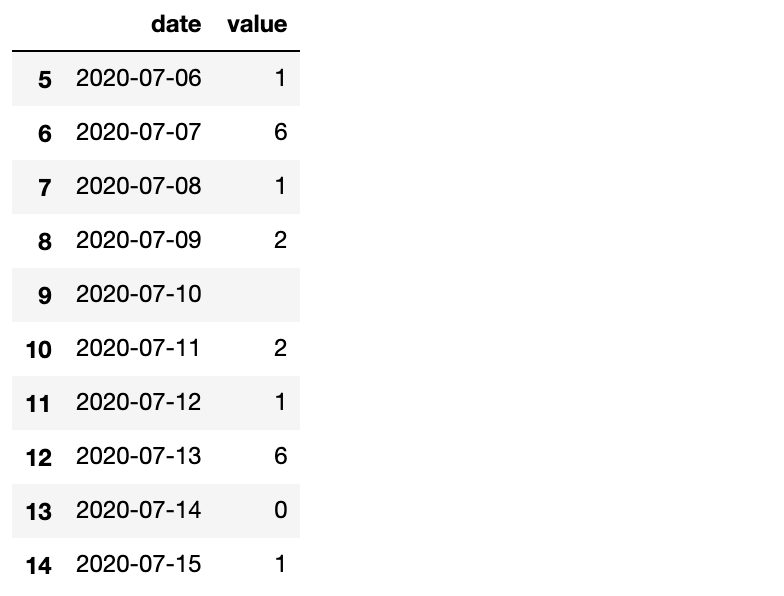
嗯,看上去不是很难,但如果添加一个额外要求:「使用纯pandas函数完成」 这就涉及到了一些不常用的函数,一起来看看。
首先需要构造这样的数据,在Python中我们可以先按照规则生成字符串,然后使用time或datatime模块进行转换,方法很多,但是pandas中如何直接生成呢?这就涉及到第一个函数date_range。
pd.date_range
其实在pandas中生成时间序列数据比其他方法要方便很多,使用.date_range一行代码即可,该函数使用方法为
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
可以通过起止日期来生成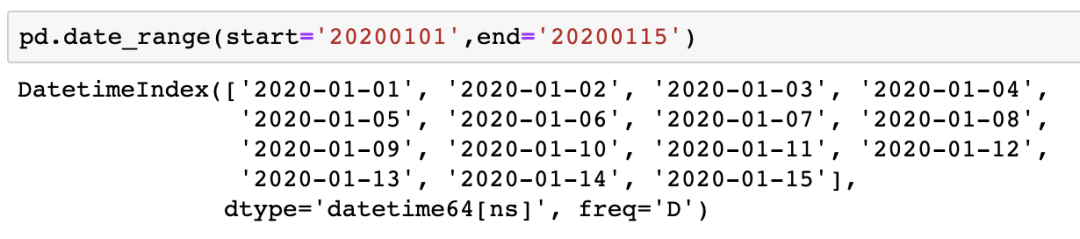 也可以通过开始日期与长度生成
也可以通过开始日期与长度生成 上面的默认间隔是1天,当然是可以自定义,比如修改为5天
上面的默认间隔是1天,当然是可以自定义,比如修改为5天 该方法还支持生成更多的指定形式的时间序列数据,感兴趣的读者可以自行查阅官方文档,现在我们就可以生成示例数据?
该方法还支持生成更多的指定形式的时间序列数据,感兴趣的读者可以自行查阅官方文档,现在我们就可以生成示例数据?
df = pd.DataFrame(
{ 'date': [i for i in pd.date_range('20200701','20200715')],
'value': ['','','','','',1,6,1,2,'',2,1,6,0,1]}
)
接下来我的思路是
判断value列的每个值是否为空值,返回 Ture/False找到第一个为False的索引,取后面全部的数据
为了只用pandas实现这个思路,用到了两个不常见的函数,让我们慢慢说。
pandas.Series.ne
ne函数可以比较两个Series,常用于缺失值填充,下面是一个例子

除了可以比较两个Series之外,对于我们的问题,它可以比较元素:返回True如果这个值不是你指定的值,听上去很绕,我们看代码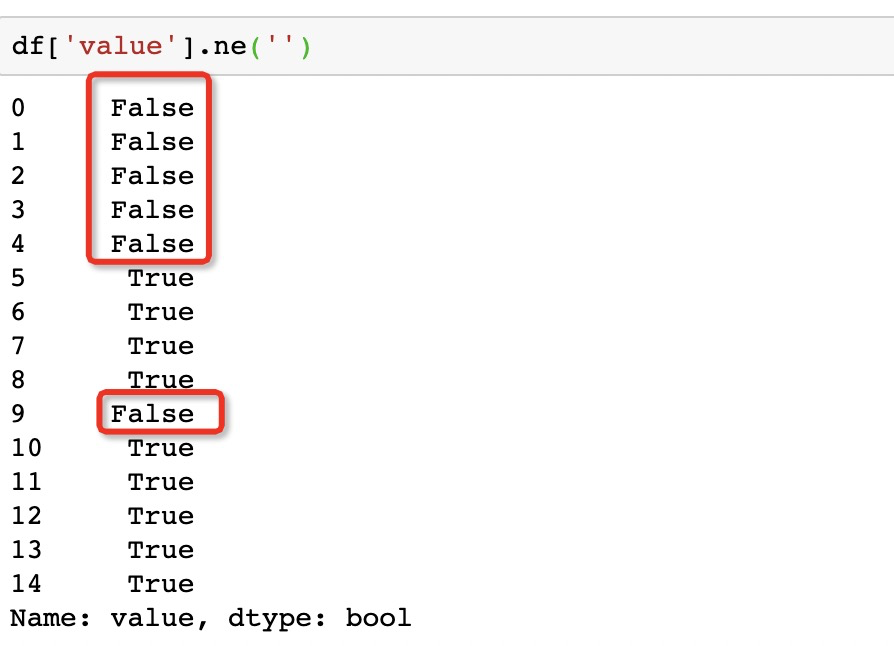
可以看到,所有空值都被标记为False,接下来要做的就是找到第一个True元素的索引,并取出之后的全部数据。
pandas.DataFrame.idxmax
如何在pandas中直接定位一组数据中最大/最小值的位置?可以使用idxmax/idxmin,这个函数不难,直接看一个简单的例子 它可以返回最大值/最小值第一次出现的位置索引!刚好可以满足我们的要求,现在就可以将
它可以返回最大值/最小值第一次出现的位置索引!刚好可以满足我们的要求,现在就可以将idxmax与之前的ne函数结合起来实现我们需求
df['value'].ne('').idxmax()
# 5
返回的索引值是5,最后就可以使用loc函数一行代码实现我们的需求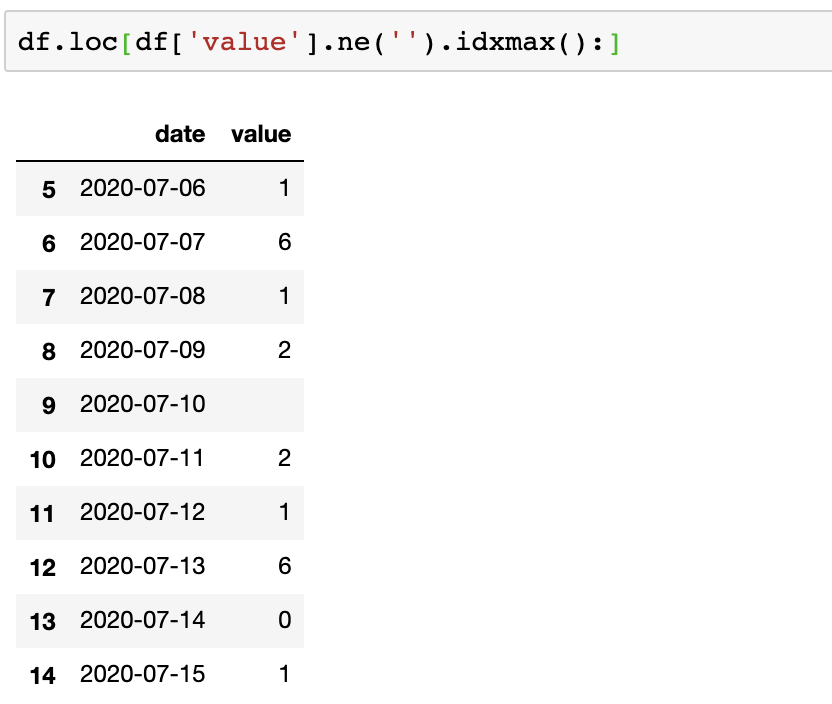
其实这个问题还有很多其他的办法,比如可以先筛选出所有True的索引,然后使用.first_valid_index()找到第一个True,最后也可以不用loc直接df[df['value'].ne('')]实现。
但我还希望你能掌握上面三个函数并灵活运用,如果有更好的思路可以在评论区留言。
-END-
文末推荐一本数据分析相关的书:Python数据分析与可视化(本书以零基础为起点,系统地介绍了Python在数据处理与可视化分析方面的应用。全书共分3篇12章内容。第1篇:基础篇。第2篇:应用篇。第3篇:实战篇 综合案例!本书既适合希望从事Python数据处理与可视化的用户学习,也适合广大职业院校作为相关专业教材,还可作为社会培训班的参考用书)现在京东和当当都有优惠活动,点击下方图片查看详情!
